大规模语言模型的无样本学习能力
需积分: 1 135 浏览量
更新于2024-07-15
收藏 6.45MB PDF 举报
"本文探讨了大型语言模型在少量示例学习(Few-shot Learning)中的能力,表明预训练和微调的方法可以显著提升NLP任务的性能。"
近年来,自然语言处理(NLP)领域取得了很多进展,主要归功于在大规模文本语料库上进行预训练,然后针对特定任务进行微调的策略。这种方法虽然在架构上是任务无关的,但仍然需要大量的任务特定微调数据集,通常包含数千乃至数十万个例子。然而,与之相比,人类通常仅需少量示例或简单指导就能完成新的语言任务,而当前的NLP系统在这方面仍有很大局限。
在这篇论文中,作者Tom B. Brown等人展示了通过扩大语言模型的规模,可以极大地提升任务无关的、少量示例学习的能力。他们指出,有时甚至无需大量任务特定的训练数据,模型就能表现出良好的性能。这表明,随着模型规模的增大,它们能够更好地捕获语言的一般规律和模式,从而在新的任务中快速适应和学习。
论文的核心观点是,大型语言模型能够通过在预训练阶段学习到的广泛知识,以一种通用的方式理解和生成语言。在实验部分,作者可能使用了各种NLP任务来验证他们的理论,包括但不限于文本分类、问答、机器翻译等。他们可能对比了不同规模模型在少量示例条件下的表现,并可能发现随着模型规模的增加,其泛化能力和适应新任务的速度有显著提升。
此外,他们还可能讨论了这种方法的潜在优势和局限性,例如,虽然大模型在少量示例学习上的性能增强,但可能会带来更高的计算成本和资源需求。同时,这种依赖于预训练的模型可能难以适应完全新颖的任务或概念,因为它基于已有的语言知识。
最后,论文可能提出了未来的研究方向,包括如何进一步优化模型以减少对大量标注数据的依赖,以及如何更好地理解和控制大型语言模型的行为,以确保它们在实际应用中的可靠性和安全性。
这篇论文揭示了预训练语言模型在少量示例学习方面的巨大潜力,为NLP研究提供了一个新的视角,即通过扩大模型规模,可能实现更接近人类的泛化能力。这一成果对于推动无监督学习和迁移学习在NLP领域的应用具有重要意义。

Setting NaturalQS WebQS TriviaQA
RAG (Fine-tuned, Open-Domain) [LPP
+
20] 44.5 45.5 68.0
T5-11B+SSM (Fine-tuned, Closed-Book) [RRS20] 36.6 44.7 60.5
T5-11B (Fine-tuned, Closed-Book) 34.5 37.4 50.1
GPT-3 Zero-Shot 14.6 14.4 64.3
GPT-3 One-Shot 23.0 25.3 68.0
GPT-3 Few-Shot 29.9 41.5 71.2
Table 3.3: Results on three Open-Domain QA tasks.
GPT-3 is shown in the few-, one-, and zero-shot settings, as
compared to prior SOTA results for closed book and open domain settings. TriviaQA few-shot result is evaluated on the
wiki split test server.
One note of caution is that an analysis of test set contamination identified that a significant minority of the LAMBADA
dataset appears to be present in our training data – however analysis performed in Section 4 suggests negligible impact
on performance.
3.1.3 HellaSwag
The HellaSwag dataset [
ZHB
+
19
] involves picking the best ending to a story or set of instructions. The examples were
adversarially mined to be difficult for language models while remaining easy for humans (who achieve 95.6% accuracy).
GPT-3 achieves 78.1% accuracy in the one-shot setting and 79.3% accuracy in the few-shot setting, outperforming the
75.4% accuracy of a fine-tuned 1.5B parameter language model [
ZHR
+
19
] but still a fair amount lower than the overall
SOTA of 85.6% achieved by the fine-tuned multi-task model ALUM.
3.1.4 StoryCloze
We next evaluate GPT-3 on the StoryCloze 2016 dataset [
MCH
+
16
], which involves selecting the correct ending
sentence for five-sentence long stories. Here GPT-3 achieves 83.2% in the zero-shot setting and 87.7% in the few-shot
setting (with
K = 70
). This is still 4.1% lower than the fine-tuned SOTA using a BERT based model [
LDL19
] but
improves over previous zero-shot results by roughly 10%.
3.2 Closed Book Question Answering
In this section we measure GPT-3’s ability to answer questions about broad factual knowledge. Due to the immense
amount of possible queries, this task has normally been approached by using an information retrieval system to find
relevant text in combination with a model which learns to generate an answer given the question and the retrieved
text. Since this setting allows a system to search for and condition on text which potentially contains the answer it
is denoted “open-book”. [
RRS20
] recently demonstrated that a large language model can perform surprisingly well
directly answering the questions without conditioning on auxilliary information. They denote this more restrictive
evaluation setting as “closed-book”. Their work suggests that even higher-capacity models could perform even better
and we test this hypothesis with GPT-3. We evaluate GPT-3 on the 3 datasets in [
RRS20
]: Natural Questions [
KPR
+
19
],
WebQuestions [BCFL13], and TriviaQA [JCWZ17], using the same splits. Note that in addition to all results being in
the closed-book setting, our use of few-shot, one-shot, and zero-shot evaluations represent an even stricter setting than
previous closed-book QA work: in addition to external content not being allowed, fine-tuning on the Q&A dataset itself
is also not permitted.
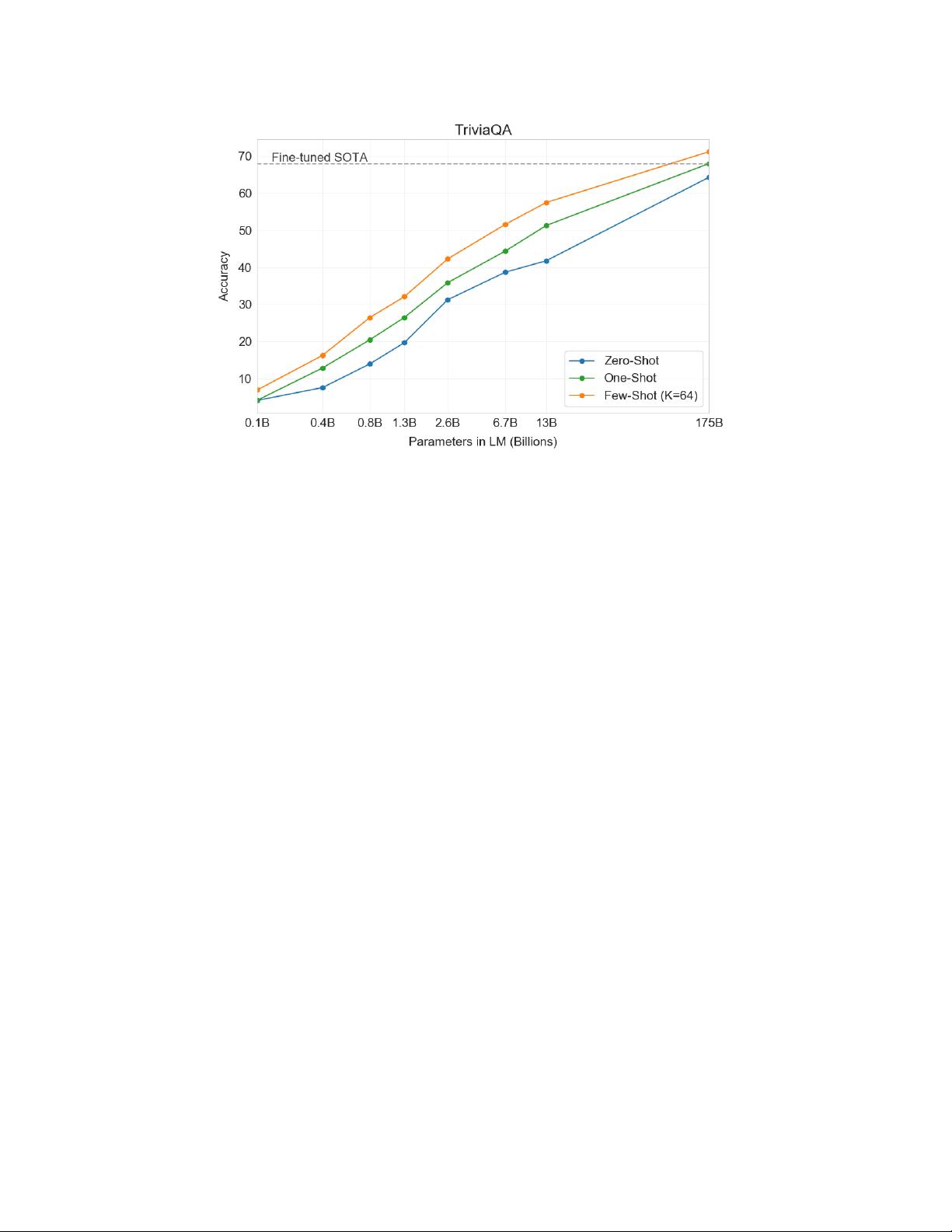
The results for GPT-3 are shown in Table 3.3. On TriviaQA, we achieve 64.3% in the zero-shot setting, 68.0% in the
one-shot setting, and 71.2% in the few-shot setting. The zero-shot result already outperforms the fine-tuned T5-11B by
14.2%, and also outperforms a version with Q&A tailored span prediction during pre-training by 3.8%. The one-shot
result improves by 3.7% and matches the SOTA for an open-domain QA system which not only fine-tunes but also
makes use of a learned retrieval mechanism over a 15.3B parameter dense vector index of 21M documents [
LPP
+
20
].
GPT-3’s few-shot result further improves performance another 3.2% beyond this.
On WebQuestions (WebQs), GPT-3 achieves 14.4% in the zero-shot setting, 25.3% in the one-shot setting, and 41.5%
in the few-shot setting. This compares to 37.4% for fine-tuned T5-11B, and 44.7% for fine-tuned T5-11B+SSM,
which uses a Q&A-specific pre-training procedure. GPT-3 in the few-shot setting approaches the performance of
state-of-the-art fine-tuned models. Notably, compared to TriviaQA, WebQS shows a much larger gain from zero-shot to
few-shot (and indeed its zero-shot and one-shot performance are poor), perhaps suggesting that the WebQs questions
13
剩余74页未读,继续阅读
2023-06-04 上传
2020-05-30 上传
2020-12-28 上传
2009-07-13 上传
2023-05-18 上传
2024-06-13 上传
2023-08-12 上传
2024-07-21 上传
2024-04-08 上传


我叫鱼大
- 粉丝: 170
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
