Spark与Hadoop对比分析:Restful架构下的大数据处理
需积分: 10 107 浏览量
更新于2024-07-19
1
收藏 2.65MB DOCX 举报
"Spark研究分析,包括Spark与Hadoop的比较,以及Spark在CentOS上的配置和计算Pi的示例,结合Restful架构讨论分布式系统的实现。"
在大数据处理领域,Spark和Hadoop是两个重要的工具,它们各自有着独特的优势。Spark以其高效性和灵活性在近年来获得了广泛关注。本篇文章将深入探讨Spark的核心特性以及它与Hadoop的对比,同时简述在CentOS操作系统上部署Spark并执行计算Pi任务的过程。
Spark的核心在于弹性分布式数据集(RDD),这是一种不可变、分区的数据集合,可在集群中并行操作。RDD的设计理念是容错性和高效性,它通过数据分区和血统关系(lineage)实现快速恢复,比Hadoop MapReduce的磁盘为中心模型更为高效。Spark不仅支持批处理,还提供了流处理、SQL查询、机器学习和图处理等丰富的功能,实现了多模式统一,简化了大数据处理的复杂性。
Hadoop,作为早期的大数据处理框架,主要由Hadoop Common、Hadoop分布式文件系统(HDFS)、YARN(Yet Another Resource Negotiator)和MapReduce组成。HDFS提供了高容错性的文件存储,而MapReduce则负责大规模数据的计算。Hadoop Common包含了各种基础工具,如配置管理、序列化和RPC机制,为Hadoop的运行提供了支持。
在CentOS上配置Spark,首先需要安装Java环境,然后下载Spark源码或预编译的二进制包。接着,配置环境变量,设置SPARK_HOME和HADOOP_CONF_DIR指向Hadoop配置目录。为了计算Pi,可以使用Spark的PiExample,这是一个简单的分布式计算任务,通过并行生成随机点来估算圆周率。
至于Restful架构,它是Web服务的一种设计风格,强调简洁和统一的接口,使得分布式系统更易于理解和使用。在Spark中,可以使用Restful API来提交作业、监控状态或获取结果,这样可以方便地集成到其他基于HTTP的应用中。
总结来说,Spark以其高性能和易用性在大数据处理中占据了重要位置,而Hadoop作为基础架构,提供了可靠的数据存储和计算能力。通过理解两者的工作原理和在CentOS上的部署实践,开发者可以更好地选择适合的工具来处理特定的大数据任务。同时,结合Restful架构,可以构建灵活且可扩展的分布式系统,满足现代数据密集型应用的需求。
;
#一个分布式计算框架(高性能计算对比)
#0 的开源实现
# 能够解决的问题:
#任务可以被分解为多个子问题,且这些子问题相对独立,彼此之间不会有牵制,可
以并行进行处理,待并行处理完这些子问题后,任务便被解决。
#海量数据的处理问题,如:-?、频率统计、倒排索引构建)用于关键词搜索,等问题。
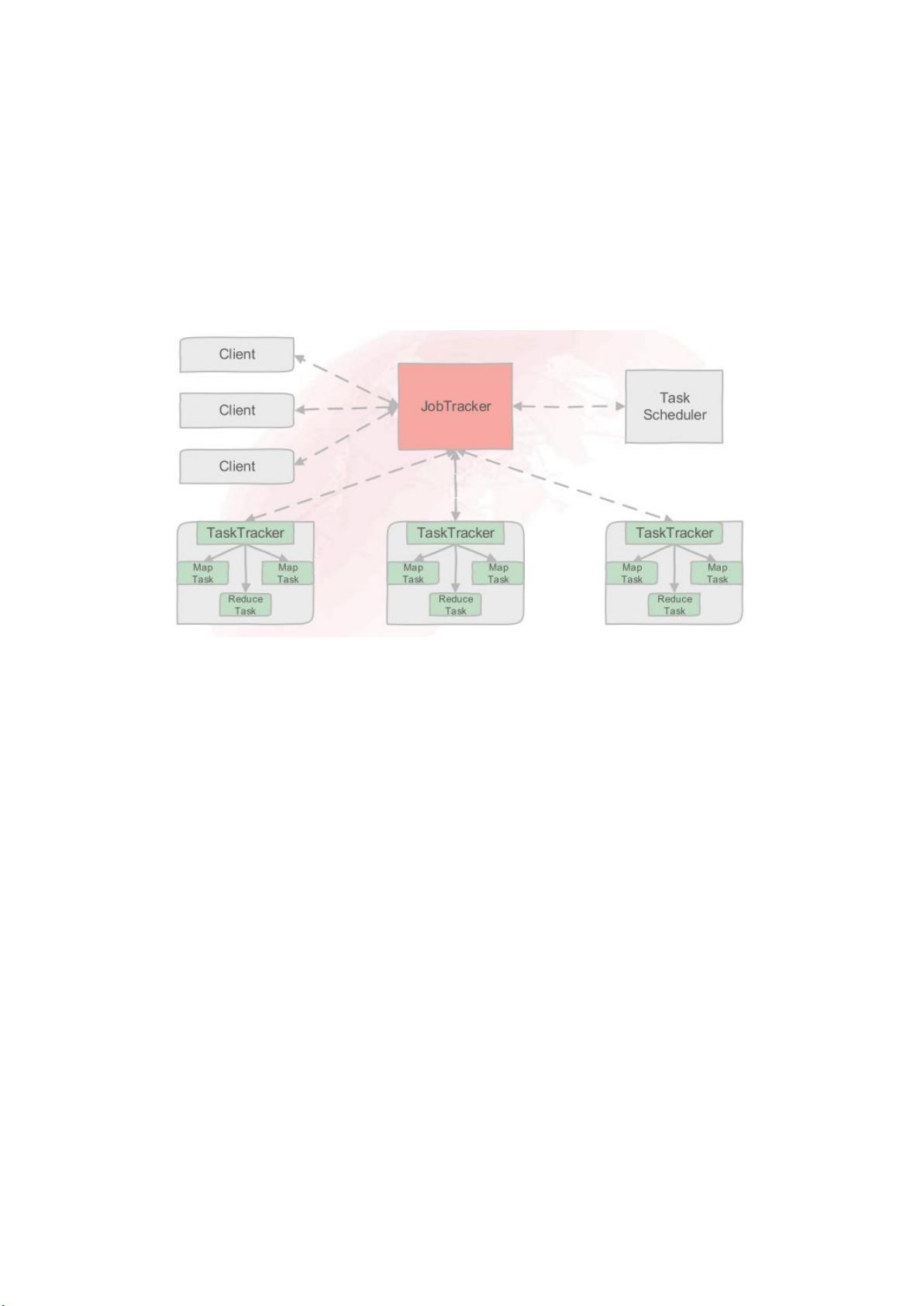
如图 @ 为 的架构。
图 @ 的架构
其中 ! 用于提交用户编写的 程序,A%-/ 主要负责资源监控和作业
调度,- /-/ 会周期性的通过 !%! 将本节点上资源的使用情况和任务的运行进度
汇报给 A%-/,同时接受 A%-/ 发送过来的命令执行相应的操作(如启动新任务、
杀死任务等),- / 分为 - / 和 - / 两种,均由 - /-/ 启动。
# 的编程模型:
# 由两个阶段完成: 阶段和 阶段。用户只需编写 ),和
),两个函数,即可完成简单的分布式程序的设计。
#),函数
#以B/C'D对作为输入,产生一系列的B/C'D对作为中间结果
输出写入本地磁盘。 框架会自动将这些中间数据按照 / 值
进行分区,且 / 值分区结果相同的数据会被交给同一个 ),函数处
理。
#),函数
#以 / 以及对应的 ' 列表(即B/C !B'DD)作为输入,经过合
并 / 相同的 ' 值后,产生一系列的B/C'D对作为最终结果输出。
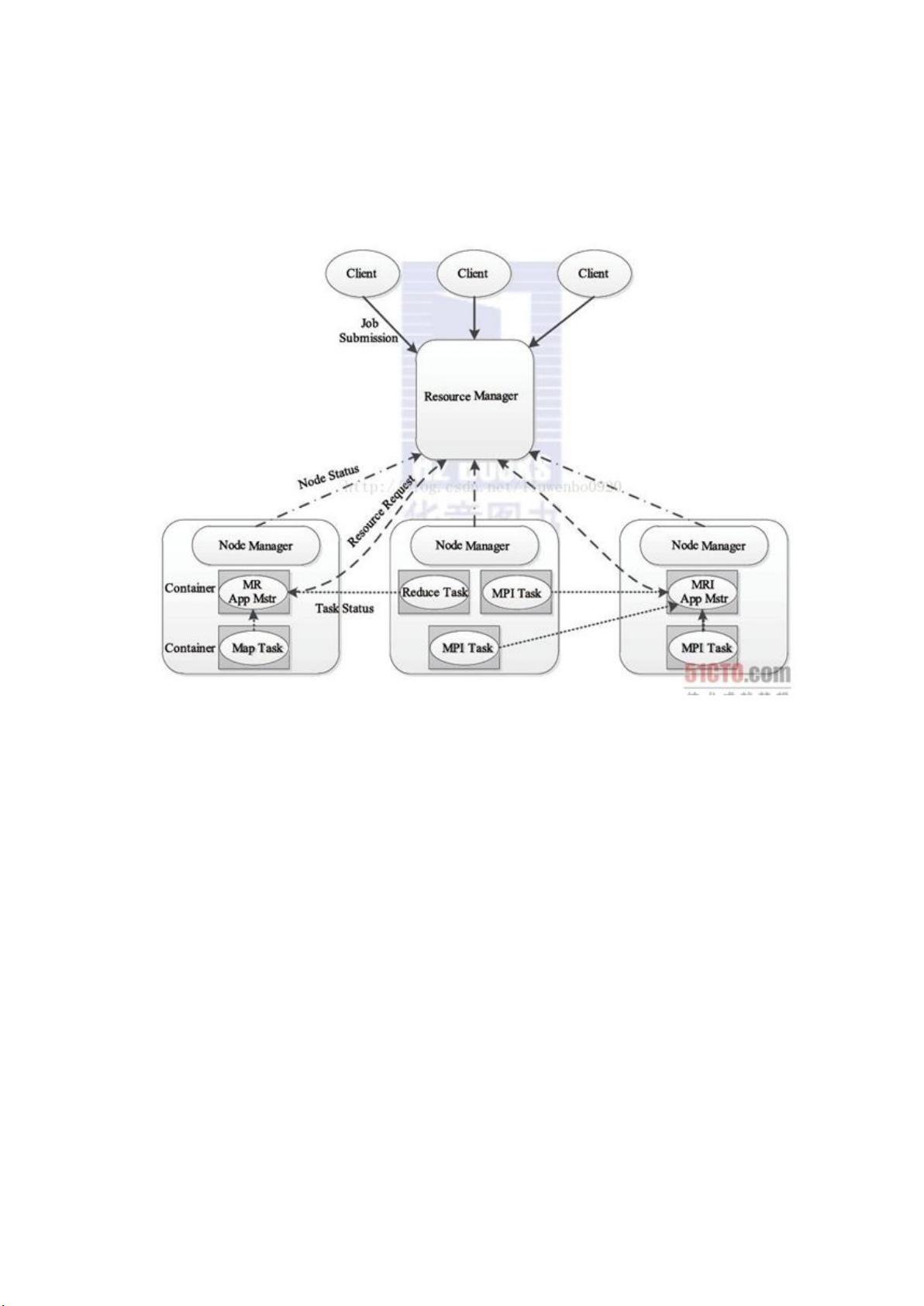
< )!! !,
#一个作业调度和集群资源管理框架
#可以认为是 ',目标已经不再局限于支持 一种计算框架,而是朝着多
种框架进行统一管理的方向发展
#、/、!、<、" 等都可以在其上运行
剩余36页未读,继续阅读
2021-05-14 上传
2017-03-30 上传
2022-12-08 上传
2021-10-14 上传
2023-09-16 上传
2021-09-23 上传
2022-11-12 上传
2023-09-26 上传

HighBro
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
