词汇分析:从字符串到词串的探索
需积分: 50 4 浏览量
更新于2024-07-25
收藏 513KB PPT 举报
"搜索之拆词分词"
在自然语言处理(NLP)领域,搜索过程中的拆词分词是一项至关重要的任务。这一过程涉及到将连续的字符序列(字符串)分割成有意义的语言单位,即“词”。这是因为计算机理解和处理自然语言时,需要将文本转换为可操作的单元,这些单元通常是最基本的语义构建块——词语。
1. 从字符串到词串
拆词分词的目标是减少不确定性,提高信息检索或文本分析的准确性。例如,在中文中,单个汉字无法表达完整的意义,必须通过组合形成词组才能传达准确含义。例如,"后"可以是"后面"的一部分,也可以是"皇后"的"后"。此外,还要处理简繁体转换、错别字校正等问题。在英文中,"eat"和"ate"在字符串层面不同,但在词层面表示同一概念的不同形态。因此,从字符串到词串的过程是降低不确定性、提升理解的关键步骤。
2. 英语词汇处理
- Tokenization:这是将英文文本分解成单词(tokens)的过程,例如"I'm a student"被拆分为"I'm", "a", "student"等独立的词。
- Lemmatization:这个过程涉及分析词的内部结构和形式,以便将其还原为其基本形式,如将过去式"took"还原为动词原形"take"。
3. 汉语词汇处理
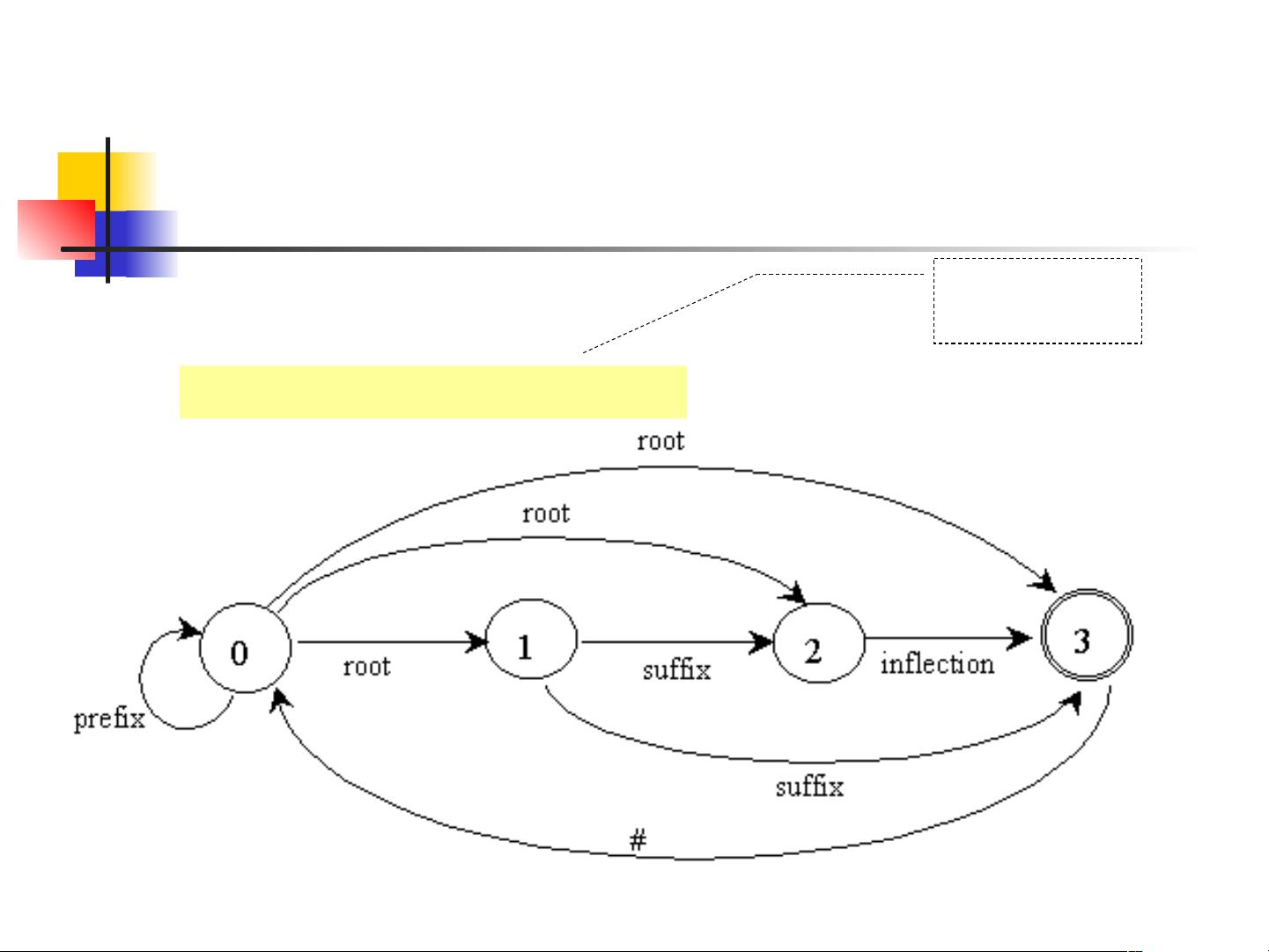
- 分词算法:汉语自动分词面临诸多挑战,因为中文没有明显的词边界。常见的分词方法包括基于规则的方法(如词典匹配)、统计方法(如隐马尔科夫模型HMM、最大熵模型MaxEnt)以及深度学习方法(如Bi-LSTM-CRF)。这些算法试图找到最可能的词切分方式。
- 汉语自动分词的困难:主要包括歧义问题(如"银行"可以指金融机构或河边)、新词识别(如网络热词)、未登录词处理(词典中不存在的词)等。
- 对分词质量的评价:通常通过准确率、召回率和F值来评估分词系统的性能。
4. 小结
词汇分析是许多NLP应用系统的基础,包括搜索引擎、机器翻译、情感分析等。无论是英文的Tokenization和Lemmatization,还是中文的分词处理,都是为了将原始的文本数据转化为可分析的结构化信息,从而更好地理解和利用文本内容。
以上内容详细阐述了搜索中拆词分词的重要性及其在不同语言环境下的实现方式,对于理解NLP技术在信息检索和文本处理中的核心作用至关重要。通过有效的词汇分析,我们可以更准确地理解用户查询,提供更相关、更精确的搜索结果。


点击了解资源详情
点击了解资源详情
点击了解资源详情
640 浏览量
140 浏览量
2009-05-14 上传
323 浏览量
128 浏览量
2024-02-23 上传

levinliboy
- 粉丝: 0
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- 图像预处理相关ppt
- 华为认证网络工程师考试题库
- C++学习网站列表.txt
- c语言试题机试题(填空)
- Linux那些事儿之我是U盘.pdf
- QTP使用指南——入门
- Linux那些事儿之我是USB+Core(v1.0).pdf
- IBM80x86实验word文档
- Linux那些事儿之我是Hub.pdf
- rbac基于角色的权限管理
- Embeded Linux Primer:A practicle,Real World Approach
- Linux那些事儿 之 我是Sysfs下.pdf
- spring开发指南 pdf
- 一个简单的c++计算器程序
- 严蔚敏 数据结构(C语言版)习题集答案
- 俄罗斯方块源代码(c语言)
