Iris数据集预处理与Weka机器学习实战
需积分: 0 112 浏览量
更新于2024-08-04
收藏 417KB DOCX 举报
本篇文档主要介绍了一项关于模式识别的个人作业,由学生李中欢在2017年完成,涉及的主题是Iris数据集的分类。Iris数据集是一个经典的机器学习数据集,包含150个样本,每样包含4个属性,代表了三种鸢尾花(setosa, versicolor, virginica)的不同特征,如萼片长度、宽度和花瓣的尺寸。
实验目标有两个:一是熟悉常见的机器学习算法,二是掌握使用Weka工具进行数据分析。实验工具包括Weka软件、Python编程语言以及Tensorflow深度学习框架。文档详细描述了如何使用Weka进行数据处理和分类的过程:
1. 数据预处理:
- 首先,打开Weka的Explorer界面,导入iris.arff文件。数据预处理是关键步骤,包括特征选择、特征值归一化等。例如,通过选择unsupervised -> attribute -> Normalize,用户可以将四个特征值进行归一化,使其范围在0到1之间,便于后续处理。
2. 特征筛选与排序:
- 通过supervised -> attribute -> AttributeSelection,使用InformationGainAttributeEval作为评估方法和Ranker作为搜索策略,对特征进行排序。用户可以根据特征的信息增益值来决定其重要性,阈值设置可以帮助决定哪些特征被保留。
3. 分类器训练与验证:
- 实验中还会涉及分类器的选择和参数调整,但具体未在文中详述。接着,会执行模型训练,这通常包括将预处理后的数据输入到选定的分类器中进行学习。最后,模型的性能会在验证阶段得到评估,可能包括混淆矩阵或精度等指标。
4. 错分样本处理:
- 通过unsupervised -> instance -> RemoveMisclassified功能,可以挑选出分类器预测错误的样本,进一步分析模型的性能并可能对模型进行改进。
整个过程强调了实际操作和理解机器学习算法在处理Iris数据集时的应用,以及如何通过Weka这样的工具来进行数据预处理、特征选择和模型训练。这有助于学生深入理解机器学习的基本流程和技术。
1)数据预处理
数据预处理包括特征选择,特征值处理(比如归一化),样本选择等操作。
2)训练
训练包括算法选择,参数调整,模型训练。
3)验证
对模型结果进行验证。
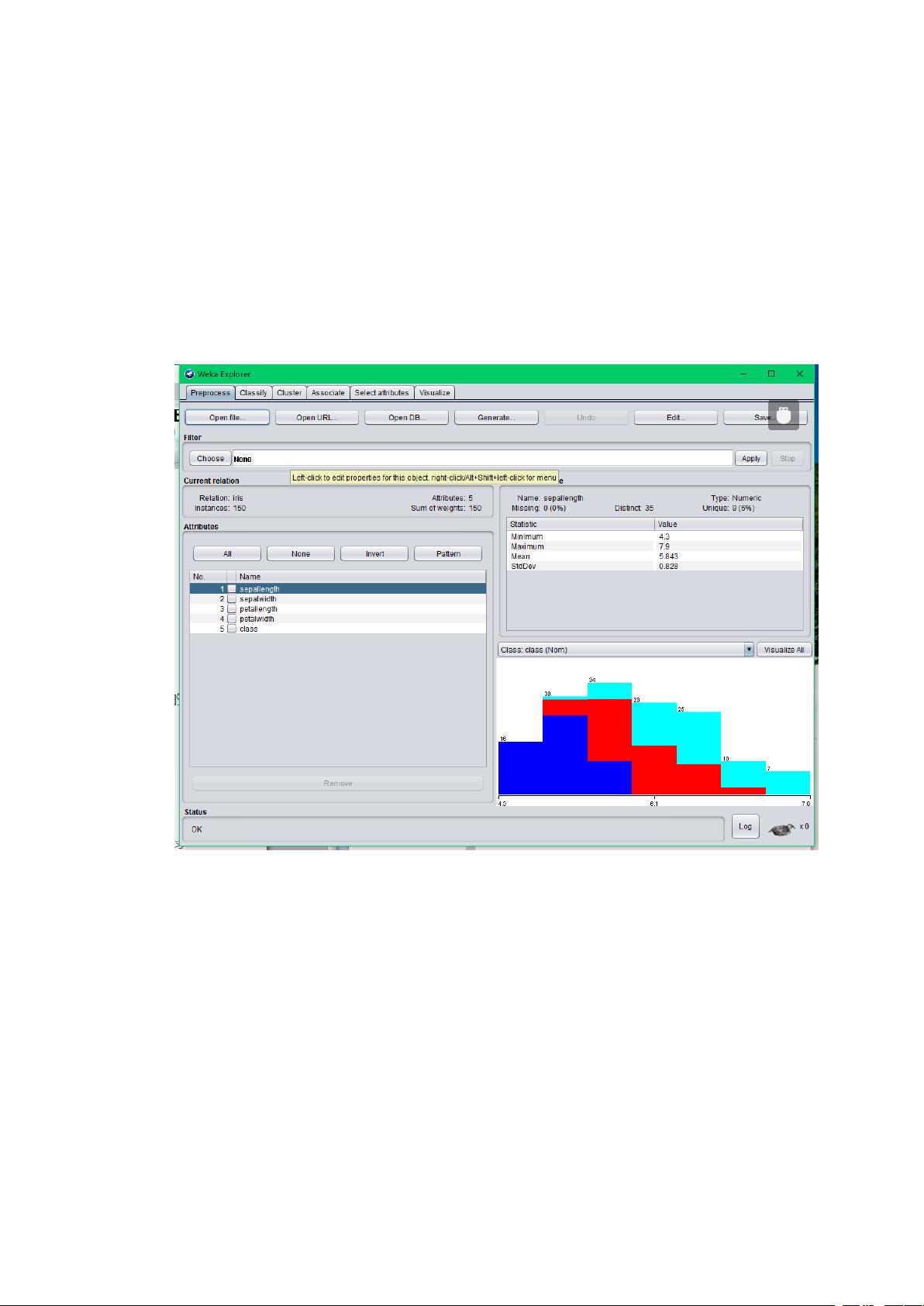
四、 数据预处理
打开 Explorer 界面,点“open file”,选择 data 数据中的“iris.arff”文件,将会看到如下
界面:
1.特征值归一化
点 击 Filter 下 的 choose 按 钮 , 选 择 unsupervised->attribute->Normalize ,
剩余10页未读,继续阅读
2024-01-24 上传
2017-11-12 上传
2020-03-17 上传
1649 浏览量
1267 浏览量
750 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

Period熹微
- 粉丝: 30
- 资源: 307
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ Qt影院票务系统源码发布,代码稳定,高分毕业设计首选
- 纯CSS3实现逼真火焰手提灯动画效果
- Java编程基础课后练习答案解析
- typescript-atomizer: Atom 插件实现 TypeScript 语言与工具支持
- 51单片机项目源码分享:课程设计与毕设实践
- Qt画图程序实战:多文档与单文档示例解析
- 全屏H5圆圈缩放矩阵动画背景特效实现
- C#实现的手机触摸板服务端应用
- 数据结构与算法学习资源压缩包介绍
- stream-notifier: 简化Node.js流错误与成功通知方案
- 网页表格选择导出Excel的jQuery实例教程
- Prj19购物车系统项目压缩包解析
- 数据结构与算法学习实践指南
- Qt5实现A*寻路算法:结合C++和GUI
- terser-brunch:现代JavaScript文件压缩工具
- 掌握Power BI导出明细数据的操作指南
