Linux内核链表详解:动态数据结构的高效实现
"深入分析Linux内核链表,讨论2.6.x内核中链表结构的实现,并通过实例解析每个链表操作接口。适合嵌入式学习者阅读,参考书籍《深入理解Linux内核》。"
Linux内核链表是操作系统核心中用于组织和管理数据的关键数据结构,它提供了灵活的数据组织方式,便于在内存中动态添加和删除元素。本文将详细介绍Linux内核中的链表机制。
一、链表基础
链表是一种非连续存储的数据结构,由一系列包含数据和指针的节点组成。与数组相比,链表在插入和删除操作上具有优势,因为它们不需要移动大量内存中的元素。链表主要有以下几种类型:
1. 单链表:每个节点包含一个指针域,指向下一个节点。遍历单链表只能从头到尾,不能反向遍历。
2. 双链表:每个节点包含两个指针域,分别指向前一个和后一个节点,支持双向遍历。通过调整指针关系,可以构造出更复杂的数据结构,如二叉树或循环链表。
3. 循环链表:最后一个节点的指针返回到链表的开头,形成一个环形结构,允许从任何节点开始遍历整个链表。
二、Linux内核链表实现
Linux内核中的链表实现位于`<include/linux/list.h>`头文件中,它提供了一组高效且通用的操作接口,包括初始化、添加、删除、遍历等。主要接口有:
1. `LIST_HEAD(name)`:定义一个名为`name`的链表头。
2. `list_entry(ptr, type, member)`:从链表节点指针`ptr`获取包含该节点的结构体`type`的指针,`member`是结构体中链表节点成员的名称。
3. `list_for_each(pos, head)`:遍历链表`head`,`pos`是临时变量,用于保存当前节点。
4. `list_add(&new, prev)`:将新节点`new`添加到`prev`节点之后。
5. `list_del(&entry)`:删除`entry`节点并断开与其相邻节点的链接。
三、链表操作实例
在实际应用中,例如在设备驱动程序中,我们可能需要将设备节点组织成链表。例如,创建一个设备链表时,可以这样做:
```c
struct device {
struct list_head list; // 链表节点
// 其他设备相关数据...
};
struct device *device1, *device2;
// 初始化链表头
LIST_HEAD(device_list);
// 添加设备到链表
list_add(&device1->list, &device_list);
list_add(&device2->list, &device_list);
// 遍历设备链表
struct device *dev;
list_for_each_entry(dev, &device_list, list) {
// 对每个设备执行操作...
}
```
四、链表优化
Linux内核的链表实现还包含了一些优化措施,比如`list_for_each_entry_safe()`遍历函数,它在删除节点时避免了迭代器失效的问题。此外,内核还提供了`list_for_each_entry_reverse()`用于反向遍历链表。
总结,Linux内核链表机制是理解和开发内核级软件的基础。通过深入学习链表的原理和内核实现,开发者可以更好地利用这一强大的数据结构来解决复杂的问题,尤其是在动态数据管理方面。同时,《深入理解Linux内核》这本书也提供了更广泛的内核知识,是进一步提升技术能力的宝贵资源。
深入分析 Linux 内核链表
级别: 初级
杨沙洲 (pubb@163.net)国防科技大学计算机学院
2004 年 8 月 01 日
本文详细分析了 2.6.x 内核中链表结构的实现,并通过实例对每个链表操作接口进行了详尽的讲
解。
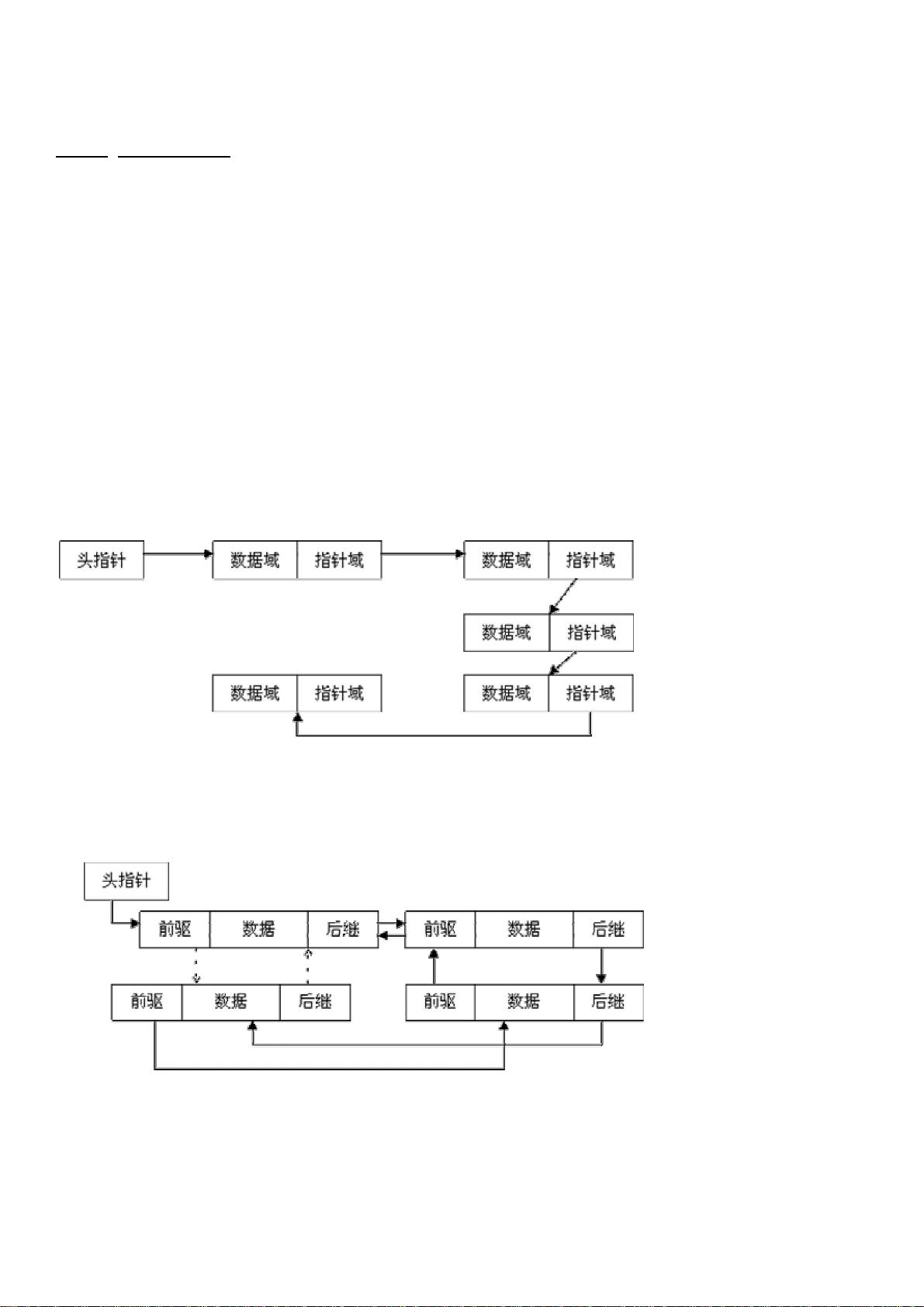
一、 链表数据结构简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成一条数据链,是线性表的
一种重要实现方式。相对于数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随机分
配空间,可以高效地在链表中的任意位置实时插入或删除数据。链表的开销主要是访问的顺序性和组织链的
空间损失。
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指针域用于建立与下一个节
点的联系。按照指针域的组织以及各个节点之间的联系形式,链表又可以分为单链表、双链表、循环链表等
多种类型,下面分别给出这几类常见链表类型的示意图:
1. 单链表
图1 单链表
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点(next),因此,对单链表的遍历只能
从头至尾(通常是NULL空指针)顺序进行。
2. 双链表
图2 双链表
通过设计前驱和后继两个指针域,双链表可以从两个方向遍历,这是它区别于单链表的地方。如果打乱前
驱、后继的依赖关系,就可以构成"二叉树";如果再让首节点的前驱指向链表尾节点、尾节点的后继指向首节
点(如图2中虚线部分),就构成了循环链表;如果设计更多的指针域,就可以构成各种复杂的树状数据结
构。
3. 循环链表
Page
1
of
8
深入分析
Linux
内核链表
2010
-
1
-
4
http://www.ibm.com/developerworks/cn/linux/kernel/l
-
chain/index.html
Generated by Foxit PDF Creator © Foxit Software
http://www.foxitsoftware.com For evaluation only.
下载后可阅读完整内容,剩余7页未读,立即下载
2011-07-14 上传
2008-11-01 上传
2020-03-04 上传
2021-09-06 上传
2013-11-11 上传
2012-05-25 上传
2011-11-08 上传

Milk-King
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
