Python爬虫开发规范与实战技巧
需积分: 9 144 浏览量
更新于2024-07-04
收藏 1.96MB PPTX 举报
“爬虫开发指导.pptx”
在爬虫开发中,遵循良好的代码规范是至关重要的。Python作为爬虫开发的常用语言,其代码规范通常参照PEP8风格指南。PEP8提供了关于代码排版、命名约定、导入顺序等多方面的指导,确保代码的可读性和一致性。你可以通过官方链接(https://www.python.org/dev/peps/pep-0008/)或译文链接( http://www.cnblogs.com/ajianbeyourself/p/4377933.html)来学习和理解这些规范。在实际工作中,利用PyCharm的代码格式化功能可以帮助快速美化和整理代码。
考虑到爬虫可能遇到的运行问题,编码意识是另一个核心点。首先,要全面地处理可能出现的异常,包括页面加载异常、数据格式不一致等,避免因假设页面始终一致而导致的错误。其次,保持详尽的日志记录并根据问题发生的频度进行分级,便于后期的故障排查。
在数据采集策略上,要灵活选择数据来源。可以选择移动端页面、PC端页面或直接通过APP的API获取数据。移动端通常更易于爬取,但数据可能不全;PC端数据可能更全面,但爬取难度相对较大。如果目标网站提供了API,优先使用,因为API通常稳定性更高,维护成本较低。只有在必要时才考虑使用像selenium这样的自动化测试工具来模拟用户交互。
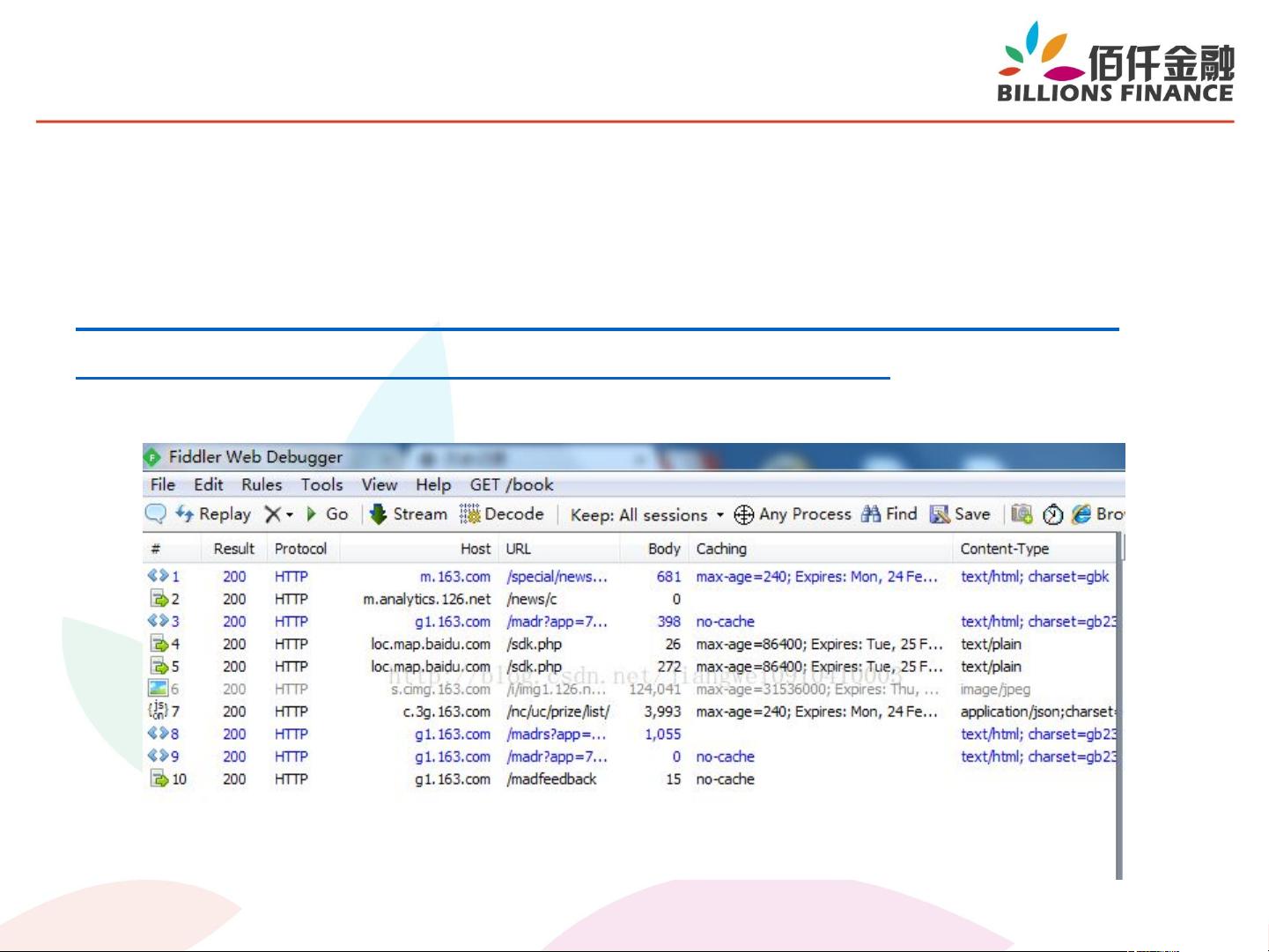
开发爬虫时,Firefox的开发者工具(快捷键Ctrl+Shift+I)是一个强大的辅助工具。它允许查看HTML元素、源代码(Ctrl+U)、筛选网络请求,并支持HTTPS解析。此外,Firefox的Firebug扩展提供更强大的cookie调试功能。Fiddler则是一款强大的抓包工具,虽然不支持HTTPS报文解析,但在HTTP协议分析方面非常有用。对于Firefox,还有XPath插件用于验证XPath表达式,以及User-AgentSwitcher插件,方便在不同设备间切换,以模拟移动端浏览器。
对于App数据的抓取,可以利用Fiddler进行抓包分析,了解App的网络请求。然而,App可能会采取防爬措施,如使用rsa、aes、sha1或md5等加密签名来保护数据。在这种情况下,需要对App进行反编译,例如对Android App进行逆向工程,分析其加密或签名机制。这通常需要一定的逆向工程技能,可以通过相关教程(如http://blog.csdn.net/vipzjyno1/article/details/2103934)学习。
爬虫开发涉及到多个层面,包括代码规范、异常处理、数据采集策略、工具选择以及应对App的反爬措施。理解并掌握这些知识点将有助于提升爬虫开发的效率和质量。


1499 浏览量
105 浏览量
2023-03-19 上传
2021-09-21 上传
2021-10-14 上传
103 浏览量
2021-11-18 上传
2024-04-25 上传
2022-11-14 上传

0x0007
- 粉丝: 3701
 我的内容管理
展开
我的内容管理
展开







最新资源
- 示波器基础与应用:理解示波器的工作原理和功能
- Linux系统中RPM与非RPM软件的安装与卸载指南
- Linux系统操作实用技巧精选33例
- Linux新手入门:常用命令详解与操作指南
- Linux网络命令速览:基础到高级操作指南
- InstallShield 10-11 教程:快速入门安装包制作
- JSTL核心标签与应用全面解析
- OMG空间领域任务 force与XTCE:XML遥测和命令交换标准
- 提升NIT-Pro客观题案例考试技巧:实战与编译要点解析
- 掌握Spring架构:模式驱动的Java开发指南
- SQL应用教程详解:基础到高级操作
- 基于块方向的指纹图像增强与新型匹配技术
- Django快速搭建待办事项列表:30分钟入门教程
- 掌握AJAX实战:信息获取与技术详解
- JBoss Seam教程:理解上下文组件
- Subversion快速搭建与入门教程
