CUDA编程指南:NVIDIA GPGPU官方教程
"NVIDIA CUDA C Programming Guide 是一本详细介绍如何在NVIDIA公司的GPU上进行并行编程的官方指南,适用于GPGPU(通用计算GPU)的CUDA平台,是学习CUDA C语言的重要教材。此版本为3.1.1,日期为2010年7月21日。"
CUDA是NVIDIA推出的一种编程模型,它允许开发者利用GPU的强大计算能力执行通用计算任务,而不仅仅是图形处理。CUDA C是用于CUDA编程的语言,基于标准的C/C++,但增加了对并行计算特性的支持。
从版本3.1.1的更新中可以看出以下几个关键变化:
1. 移除了关于在64位主机代码中加载32位设备代码的部分,因为此功能在下一个工具包版本中将不再被支持。这意味着开发者需要确保他们的代码与目标GPU的位宽兼容。
2. 在3.2.6.3节中,提到了所有计算能力大于1.0的设备现在都支持映射的页锁定主机内存。这是一项优化,允许更快的主机与设备之间的数据交换,因为它消除了内存拷贝的开销。
3. 在3.2.7.1节中,指出对于64KB或更小的内存块,主机与设备之间的内存复制是异步的。这表示开发者可以并行执行多个内存操作,提高程序效率。
4. 修正了2.0计算能力设备的最大3D纹理引用大小(2048而不是4096),见G.1节。这对于使用大纹理的图形和计算应用来说是重要的规格更新。
5. 在C.2.1节中,关于`__fdividef(x, y)`函数的行为进行了澄清,解释了其在不同计算能力和编译标志下的行为。这个浮点除法函数的行为可能因硬件和编译选项而异。
本书的目录结构通常包括:
1. 第1章介绍了从图形处理到通用并行计算的转变,阐述了CUDA作为通用并行计算架构的角色,以及其可扩展的编程模型。这一章为初学者提供了基础概念和背景知识。
1.1节深入探讨了GPU如何从专用于图形处理转变为能够处理广泛计算任务的平台。
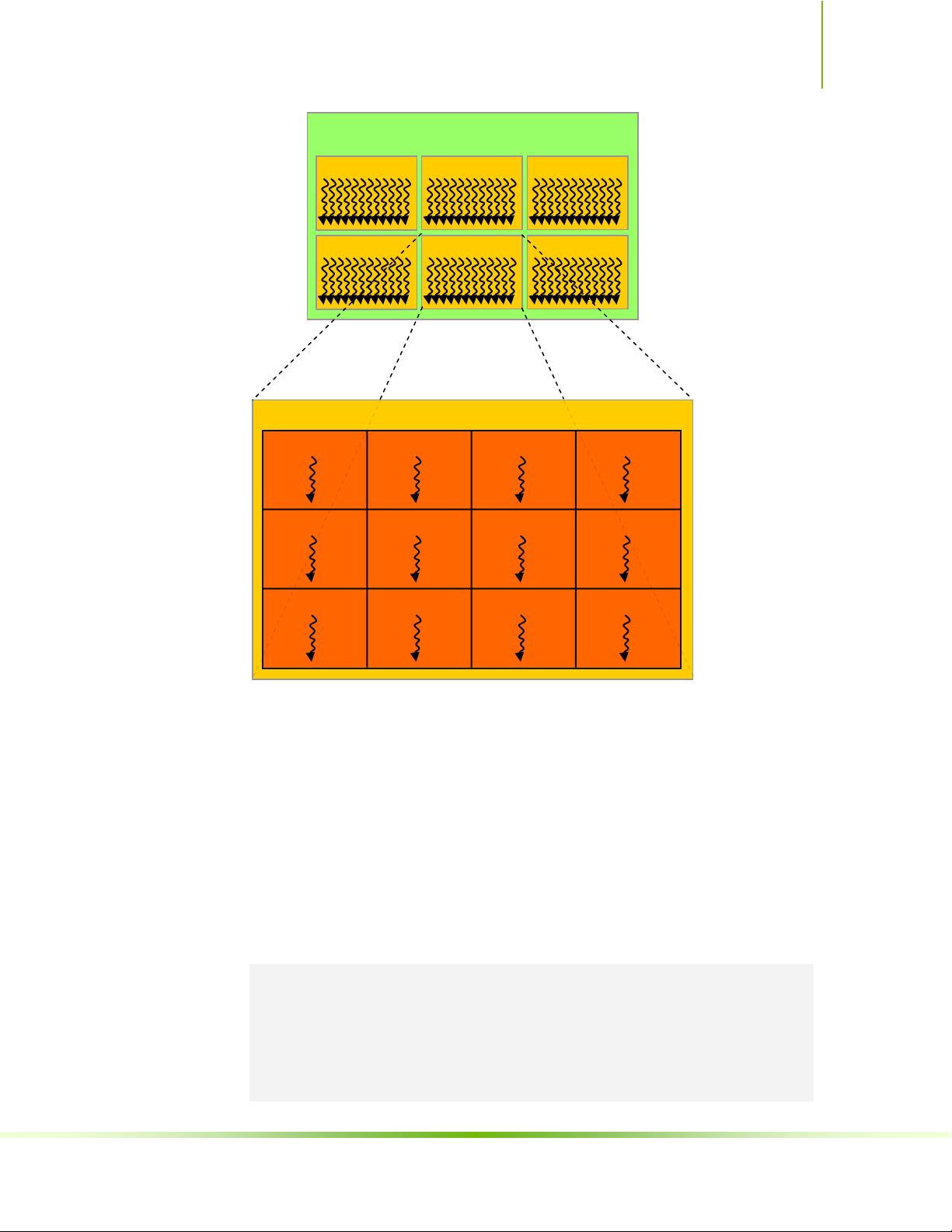
1.2节详细介绍了CUDA架构,包括GPU的多线程结构和内存层次。
1.3节则讨论了CUDA编程模型的可扩展性,包括并行执行单元、线程和线程块的组织。
通过这些章节,读者可以逐步掌握CUDA编程的基础,包括如何定义和管理线程、内存空间、同步以及如何有效地利用GPU的并行性。随着对CUDA编程的理解加深,开发者能够编写出高效利用GPU资源的并行应用程序,解决各种计算密集型问题,如物理模拟、科学计算、图像处理和机器学习等。

Chapter 1. Introduction
6 CUDA C Programming Guide Version 3.1.1
1.4 Document’s Structure
This document is organized into the following chapters:
Chapter 1 is a general introduction to CUDA.
Chapter 2 outlines the CUDA programming model.
Chapter 3 describes the programming interface.
Chapter 4 describes the hardware implementation.
Chapter 5 gives some guidance on how to achieve maximum performance.
Appendix A lists all CUDA-enabled devices.
Appendix B is a detailed description of all extensions to the C language.
Appendix C lists the mathematical functions supported in CUDA.
Appendix D lists the C++ constructs supported in device code.
Appendix E lists the specific keywords and directives supported by nvcc.
Appendix F gives more details on texture fetching.
Appendix G gives the technical specifications of various devices, as well as
more architectural details.

剩余172页未读,继续阅读
2023-05-30 上传
2023-07-14 上传
2023-07-13 上传
2023-09-08 上传
2023-07-27 上传
2023-08-16 上传

x845311724
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
