Elasticsearch索引入门与Lucene原理解析
需积分: 20 101 浏览量
更新于2024-07-09
收藏 1.43MB PPTX 举报
"此资源是一个关于Elasticsearch索引的PPT介绍,适合用于项目培训,内容涉及索引的创建、管理以及文档的处理,还涵盖了Elasticsearch与Lucene的关系,字段类型的变化以及自定义分析器等核心概念。"
Elasticsearch (ES) 是一个流行的开源搜索引擎和分析平台,它基于分布式、RESTful架构,广泛应用于日志分析、实时数据分析等领域。索引是ES中的关键概念,类似于传统数据库中的表,用于存储和检索数据。
在ES中,**禁止自动创建index** 可以通过修改`config/elasticsearch.yml`配置文件实现,将`action.auto_create_index`设置为`false`。**创建index** 需要指定`number_of_shards`(主分片数)和`number_of_replicas`(副本数)。主分片数一旦设定,后期无法更改,而副本数可以在之后进行调整。**查看index** 和**删除index** 有相应的API操作,同样,可以通过API来**创建和管理type**,但ES在6.0版本后不再支持多类型(index内包含多个type)。
**document** 是ES中的基本数据单元,相当于数据库中的记录。在用户眼中,document可能是一条包含各种字段的数据;在Lucene(ES底层的全文检索库)眼中,document被转化为一系列的词汇项(token);而在ES眼中,document会被映射成特定的mapping,每个字段都有对应的类型和索引策略。
**字段类型** 在ES的新版本中发生了变化,`string`类型被替换为`text`和`keyword`。`text`字段默认进行分词处理,适用于全文搜索;而`keyword`字段则保持原样,适用于精确匹配。**字段索引** 分为三种概念:`index=true`表示字段被索引并可搜索,`index=false`则字段不被索引,无法搜索。`type=string`会先分词再索引,而`type=keyword`则直接整体索引。
**倒排索引** 是ES的核心机制,它使得快速查找匹配的文档成为可能。**自定义分析器** 可以通过`char_filter`(字符过滤)、`tokenizer`(分词器)和`filter`(词过滤器)来定制文本处理流程。例如,可以创建一个名为`my_analyzer`的自定义分析器,组合使用内置的`html_strip`字符过滤器、`standard`分词器和`my_stopwords`过滤器。
此外,ES还支持**动态映射**,这意味着在插入document时,如果包含了type中未定义的字段,系统可以根据字段的性质自动添加映射。动态映射的策略可以设置为`true`、`false`或`strict`,分别表示允许、禁止或严格检查新增字段。
这个PPT提供了全面的ES索引基础和实践指导,对于理解和掌握Elasticsearch的索引管理和数据处理非常有帮助。
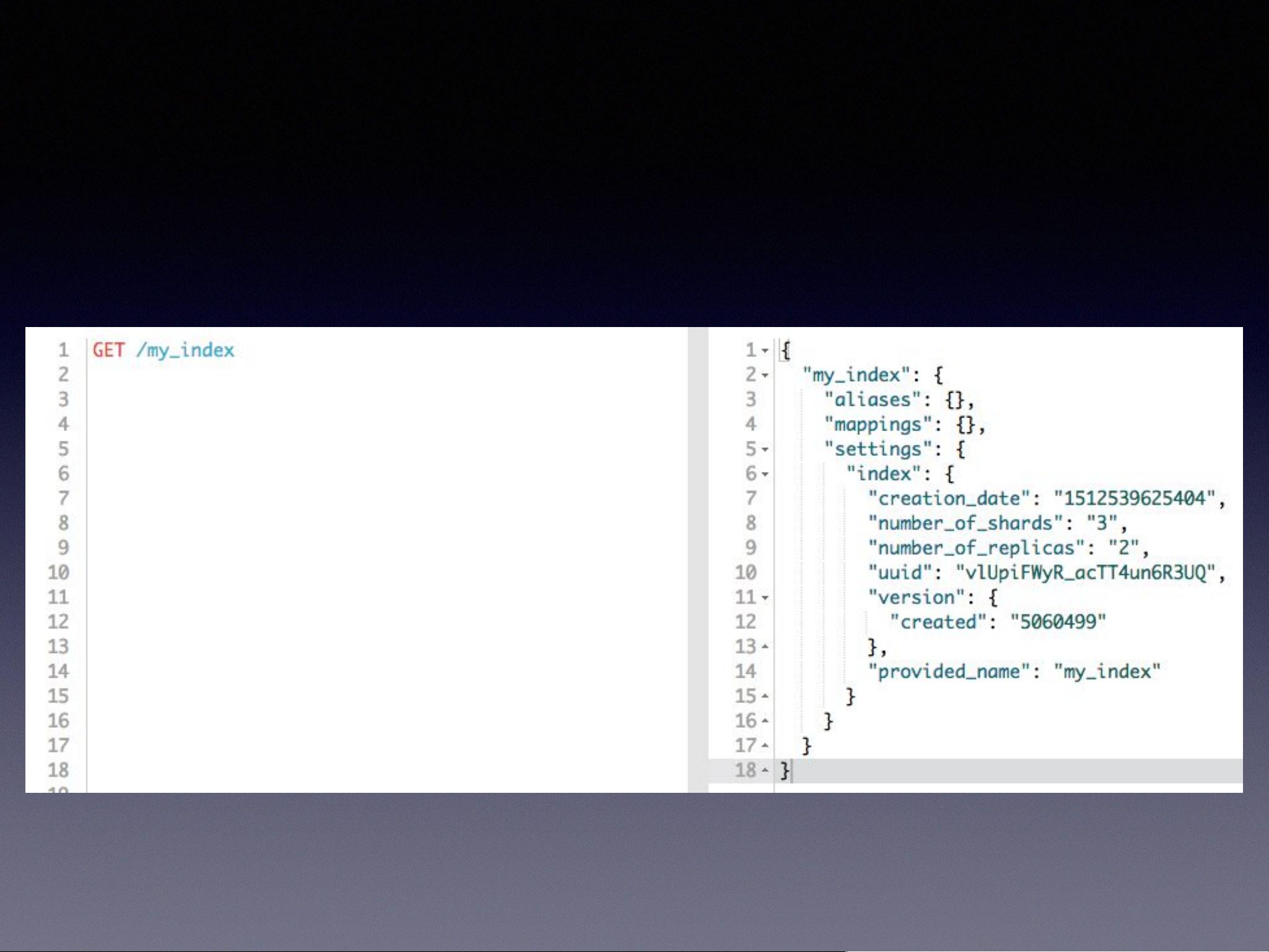
查看 index
剩余26页未读,继续阅读
661 浏览量
2021-10-18 上传
165 浏览量
118 浏览量
285 浏览量
474 浏览量
2021-10-14 上传

qq_25020179
- 粉丝: 1
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- TillandsiaPhylo:全基因组系统基因组学,PhyloGWAS等
- 西门子MPI通讯编程教材.rar
- 自动泊车代码Matlab-mapping-surrounding-MATLAB-Arduino:使用MATLAB和ARDUINO映射周围环境
- 2020psp3:编程练习III
- node.js 的模拟退火优化算法_JavaScript_代码_下载
- 首次提交
- html5+css3左右玄弧动画切换效果
- arcade-polygons-plugin:Phaser中用于街机物理的多边形
- DuilibPreview.rar
- 自动泊车代码Matlab-COSC445-Coding-Project:COSC445编码项目
- arch-i3-setup
- lets-nginx:按钮,获取TLS
- Atom-atom-ui-tweaks,使用这些光滑的调整美化您的atom编辑器ui.zip
- Linux内核的首选代码风格应该如何设置-综合文档
- generator-phaser-typescript:使用TypeScript和PhaserHTML5游戏的Yeoman生成器
- contact-us-
