Apache Kafka与MapR Streams推动实时流处理新设计
《流式架构:使用Apache Kafka和MapR Streams的新设计》是由Ted Dunning和Ellen Friedman共同撰写的一本专业书籍,专注于探索和讲解流处理技术在大数据领域的最新发展。该书深入剖析了如何在Hadoop和Spark的背景下,利用Apache Kafka作为关键的分布式流处理平台,以及MapR Streams在其中的作用。作者们结合实践经验和理论知识,为开发人员、数据分析师和系统管理员提供了全面的指导,帮助他们理解和构建高效、可扩展的实时数据处理系统。
书中内容涵盖了以下几个重要知识点:
1. **流式架构基础**:首先,读者将学习到流处理的基本概念,包括事件驱动的数据处理模型、实时数据流的处理需求以及与批处理的区别。流式架构的核心在于处理连续、高吞吐量的数据流,而不是一次性的批量数据。
2. **Apache Kafka**:作为主角,Apache Kafka被详细介绍为一个强大的分布式消息队列系统,它提供了一种可靠、高吞吐量的实时数据流处理平台。书中会涉及Kafka的设计原则、架构、分区和复制策略,以及如何配置和管理Kafka集群。
3. **MapR Streams**:MapR Streams是MapR公司为Kafka提供的增强版本,它在Kafka的基础上增强了实时分析和查询功能。读者可以了解到MapR Streams如何简化流处理任务的开发,并支持SQL查询,以及其与MapR Data Platform的集成。
4. **Hadoop和Spark的集成**:书中还会探讨如何在Hadoop生态系统中整合Apache Kafka和MapR Streams,例如通过YARN或Spark Streaming进行数据处理。此外,如何利用Hadoop的存储能力来持久化流数据,以及如何优化性能和容错性也会被讨论。
5. **实战案例和最佳实践**:书中不仅提供理论知识,还包含丰富的实际应用案例和最佳实践,帮助读者掌握如何设计和实现复杂的流处理应用,如日志分析、实时监控和实时决策支持系统。
6. **认证与培训**:对于想要进一步提升技能的读者,书中还提到MapR提供的在线培训课程,旨在帮助读者成为大数据领域的专家,并提供免费的Hadoop培训资源。
7. **版权信息**:最后,本书版权信息强调所有权利归作者所有,且强调读者可以根据教育、商业或销售推广目的购买,并指出O'Reilly Media的联系方式以获取更多信息。
《流式架构:使用Apache Kafka和MapR Streams的新设计》是一本适合从事大数据和实时分析领域专业人士的参考资料,深入讲解了现代流式计算架构的关键技术和工具,有助于读者在实际工作中构建和优化高性能的数据流处理系统。
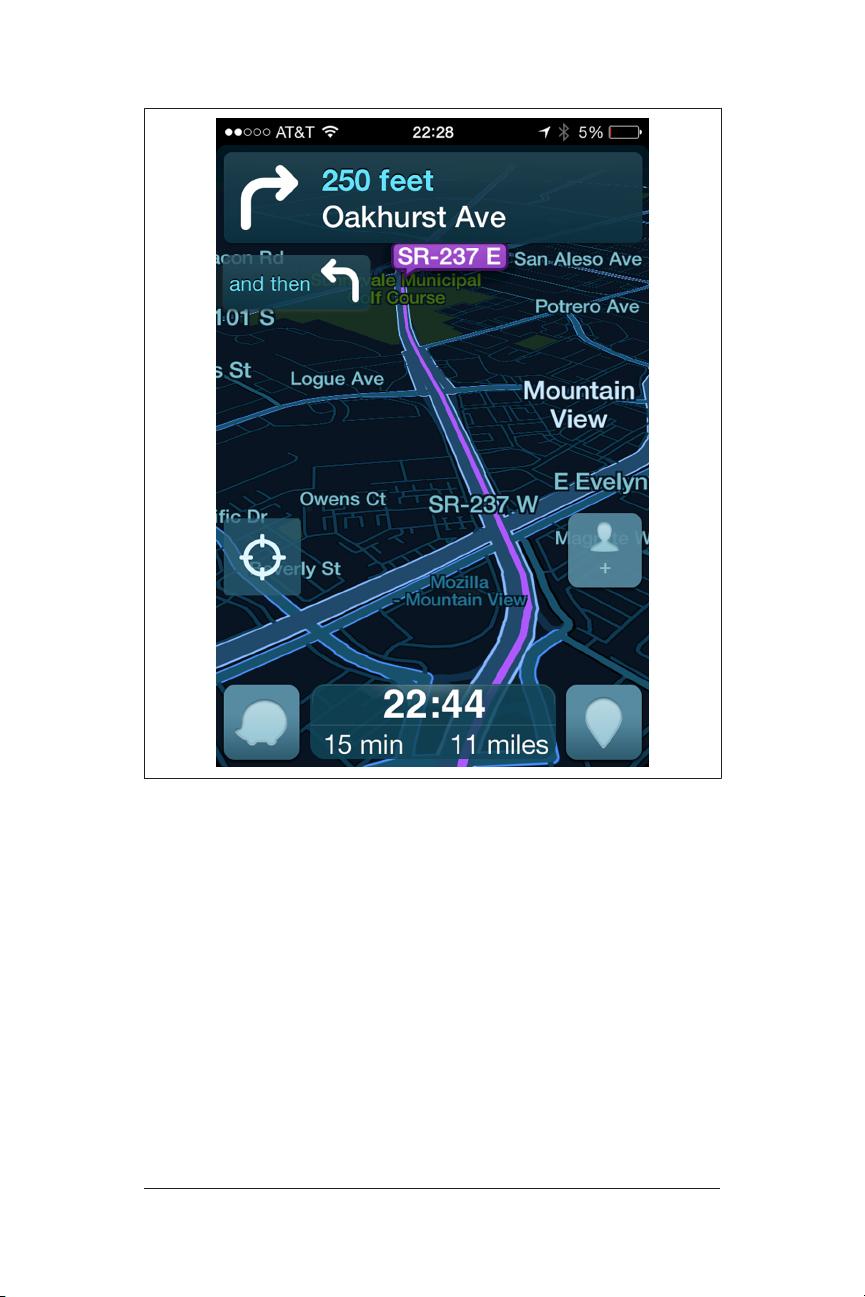
Figure 1-2. Display of a smartphone application known as Waze. In
addition to providing point-to-point directions, it also adds value by
supplying real-time
trac information shared by millions of drivers.
Knowing that there is a slow-down caused by an accident on a par‐
ticular freeway during the morning commute is useful to a driver
while the incident and its effect on traffic are happening. Knowing
about this an hour after the event or at the end of the day, in con‐
trast, has much less value, except perhaps as a way to review the his‐
tory of traffic patterns. But these after-the-fact insights do little to
help the morning commuter get to work faster. Waze is just one
straightforward example of the time-value of information: the value
of that particular knowledge decreases quickly with elapsed time.
Being able to process streaming data via a 4G network and deliver
6 | Chapter 1: Why Stream?




剩余116页未读,继续阅读
153 浏览量
165 浏览量
125 浏览量
179 浏览量
138 浏览量
114 浏览量
192 浏览量
137 浏览量
156 浏览量

Scape1989
- 粉丝: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机常用英语单词速查宝典
- Apache HTTP Server 2.2.19: 构建百万访问量级Web服务器
- 开源国际象棋评级系统:实现USCF评级算法
- 官方最新2012-08-01 Keil C8051F仿真调试驱动程序发布
- 乐视直播平台的TVlist6功能解析
- GDXPunk:Java游戏引擎,融合libGDX与Flashpunk精髓
- Django搭建简易博客教程与实例分析
- DDRManiak开源克隆版:FlashLite手机上的舞蹈游戏
- 深入探讨Spring 2.5及Java语句学习笔记
- Java版俄罗斯方块豪华学习教程
- MFC应用实现:鼠标绘制圆形与椭圆形教程
- 海美迪HiTV3.0电视直播软件功能介绍
- Mogwai图形工具:3D场景编辑中的Gizmo实用程序
- 双峰山旅游景点导游系统设计方案研究
- CPSokoban开源推箱子游戏发布1.0版本
- 哈夫曼树应用教程:源代码与示例文件下载
