Statistical Pattern Recognition: A Review
经典的统计模式识别综述,英文版
Statistical Pattern Recognition: A Review
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE

Statistical Pattern Recognition: A Review
Anil K. Jain, Fellow, IEEE, Robert P.W. Duin, and Jianchang Mao, Senior Member, IEEE
AbstractÐThe primary goal of pattern recognition is supervised or unsupervised classification. Among the various frameworks in
which pattern recognition has been traditionally formulated, the statistical approach has been most intensively studied and used in
practice. More recently, neural network techniques and methods imported from statistical learning theory have been receiving
increasing attention. The design of a recognition system requires careful attention to the following issues: definition of pattern classes,
sensing environment, pattern representation, feature extraction and selection, cluster analysis, classifier design and learning, selection
of training and test samples, and performance evaluation. In spite of almost 50 years of research and development in this field, the
general problem of recognizing complex patterns with arbitrary orientation, location, and scale remains unsolved. New and emerging
applications, such as data mining, web searching, retrieval of multimedia data, face recognition, and cursive handwriting recognition,
require robust and efficient pattern recognition techniques. The objective of this review paper is to summarize and compare some of
the well-known methods used in various stages of a pattern recognition system and identify research topics and applications which are
at the forefront of this exciting and challenging field.
Index TermsÐStatistical pattern recognition, classification, clustering, feature extraction, feature selection, error estimation, classifier
combination, neural networks.
æ
1INTRODUCTION
B
Y the time they are five years old, most children can
recognize digits and letters. Small characters, large
characters, handwritten, machine printed, or rotatedÐall
are easily recognized by the young. The characters may be
written on a cluttered background, on crumpled paper or
may even be partially occluded. We take this ability for
granted until we face the task of teaching a machine how to
do the same. Pattern recognition is the study of how
machines can observe the environment, learn to distinguish
patterns of interest from their background, and make sound
and reasonable decisions about the categories of the
patterns. In spite of almost 50 years of research, design of
a general purpose machine pattern recognizer remains an
elusive goal.
The best pattern recognizers in most instances are
humans, yet we do not understand how humans recognize
patterns. Ross [140] emphasizes the work of Nobel Laureate
Herbert Simon whose central finding was that pattern
recognition is critical in most human decision making tasks:
ªThe more relevant patterns at your disposal, the better
your decisions will be. This is hopeful news to proponents
of artificial intelligence, since computers can surely be
taught to recognize patterns. Indeed, successful computer
programs that help banks score credit applicants, help
doctors diagnose disease and help pilots land airplanes
depend in some way on pattern recognition... We need to
pay much more explicit attention to teaching pattern
recognition.º Our goal here is to introduce pattern recogni-
tion as the best possible way of utilizing available sensors,
processors, and domain knowledge to make decisions
automatically.
1.1 What is Pattern Recognition?
Automatic (machine) recognition, description, classifica-
tion, and grouping of patterns are important problems in a
variety of engineering and scientific disciplines such as
biology, psychology, medicine, marketing, computer vision,
artificial intelligence, and remote sensing. But what is a
pattern? Watanabe [163] defines a pattern ªas opposite of a
chaos; it is an entity, vaguely defined, that could be given a
name.º For example, a pattern could be a fingerprint image,
a handwritten cursive word, a human face, or a speech
signal. Given a pattern, its recognition/classification may
consist of one of the following two tasks [163]: 1) supervised
classification (e.g., discriminant analysis) in which the input
pattern is identified as a member of a predefined class,
2) unsupervised classification (e.g., clustering) in which the
pattern is assigned to a hitherto unknown class. Note that
the recognition problem here is being posed as a classifica-
tion or categorization task, where the classes are either
defined by the system designer (in supervised classifica-
tion) or are learned based on the similarity of patterns (in
unsupervised classification).
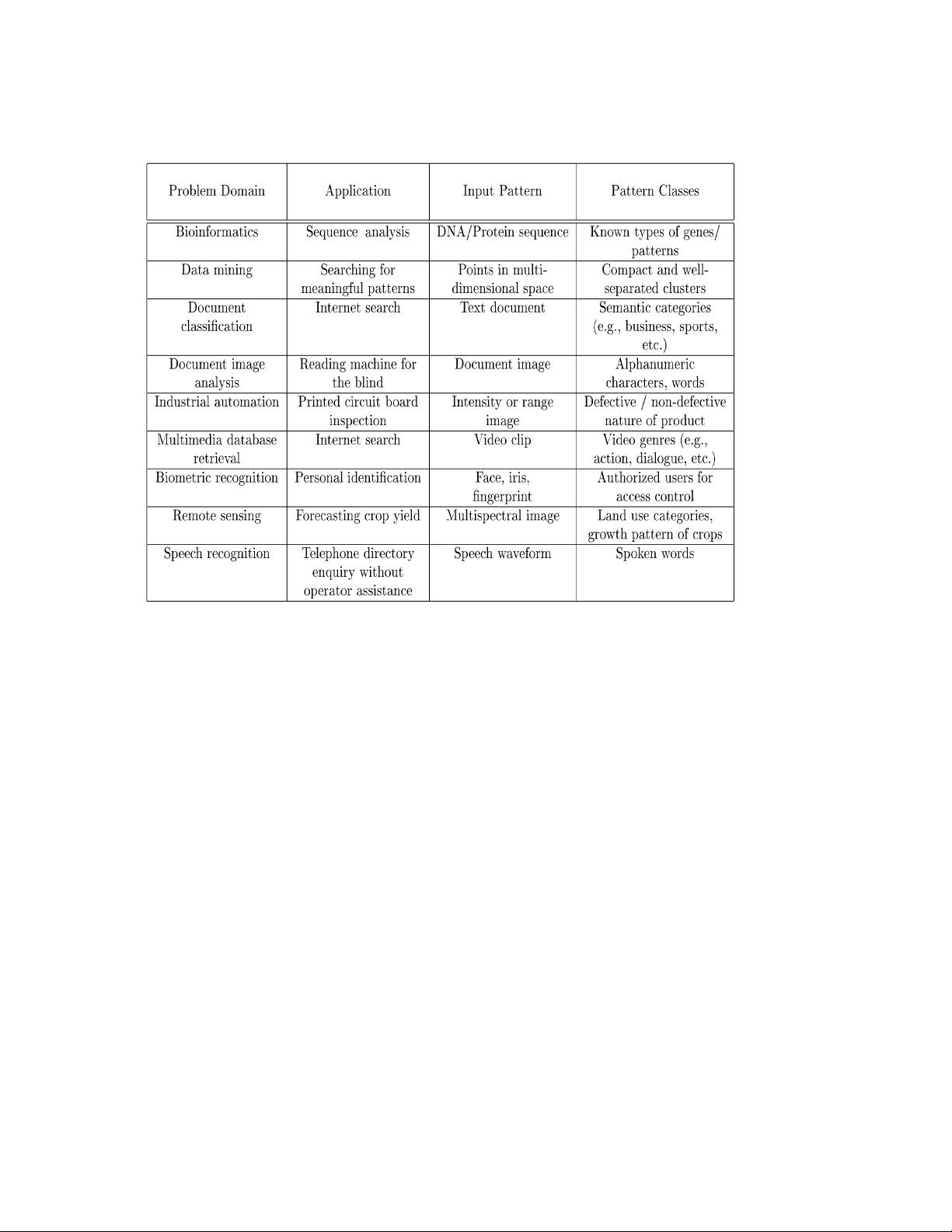
Interest in the area of pattern recognition has been
renewed recently due to emerging applications which are
not only challenging but also computationally more
demanding (see Table 1). These applications include data
mining (identifying a ªpattern,º e.g., correlation, or an
outlier in millions of multidimensional patterns), document
classification (efficiently searching text documents), finan-
cial forecasting, organization and retrieval of multimedia
databases, and biometrics (personal identification based on
4 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 22, NO. 1, JANUARY 2000
. A.K. Jain is with the Department of Computer Science and Engineering,
Michigan State University, East Lansing, MI 48824.
E-mail: jain@cse.msu.edu.
. R.P.W. Duin is with the Department of Applied Physics, Delft University
of Technology, 2600 GA Delft, the Netherlands.
E-mail: duin@ph.tn.tudelft.nl.
. J. Mao is with the IBM Almaden Research Center, 650 Harry Road, San
Jose, CA 95120. E-mail: mao@almaden.ibm.com.
Manuscript received 23 July 1999; accepted 12 Oct. 1999.
Recommended for acceptance by K. Bowyer.
For information on obtaining reprints of this article, please send e-mail to:
tpami@computer.org, and reference IEEECS Log Number 110296.
0162-8828/00/$10.00 ß 2000 IEEE


剩余33页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2010-09-25 上传
2015-03-03 上传
2008-11-28 上传
2015-06-26 上传
2023-06-07 上传

wangyx
- 粉丝: 3
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
