AWS事故深度分析:教训与防范策略
"AWS历次事故分析及启示"
AWS(Amazon Web Services)作为全球领先的云服务提供商,其稳定性和可靠性是客户关注的核心。然而,即使是这样的巨头,也难免会发生技术故障。通过对AWS历史上的几次重大事故进行分析,我们可以从中汲取教训,理解如何优化云基础设施的建设和管理,以提高系统的可用性和韧性。
首先,2011年4月21日的事故揭示了运维误操作和EBS(Elastic Block Store)系统故障的风险。这次事件中,运维人员的错误操作加上EBS系统的问题,导致USEastRegion的一个可用区(Availability Zone, AZ)内的大量EBS卷和RDS(Relational Database Service)实例受到影响。事故持续三天以上,且一部分EBS卷和RDS实例无法恢复。这提醒我们,严格的运维流程和权限控制至关重要,同时,多AZ部署可以降低单个AZ故障带来的影响。
2012年6月29日的供电故障事故则突出了物理设施层面的脆弱性。供电问题直接影响了USEastRegion的EC2(Elastic Compute Cloud)和EBS实例,以及电力恢复后的集中恢复过程中服务的中断。这次事件强调了电源冗余和故障切换机制的重要性,以及在故障恢复过程中的服务质量管理。
2012年10月22日,一个程序bug触发了EBS的重新镜像风暴,导致大规模服务中断。这反映了软件缺陷可能导致的灾难性后果,强调了代码审查和质量保证的重要性。此外,即使有Multi-AZ部署,也无法完全避免部分实例无法自动恢复的情况,这提示我们需要考虑更全面的故障恢复策略。
2012年12月24日的运维误操作影响了ELB(Elastic Load Balancing)实例,导致近一天的服务中断。这表明即使有负载均衡解决方案,人为错误仍可能导致服务不稳定。因此,运维培训和标准化操作规程的执行不容忽视。
从这些事故中,我们可以得到以下几点启示:
1. **多AZ部署**:通过在多个AZ之间分散资源,可以减轻单点故障的影响,提高整体服务的可用性。
2. **冗余设计**:包括电源、网络和计算资源的冗余,以应对物理设施故障。
3. **严格运维管理**:避免运维误操作,实施强权限控制和流程规范。
4. **自动化和监控**:建立自动化恢复流程和实时监控系统,以便快速响应故障。
5. **软件质量保证**:严格代码审查,及时发现并修复潜在的程序问题。
6. **故障恢复计划**:制定详尽的故障恢复计划,包括手动干预的步骤,以应对无法自动恢复的情况。
通过学习AWS的事故案例,我们可以改进自己的云基础设施设计,提高服务的可靠性和用户体验。同时,这也反映了AWS在不断吸取经验教训,提升其云服务的质量和稳定性。
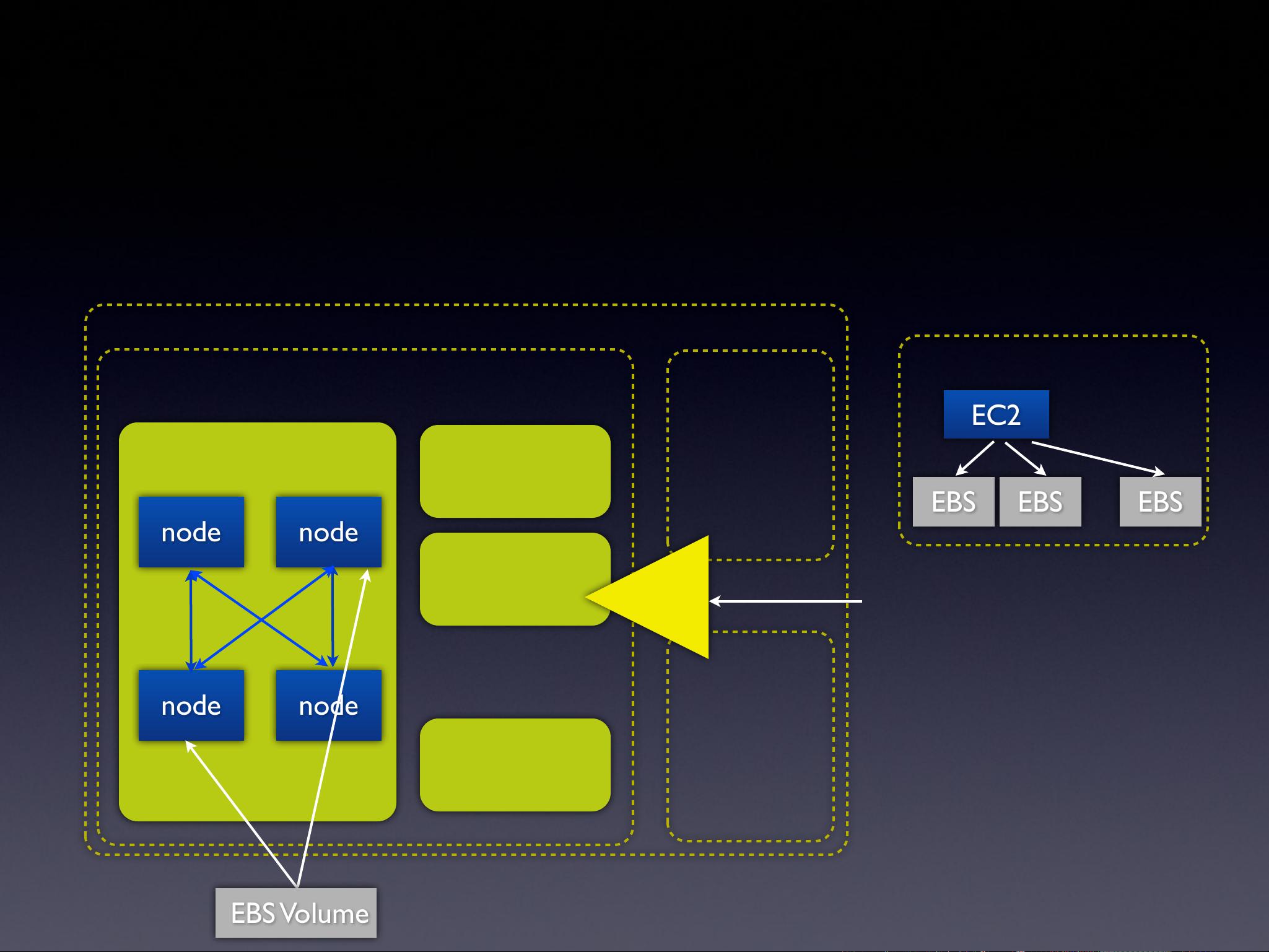
EBS & RDS架构意
Region
AZ 1
AZ 2
AZ 3
EBS Cluster 1
EBS Cluster 2
EBS Cluster3
EBS Cluster N
.
.
.
control plane
node
node
node
node
primary
backup
P2P network
- routing
- EBS选主
- 复制于多AZ以实现可
RDS Instance
EC2
EBS
EBS
EBS
...
AZ 2
络平
- primary:带宽,EBS node之间,
EBS与EC2和control panel的数据或信令
- backup:低带宽,仅于保证EBS
node之间连通性(估计于跳)
EBS Volume
如果EBS的某复本断电故障时正在进写IO,恢复后系统将不能保证数据致
性,该卷会被标为impaired状态并禁所有IO操作。Amazon推荐客户
fsck等具检查数据致性后再恢复IO操作。
剩余18页未读,继续阅读
2021-10-10 上传
2019-08-03 上传
2021-02-15 上传
2021-03-30 上传
2019-08-03 上传
2023-04-23 上传
2021-05-26 上传

Adela可爱多
- 粉丝: 78
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
