一致性Hash算法在分布式存储中的应用解析
需积分: 10 197 浏览量
更新于2024-09-12
收藏 92KB DOCX 举报
"一致性Hash算法,也称一致性cache算法,是一种在分布式系统中解决缓存映射问题的方法,尤其在面对服务器增减时,能有效减少数据映射的变动。这种算法最早在1997年的论文《Consistent Hashing and Random Trees》中提出,并在缓存系统中得到广泛应用。一致性Hash算法旨在克服传统哈希算法在服务器故障或扩展时导致大量数据重新映射的问题,从而避免对后台服务器造成过大压力。
1. 基本场景与问题
在分布式存储系统中,通常会使用多个缓存服务器来分散负载。通过计算对象的哈希值然后对服务器数量取模,可以将对象均匀分配到各个服务器。但当服务器增加或减少时,使用`hash(object)%N`的方法会导致几乎所有数据的映射关系发生变化,影响系统的稳定性和效率。
2. 单调性需求
理想的哈希算法应该具有单调性,即在添加或删除服务器后,已经存在的数据能够继续映射到新的服务器上,而不会被重新分配到其他旧服务器。传统的哈希算法往往无法满足这一需求。
3. 一致性Hash算法原理
- **环形哈希空间**:一致性Hash算法首先将哈希值空间构建成一个虚拟的圆环。每个服务器会被哈希到这个环上的一点,这些点沿环均匀分布。
- **虚拟节点**:每个物理服务器可以在环上对应多个虚拟节点,增加哈希的均匀性,也能适应服务器负载不均的情况。
- **键的映射**:键的哈希值同样被映射到环上,从键的哈希位置开始顺时针查找,找到的第一个服务器就是该键的映射服务器。
- **服务器增减的影响**:当添加新服务器时,只有新服务器附近的键会受到影响;移除服务器时,受影响的键也仅限于被移除服务器附近的键。这样大幅度减少了映射关系的变动。
4. 应用场景
一致性Hash算法在分布式缓存(如Memcached、Redis)、分布式数据库、CDN内容分发网络等场景中有广泛应用,因为它能有效平衡负载,提供容错性,并且在节点动态变化时保持相对稳定的数据分布。
5. 其他优化策略
为了进一步提高一致性Hash的效果,还可以引入跳跃因子(Jump Factor)来增加查找范围,防止数据过于集中;或者采用更复杂的哈希函数来增强映射的均匀性。
一致性Hash算法在解决分布式系统中的数据映射问题上,提供了一种高效且稳定的解决方案,有效地应对了服务器数量动态变化的挑战。"
一致性
hash
算法
- consistent hashing
一致性 hash算法( consistent hashing)
consistent hashing算法早在 1997年就在论文 Consistent hashing and random trees中被提出,目前
在 cache系统中应用越来越广泛;
1基本场景
比如你有 N个 cache服务器(后面简称 cache),那么如何将一个对象 object映射到 N个 cache上呢,你很可能
会采用类似下面的通用方法计算 object的 hash值,然后均匀的映射到到 N个 cache;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1一个 cache服务器 m down掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m的对象都会失效,怎
么办,需要把 cache m从 cache中移除,这时候 cache是 N-1台,映射公式变成了 hash(object)%(N-1);
2由于访问加重,需要添加 cache,这时候 cache是 N+1台,映射公式变成了 hash(object)%(N+1);
1和 2意味着什么?这意味着突然之间几乎所有的 cache都失效了。对于服务器而言,这是一场灾难,洪水般的访问都
会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
2 hash算法和单调性
Hash算法的一个衡量指标是单调性( Monotonicity),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原
有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash算法 hash(object)%N难以满足单调性要求。
3 consistent hashing算法的原理
consistent hashing是一种 hash算法,简单的说,在移除 /添加一个 cache时,它能够尽可能小的改变已存在 key
映射关系,尽可能的满足单调性的要求。
下面就来按照 5个步骤简单讲讲 consistent hashing算法的基本原理。
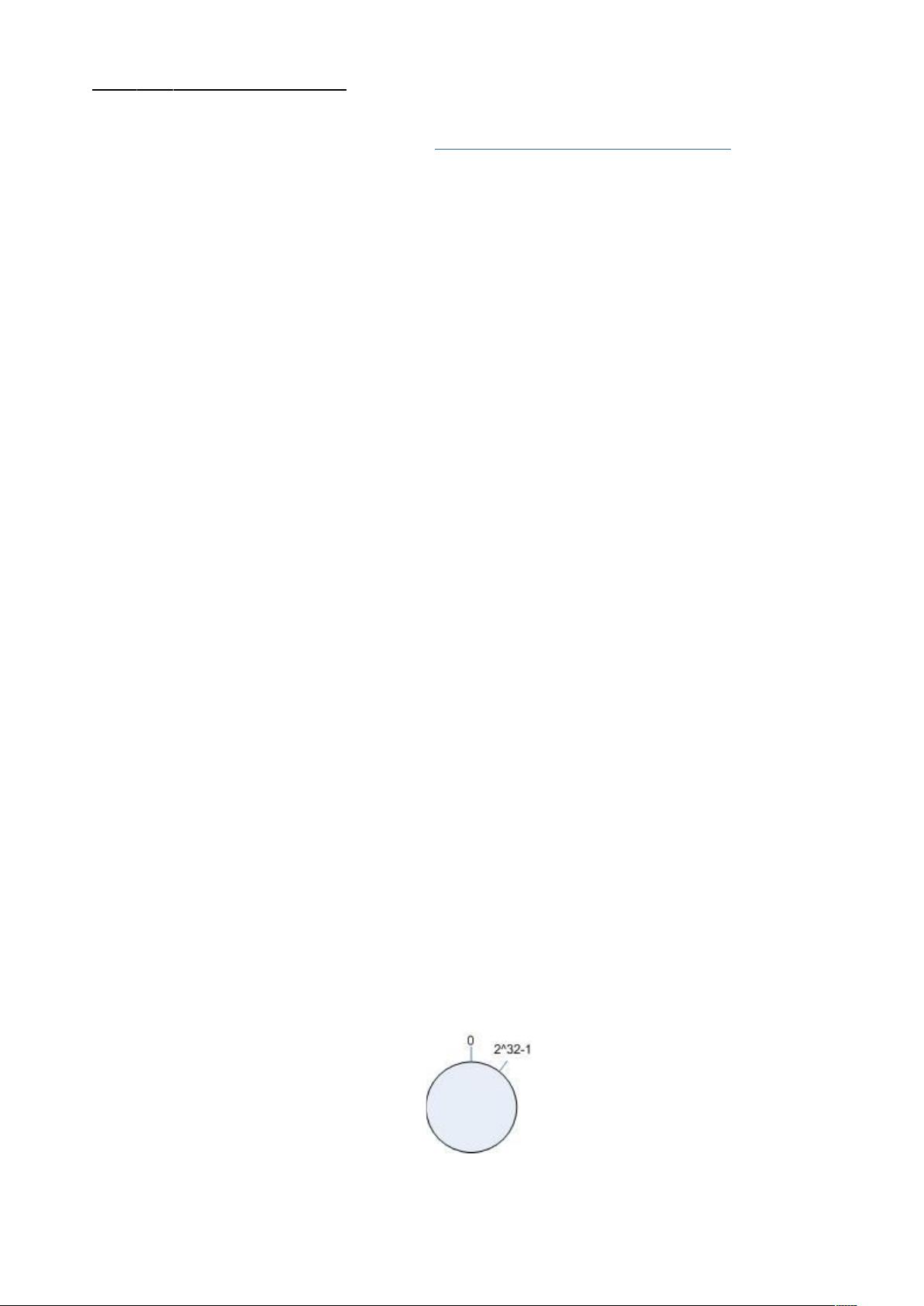
3.1环形 hash空间
考虑通常的 hash算法都是将 value映射到一个 32为的 key值,也即是 0~2^32-1次方的数值空间;我们可以将这
个空间想象成一个首( 0)尾( 2^32-1)相接的圆环,如下面图 1所示的那样。
图 1环形 hash空间
3.2把对象映射到 hash空间
下载后可阅读完整内容,剩余4页未读,立即下载
144 浏览量
282 浏览量
1561 浏览量
282 浏览量
1018 浏览量
144 浏览量
125 浏览量
293 浏览量
2020-12-19 上传

wujiuliu
- 粉丝: 47
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
