使用Darknet训练自定义数据集:步骤详解
需积分: 0 97 浏览量
更新于2024-08-05
收藏 380KB PDF 举报
"该资源主要介绍了如何利用Darknet框架训练自定义的数据集,涉及YOLOv3模型的预训练权重下载、数据集的组织、训练数据列表的生成以及配置文件的修改。"
在训练自定义数据集的过程中,首先需要准备的是YOLOv3的工程环境。你可以通过Git克隆pjreddie/darknet的源代码仓库,并进入目录。在`makefile`中,你需要根据硬件资源调整编译选项,例如,如果你有GPU并希望使用它,设置`GPU=1`;如果使用OpenCV库,设置`OPENCV=1`。完成配置后,执行`make`命令来编译项目。
接着,你需要下载预训练的权重文件,这些权重通常可以在模型的官方网站或者其他可信的来源获取,并将它们放入Darknet的指定目录。这一步对于初始化训练过程至关重要,因为它提供了模型学习的基础。
数据集的准备是训练的关键。根据描述,数据集应该按照VOC格式组织,包括`Annotations`、`ImageSets`、`JPEGImages`等子目录。`Annotations`包含XML文件,记录了每个图像的标注信息;`JPEGImages`存储训练图像的JPEG格式文件;`ImageSets`下的`Main`目录通常包含`train.txt`和`val.txt`,分别表示训练集和验证集的图像列表。你可以使用工具如`getfile.py`来创建这两个文件,它们列出所有用于训练和验证的图像路径。
为了将XML标注转换成Darknet可读的格式,你需要使用`voc_label.py`脚本。这个脚本会生成训练和验证所需的txt文件,以及标注信息的label文件。在运行脚本之前,确保修改脚本中的参数,如设置`sets`为你的数据集名称,`classes`为类别的数量。运行脚本后,会得到训练和验证的文件列表,以及与`Annotations`同级的label文件。
最后,你需要修改`cfg/voc.data`配置文件以适应你的数据集。在这里,你需要指定训练样本集`train`的路径,即`train.txt`的位置,以及验证样本集`valid`的路径,即`val.txt`的位置。同时,设置`classes`为你的数据集中类别总数。
整个训练流程大致就是这样,包括环境配置、权重下载、数据预处理和配置文件修改。一旦这些步骤都完成,你就可以使用Darknet的训练接口开始训练自定义数据集的YOLOv3模型了。记得在训练过程中监控损失函数、精度等指标,以便于调整超参数或优化模型。
一.下载 yolov3 工程项目
git clone https://github.com/pjreddie/darknet
cd darknet
将 makefile 的相应部分参数改为 1,
#如果使用 GPU 设置为 1,CPU 设置为 0,GPU=0
#如果使用 CUDNN 设置为 1,否则为 0,CUDNN=0
#如果使用 OPENCV 设置为 1,否则为 0,OPENCV=1
修改后保存,再 make 一下。
将官网的预训练权重先下载到 darknet 下
二.准备训练数据集
按照下面文件夹的结构,将训练数据集放到各个文件夹下面,生成 2 个文件一个 train.txt,
一个是 val.txt。这里使用到的脚本为 getfile.py,
VOCdevkit
—VOC2012
——Annotations
——ImageSets
———Layout
———Main
———Segmentation
——JPEGImages
注意:其中 Annotations 中是所有的 xml 文件
JPEGImages 中是所有的训练文件
Main 中是 2 个 txt 文件:train.txt 与 val.txt 文件(前一个用来验证,后一个用来测试)
三.生成 2007_train.txt 和 2007_val.txt 文件
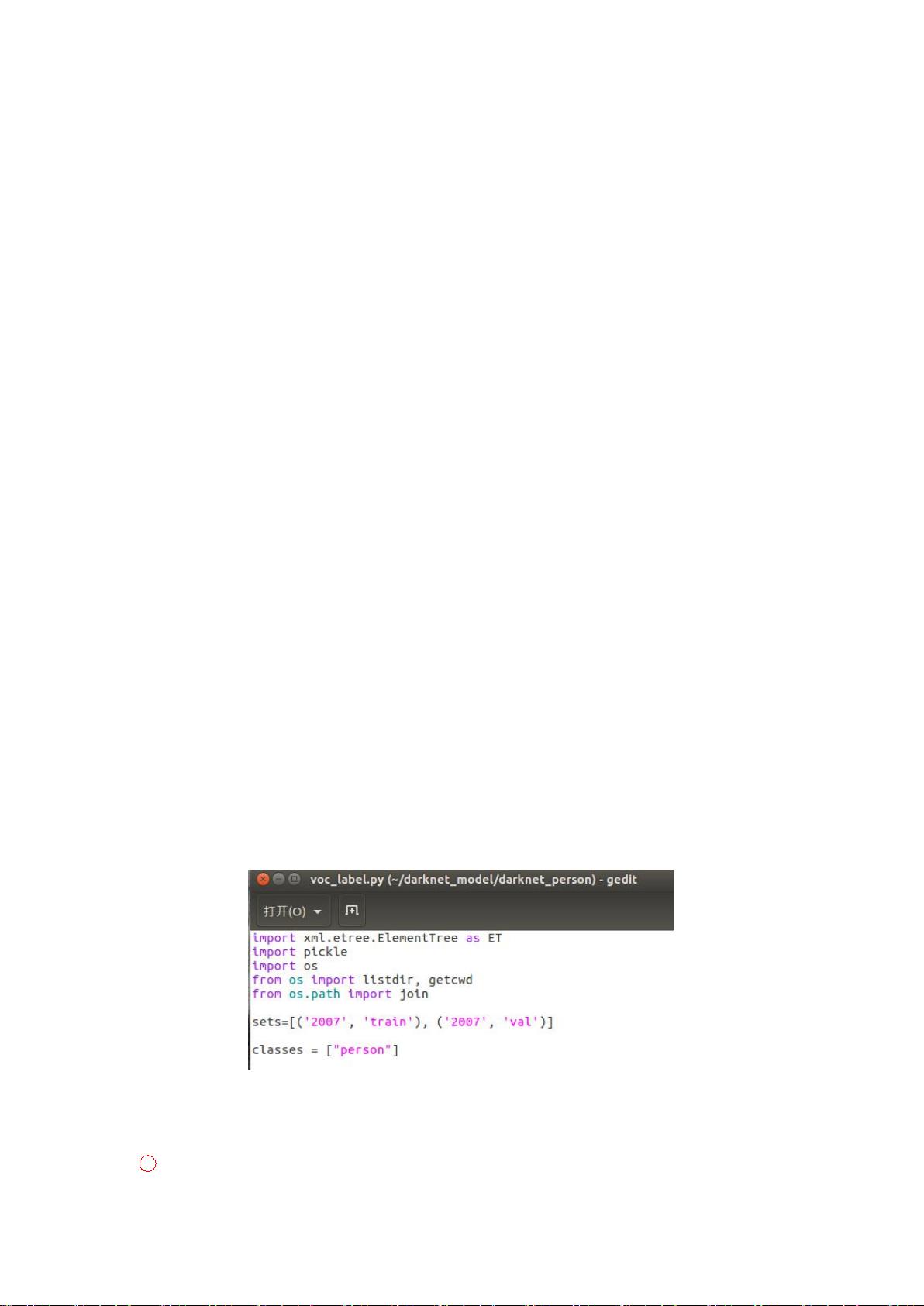
下载 voc_label.py,或者直接在 scripts 中找到 voc_labels.py 将该文件与 VOCdevkit 数据集放
到同一级路径下。
首先修改 voc_label.py 里面的值:
修改 sets 为自己训练样本集的名称,以及 classes 为训练样本集的类标签
文件最后两行注释掉。
在当前终端运行 python voc_label.py
生成
1 训练和验证的文件列表(2007_train.txt 和 2007_val.txt)主要存储的是图片位置信息;
下载后可阅读完整内容,剩余4页未读,立即下载
2023-08-25 上传
2022-04-05 上传
2022-04-14 上传
2024-08-19 上传
2023-10-13 上传
2023-06-28 上传
2023-03-09 上传

白羊的羊
- 粉丝: 45
- 资源: 280
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网络研讨会-下一个:Next.js网络研讨会
- 电影院订票系统的设计与实现.zip
- check-in
- 0546、单片机实验板使用与C语言源程序.rar
- Curso-Master-JavaScript-Udemy-Ejercicios:JS,JQuery,MaquetaciónWeb,TypeScript,Angular,NodeJS,Express Rest-https
- Monorepo
- twilio-app:使用 Twilio API 和 Amazon AWS Elastic Beanstalk 开发具有语音呼叫和 SMS 发送功能的 Web 应用程序
- 贵州各乡镇街道shp文件 最新版
- my_poultry:家禽应用程序,可将农民链接到大量库存以进行购买,将他们链接到家禽专家并帮助保存农场记录
- 0523、电压电阻转换模块.rar
- webprogramming-cocktail_website
- qt5_cadaques-pdf
- EntrenoIA:Repsitorio para aprender IA iniciando con机器学习
- HarderStart:Minecraft mod 扩展了游戏的各个进程方面,特别是早期游戏
- 拍手!-项目开发
- notebook:我的笔记本通过emacs org-mode
