PUMA:优化多核共享内存性能与公平性的新方法
需积分: 5 195 浏览量
更新于2024-08-13
收藏 2.33MB PDF 举报
"PUMA是一种针对多核共享内存系统的研究,旨在解决内存争用和干扰问题,提升性能、公平性并降低能源消耗。通过智能地将线程划分到不同的核心,并根据线程特性分配独享的内存银行和带宽,PUMA能够有效地减少内存冲突和干扰。该解决方案在实验中显示了提高性能和效率的能力。"
PUMA(可能是“Parallel for Memory Access”的缩写)是针对现代多核系统设计的一种新颖方法,这些系统中内存被多个并发线程共享。随着核心数量的增加,内存争用和相互干扰的问题日益严重,导致性能下降、资源分配不公平以及优先级反转等问题。PUMA的主要目标是在不牺牲性能和公平性的同时,最小化主内存的能源消耗。
PUMA的核心策略是线程分区和资源专属分配。它通过分析线程的行为特征,如访问模式、工作负载等,将线程智能地分配到不同的处理器核心上,从而减少同一内存区域的竞争。此外,每个核心还会获得专有的内存银行和带宽资源,这样可以进一步减少内存访问冲突,提高内存访问效率。
为了实现这一目标,PUMA可能采用了先进的调度算法和内存管理策略。这些算法可能考虑了线程间的依赖关系、优先级以及对内存资源的需求,确保了更高效的资源分配和使用。通过这样的方式,PUMA能够有效地减轻内存争用对性能的影响,同时也有助于避免优先级反转,这是一种在多线程环境中可能导致高优先级任务被低优先级任务阻塞的现象。
实验结果显示,PUMA在提升系统性能和效率方面表现出色。这可能体现在更高的吞吐量、更低的延迟或更高的能效比等方面。Liang Shi和Gangyong Jia等人在2015年的研究中,通过模拟和实验证明了PUMA的有效性,这些成果最终发表在2016年的《JSignProcessSyst》期刊上,为多核共享内存系统的设计和优化提供了新的思路。
PUMA是多核系统中内存管理的一个重要突破,其设计理念和实施技术对于未来多核处理器架构的优化具有重要的参考价值。通过智能的线程分配和资源分配策略,PUMA为解决内存争用和干扰问题提供了一种切实可行的解决方案,有助于提升多核系统在性能、公平性和能效方面的整体表现。
J Sign Process Syst (2016) 84:139–150 141
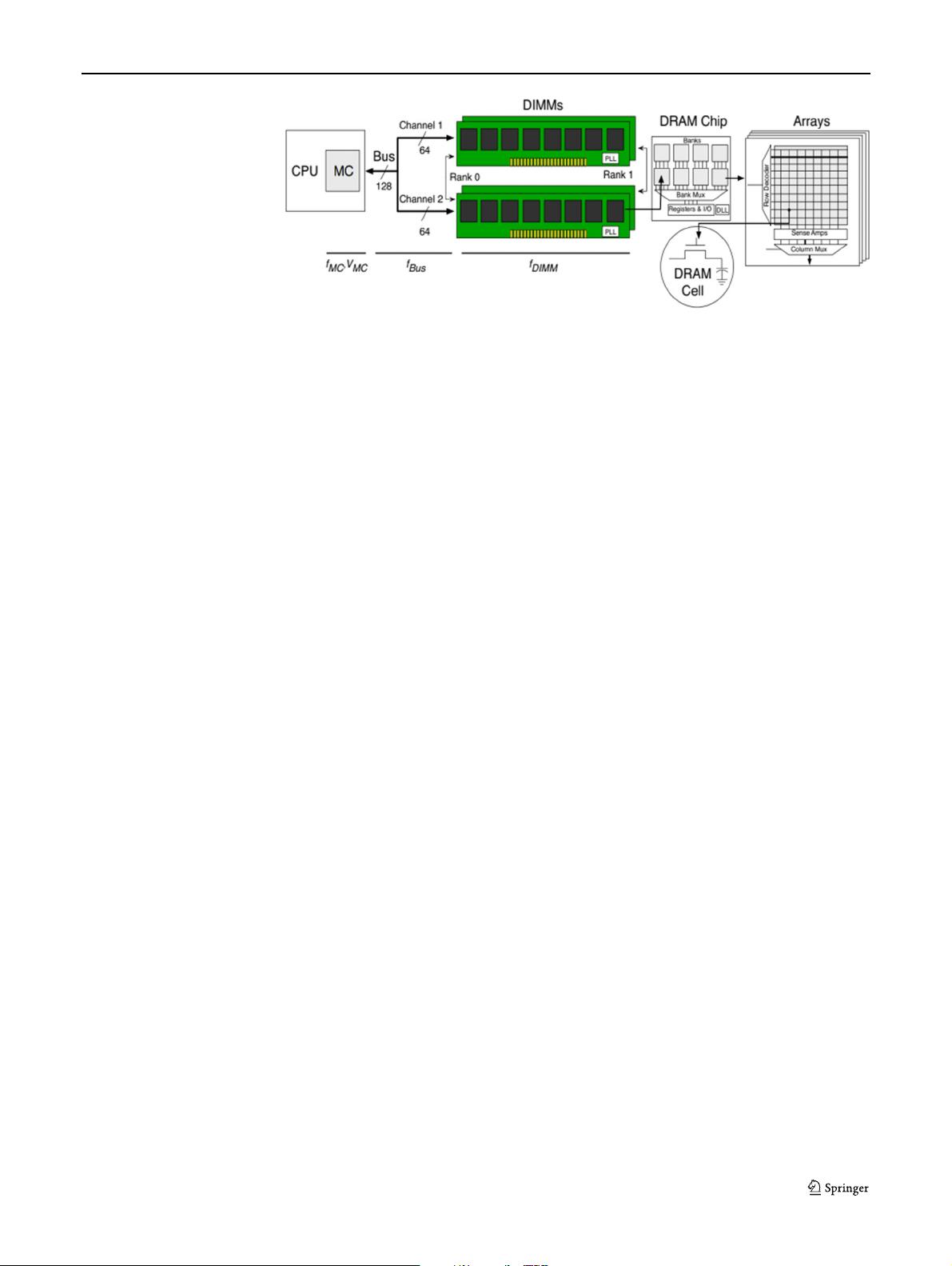
Figure 3 Organization of a
modern memory subsystem.
behalf of the CPU’s last-level cache across a memory bus.
As shown, recent processors have integrated the MC into
the same package as the CPU. To enable greater parallelism,
the width of the memory bus is split into multiple channels.
These channels act independently and can access disjoint
regions of the physical address space in parallel [11].
Multiple DIMMs may be connected to the same channel.
Each DIMM comprises a printed circuit board with register
devices, a Phase Lock Loop device, and multiple DRAM
chips. The DRAM chips are the ultimate destination of the
MC commands. The subset of DRAM chips that participate
in each access is called a rank. The number of chips in a rank
depends on how many bits each chip produces/consumes at
a time. Each DIMM can have up to 16 chips, organized into
1-4 ranks.
Each DRAM chip contains multiple banks (typically 8
banks nowadays), each of which contains multiple two-
dimensional memory arrays. The basic unit of storage in an
array is a simple capacitor representing a bit??the DRAM
cell. Thus, in a x8 DRAM chip, each bank has 8 arrays, each
of which produces/consumes one bit at a time. However,
each time an array is accessed, an entire multi-KB row is
transferred to a row buffer. This operation is called an “acti-
vation” or a “row opening”. Then, any column of the row
can be read/written over the channel in one burst. Because
the activation is destructive, the corresponding row eventu-
ally needs to be “pre-charged”, that is, written back to the
array.
2.2 OS Memory Management
Nowadays, Linux kernel’s memory management system
uses a buddy system to manage physical memory pages.
In the buddy system, the continuous 2order pages (called a
block) are organized in the free list with the corresponding
order, which ranges from 0 to a specific upper limit. When
a program accesses an unmapped virtual address, a page
fault occurs and OS kernel takes over the following execu-
tion wherein the buddy system identifies the right order free
list and allocates on block (2order physical pages) for that
program. Usually the first block of a free list is selected but
the corresponding physical pages are undetermined [12].
2.3 Related Work
There are a number of related studies.
Thread Scheduling Scheduling algorithms aimed to dis-
tribute threads to get an even distribution of miss rate among
multiple caches are proposed in [13], which avoid severe
contention on shared resource of cache, memory controller,
memory bus and prefetching hardware. Similar mechanisms
are also proposed in [14, 15]. Although these methods
can alleviate contention, they hardly eliminate the bank
interference among threads.
Channel Partition Data of different threads are mapped
into different channels according to their memory access
behavior in [1], which can eliminate the interference
between threads at channel level. However, channel parti-
tion cannot be applied to system with cache line interleaving
policy between channels [1], which limit its applicable
scope. Furthermore, there are usually more threads than
channels in a system, so some threads have to be assigned to
the same channel, which still interference with each other.
Besides, channel partition actually partitions the bandwidth
of memory system into several portions. Since the total
number of portions is limited by channel amount, which
is usually small, it is challenging to seek a balance among
channels so as to ensure no bandwidth wasted.
Thread-aware Memory Scheduling Memory controllers
are designed to distinguish the memory access behavior at
thread-level in [1, 6, 10, 16, 17], so that scheduling modules
can adjust their scheduling policy at the running time. TCM
[1], which dynamically groups threads into two clusters
(memory intensive and CPU intensive), and assign different
scheduling policy to different group, is the best scheduling
policy, which aim to address fairness and throughput at the
剩余11页未读,继续阅读
2021-05-21 上传
2021-06-03 上传
点击了解资源详情
2021-06-09 上传
2021-05-01 上传
2021-02-25 上传
2021-05-08 上传
2021-04-27 上传
2021-05-04 上传

weixin_38524139
- 粉丝: 7
- 资源: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
