

1 概述
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop 之上的 SQL 查询接口及多维分
析(OLAP)能力以支持超大规模数据,最初由 eBay Inc. 开发并贡献至开源社区。
1.1 Kylin 是什么
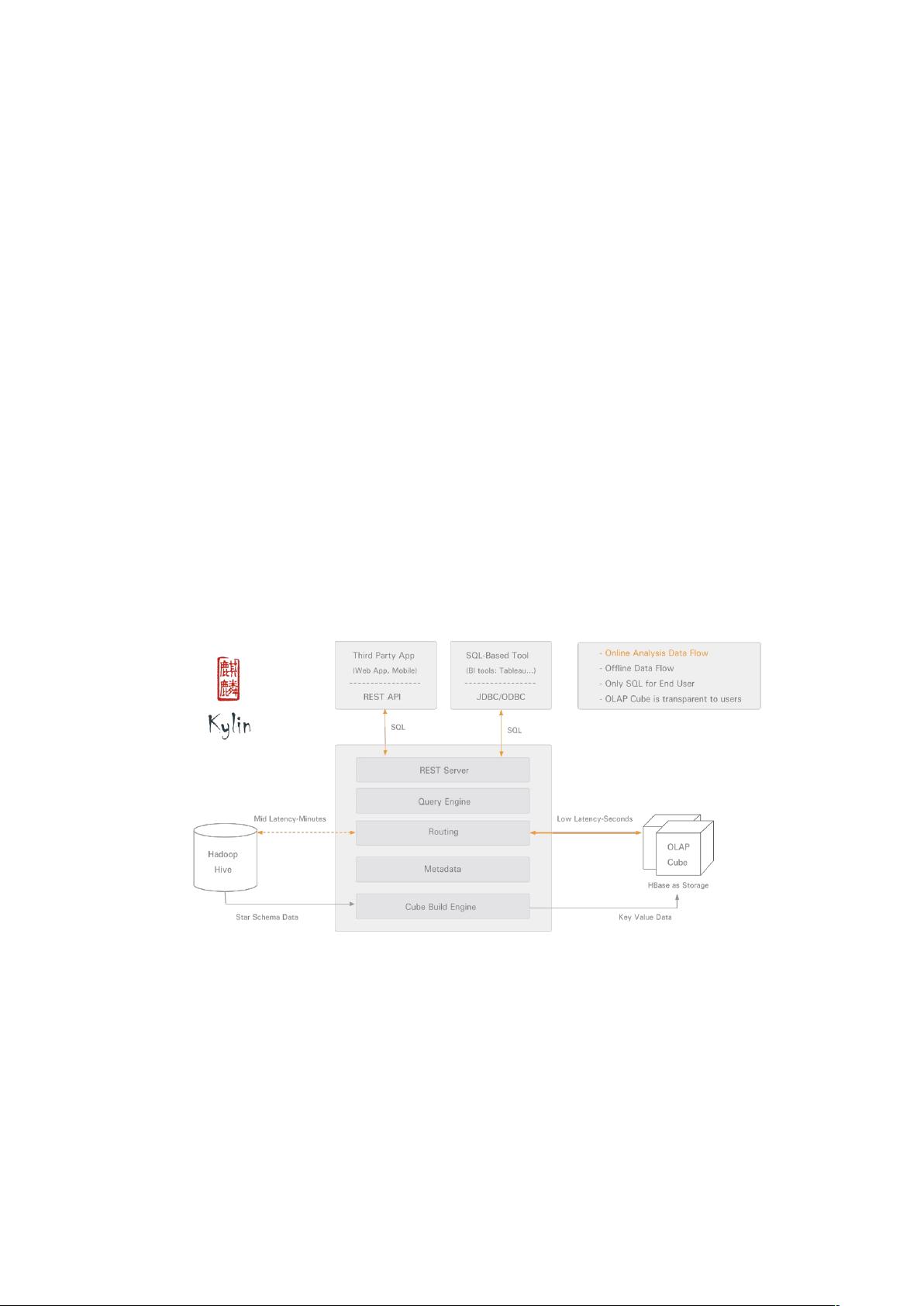
可扩展超快 OLAP 引擎:
Kylin 是为减少在 Hadoop 上百亿规模数据查询延迟而设计
Hadoop ANSI SQL 接口:
Kylin 为 Hadoop 提供标准 SQL 支持大部分查询功能
交互式查询能力:
通过 Kylin,用户可以与 Hadoop 数据进行亚秒级交互,在同样的数据集上提供比 Hive 更
好的性能
多维立方体(MOLAP Cube):
用户能够在 Kylin 里为百亿以上数据集定义数据模型并构建立方体
与 BI 工具无缝整合:
Kylin 提供与 BI 工具,如 Tableau,的整合能力,即将提供对其他工具的整合

剩余10页未读,继续阅读

u010414921
- 粉丝: 0
- 资源: 52
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论1