SQL Server中自增长键列统计信息处理及直方图优化
32 浏览量
更新于2024-08-30
收藏 239KB PDF 举报
在SQL Server中,自增长键列(通常用于标识符)的统计信息处理是一项关键任务,特别是对于数据库性能优化。文章主要关注的是当数据范围超出直方图步长限制时的问题。直方图是一种用于描述列数据分布的重要工具,它将数据范围划分为一系列等宽或等频的区间,每个区间代表一个步长。在SQL Server中,每个统计信息对象,如聚集索引,都会关联一个直方图,其中步长数量最大支持200个。
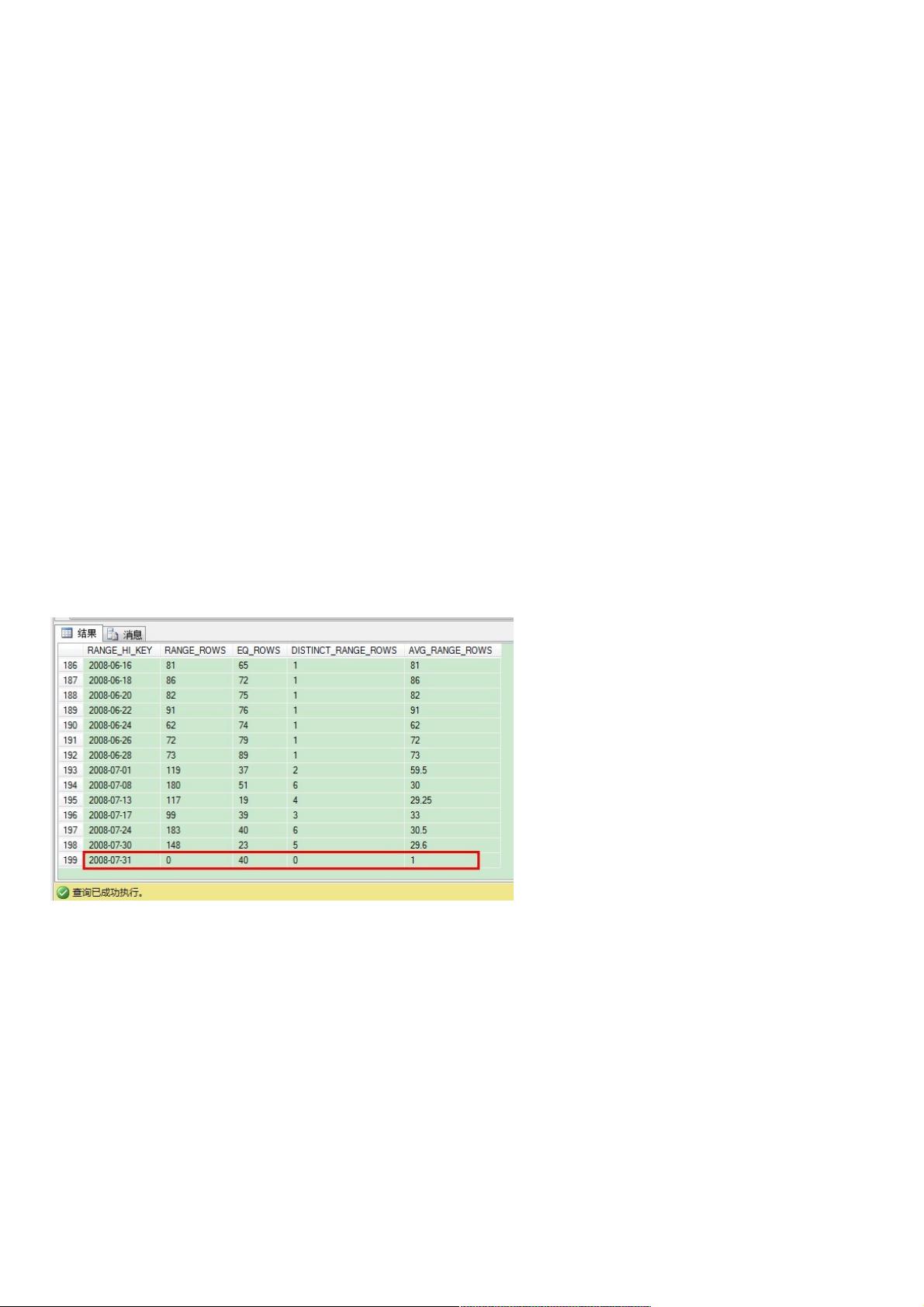
文章首先通过创建一个简单的订单表`Orders`来演示问题。该表有`OrderDate`、`Col2`和`Col3`三列,并创建了一个非唯一聚集索引`idx_CI`,基于`OrderDate`列。接着,从AdventureWorks2008R2数据库中插入大量数据,使得索引重建后的直方图显示步长最大值为2008-07-31。
当试图插入200条新的订单记录,日期范围超出了直方图的最后一个步长时,问题就出现了。这种情况下,直方图无法准确反映新数据的实际分布,因为它不再能够有效地分割数据,可能会导致查询性能下降。SQL Server仍然会尝试进行基数估算,但这并不精确,可能导致查询计划的不理想。
处理这个问题的方法主要有以下几点:
1. **调整直方图步长**:在插入大量数据前,可以通过手动调整直方图的步长来适应数据范围,但这可能需要对数据库有深入理解,并且可能需要定期维护。
2. **重新计算统计信息**:当数据分布发生较大变化时,可以考虑重建索引或使用DBCC UPDATE STATISTICS命令来更新统计信息,使其更接近当前数据分布。
3. **使用分区**:如果数据量非常大,可以考虑将表分区,每个分区有独立的直方图,这样可以减轻单个直方图的负担。
4. **评估查询优化**:当直方图不足以提供精确的信息时,查询优化器可能依赖其他统计信息或估算,因此检查并优化查询计划也是关键。
5. **使用更高级的统计技术**:在某些版本的SQL Server中,如SQL Server 2019及以上,引入了更复杂的统计模型,如哈希分布、多级细分等,它们可以提供更细致的数据分布描述,有助于减少估算误差。
理解和处理自增长键列的统计信息是SQL Server数据库管理中的重要技能,尤其是在处理大数据和复杂查询场景时,适当的直方图设计和维护是提高查询性能的关键。
自增长键列统计信息的处理方法自增长键列统计信息的处理方法
这篇文章通过文字代码的形式讲解了如何处理用自增长键列的统计信息。我们都知道,在SQL Server里每个统计信息对象都有关联的直方图。直方图
用多个步长描述指定列数据分布情况。在一个直方图里,SQL Server最大支持200的步长,但当你查询的数据范围在直方图最后步长后,这是个问
题。我们来看下面的代码,重现这个情形:
-- Create a simple orders table
CREATE TABLE Orders
(
OrderDate DATE NOT NULL,
Col2 INT NOT NULL,
Col3 INT NOT NULL
)
GO
-- Create a Non-Unique Clustered Index on the table
CREATE CLUSTERED INDEX idx_CI ON Orders(OrderDate)
GO
-- Insert 31465 rows from the AdventureWorks2008r2 database
INSERT INTO Orders (OrderDate, Col2, Col3) SELECT OrderDate, CustomerID, TerritoryID FROM
AdventureWorks2008R2.Sales.SalesOrderHeader
GO
-- Rebuild the Clustered Index, so that we get fresh statistics.
-- The last value in the Histogram is 2008-07-31.
ALTER INDEX idx_CI ON Orders REBUILD
GO
-- Insert 200 additional rows *after* the last step in the Histogram
INSERT INTO Orders (OrderDate, Col2, Col3)
VALUES ('20100101', 1, 1)
GO 200
在索引重建后,我们再看下直方图,我们发现最后步进的值是2008-07-31。
代码如下:
DBCC SHOW_STATISTICS(‘dbo.Orders’, ‘idx_CI’) WITH HISTOGRAM
你已经看到,在最后步进到表里后,我们插入了200条额外记录。这样的话,直方图并没有真实反馈实际的数据分布情况,但SQL Server还是要进行
基数计算。我们现在来看看在不同版本里SQL Server是如何处理这个问题的。
代码如下:
SQL Server 2005 SP1- SQL Server 2012
在SQL Server 2014之前,基数计算对此问题的处理非常简单:SQL Server估计行数为1,你可以从下面的图片里看到。
点击工具栏的显示包含实际的执行计划,并执行如下查询:
代码如下:
SELECT * FROM dbo.Orders WHERE OrderDate=’2010-01-01′
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-19 上传
2009-12-17 上传
点击了解资源详情
2019-11-04 上传
2022-07-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38589168
- 粉丝: 7
- 资源: 968
 我的内容管理
展开
我的内容管理
展开







最新资源
- java中MyEclipse快捷大全.pdf
- Java开源项目Hibernate快速入门
- 现代电子技术基础(数电部分)课后习题答案 第二章
- 用户界面设计分析文档
- AnyData 无线模块,AT指令全集【MODEM专用】
- asp新闻发布系统daima
- linux驱动编程(LED3)
- dx的入门pdf文件
- arm 片上系统设计要点
- javaScript语言精髓和编程实践迷你书
- Asp.net数据库常用的Sql操作
- 3G技术讲解.pdf 3G技术讲解.pdf
- javabean操作数据库
- 直驱永磁同步风力发电机的最佳风能跟踪控制[1]
- Thinking in C++ 02.pdf
- JSF in action(英文完整版)
