GrowingIO大数据平台:Spark全量采集实践与挑战
43 浏览量
更新于2024-08-31
收藏 1.11MB PDF 举报
在"Spark在GrowingIO数据无埋点全量采集场景下的实践"这篇文章中,作者分享了GrowingIO作为一家专注于数据分析的初创公司,在大数据处理方面的实际经验和挑战。GrowingIO的核心业务是提供全量数据采集服务,用户接入SDK后即可实时获取各类行为数据,无需预先设置埋点。这使得数据量庞大,每天处理的数据超过几百亿条,且具有实时筛选、回溯、多样化图表展示等功能。
面对如此巨大的数据量,GrowingIO面临的主要问题包括:
1. 数据处理压力:由于数据来源广泛且实时,对数据处理系统有着极高的性能要求,需要能快速处理并分析几百亿条数据,且要适应数据流量的波动,如高峰期和低峰期的差异。
2. 数据平台的伸缩性和实时查询能力:为了支持实时的任意元素查询和多维度组合,数据平台必须具备强大的伸缩性,能够快速响应用户请求,避免长时间的等待。
3. 海量数据的高效索引:为了提升用户体验,GrowingIO需要实现海量数据的高速索引,确保查询速度和性能。
在搭建数据平台的过程中,作者并未详述具体的Spark技术选型和实践,但提到了他们选择自建平台来应对这些挑战。这可能涉及Spark的分布式计算能力,利用其容错性、内存计算的优势处理大规模数据,以及与Hadoop等其他组件(如HDFS)的集成,确保数据的存储和管理。
接下来,文章可能会深入探讨如何在Spark上优化数据处理流程,例如使用Spark Streaming进行实时流处理,或者通过Spark SQL进行复杂的数据查询和分析。此外,可能还会提到故障恢复、数据清洗、模型训练等关键环节的策略。
这篇文章不仅讲述了GrowingIO的业务模式和所面临的挑战,还可能提供了关于如何在实际场景中有效地运用Spark构建高性能、可扩展的数据处理平台的宝贵经验。对于那些在大数据领域,特别是Spark使用方面寻求实战案例和技术分享的读者,这篇文章无疑提供了有价值的信息。
Spark在在GrowingIO数据无埋点全量采集场景下的实践数据无埋点全量采集场景下的实践
今天跟大家分享的是我们GrowingIO在使用Spark中的经验,遇见的一些问题,以及我们修复的方法。在来之前,昨天晚上我
在跟我们组同事讨论的时候,我说我发给他们简要写的我是GrowingIO的大数据工程师,我们组的几个工程师都非常的不屑,
说现在大数据已经烂大街了,所以他们对外自称数据工程师,不叫大数据工程师。
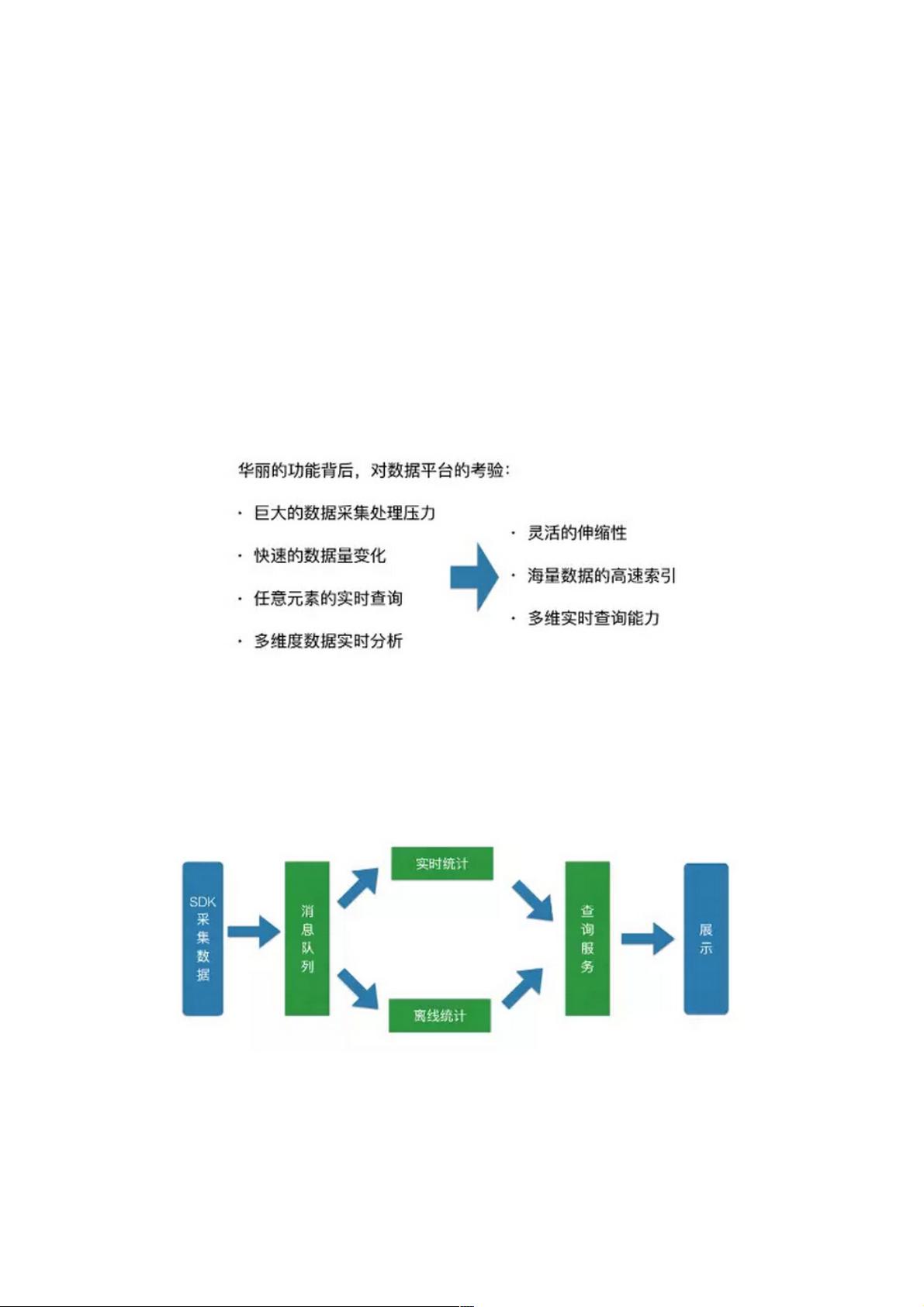
GrowingIO业务功能背后的考验
事实上,我们是一个刚成立一年的公司,今年5月份刚过了一周岁的生日,是一个标准的创业公司,但是到目前为止我们每天
处理的数据量已经超过了几百亿条,所以在我看来是一个标准的大数据公司。
每天处理这么多数据的话,我们当然会遇到很多问题,今天主要的内容就是首先介绍我们公司,我们的业务模型和我们遇到的
一些问题。第二部分我们会根据这些问题讲一下我们是如何思考和选择搭建我们自己的大数据平台。最后一部分,当我们平台
搭建完之后,会遇到一些问题,我们会想办法去优化在Spark使用过程中的这些问题。
第一部分就是我们公司介绍,我们是去年刚成立的一家公司,是做数据分析的,我们跟之前的数据公司不一样就是我们提供的
是全量采集的数据,不需要埋点,只要接入我们SDK之后,你就立刻能够获得你想要的数据分析的结果。我们现在提供iOS、
安卓、Web、H5的SDK。
我们采用的是全量采集的方案,所以不需要提前埋点,就是说所有的浏览、访问、点击所有的行为都会被采集到,这个数据量
是非常大的,而且我们提供按需筛选数据的功能,如果你想要知道某一个按键的点击量,我们会立刻帮你筛选出来。还有我们
支持随时回溯任意一个事件。我们也支持不同的图表功能、不同的维度、相互的拖拽和组合,我们提供40多种不同的维度。
提供这么多功能的话对我们平台的压力是非常大的。首先就是我们的数据处理压力非常大,我们每天要处理好几百亿条数据,
我们的数据量变化也非常快,有些应用可能周五是高峰期,有些应用是周末的高峰期,所以我们的数据有一个波峰和波谷的概
念。我们支持任意元素的实时查询,以及支持多维度的组合,所以需要整个数据平台有很强的伸缩性。我们还要支持海量数据
的高速索引,不能让用户等待时间过长,同时我们要支持多维数据的实时查询。
GrowingIO数据平台搭建
为了支持这么多功能,我们怎么搭建我们的数据平台的呢?
先看一下我们数据处理的主要步骤,首先是我们SDK采集数据,采集数据之后,首先把它扔到我们的消息队列里做一个基础
的持久化,之后我们会有两部分,一部分是实时统计,一部分是离线统计,这两部分统计完之后会把统计结果存下来,然后提
供给我们的查询服务,最后是我们外部展示界面。我们的数据平台主要基于中间的四个绿色的部分。
关于要求,对消息队列来说肯定是吞吐量一定要大,要非常好的扩展性,如果有一个消息的波峰的话要随时能够扩展,因为所
有的东西都是分布式的,所以要保证节点故障不会影响我们正常的业务。
我们的实时计算目前采用的是分钟级别的实时,没有精确到秒级,离线计算需要计算速度非常快,这两部分我们当初在考虑的
时候就选用了Spark,因为Spark本身既支持实时,又支持离线,而且相对于其他的实时的方案来说,像Flink或者是Storm和
Samza来说,我们不需要到秒级的这种实时,我们需要的是吞吐量,所以我们选择Spark。实时部分用的是Spark streaming,
离线部分用的是Spark offline的方案。
下载后可阅读完整内容,剩余6页未读,立即下载
2015-11-03 上传
2018-10-26 上传
2022-07-15 上传
2023-06-02 上传
2023-11-11 上传
2023-05-27 上传
2023-04-04 上传
2023-03-16 上传
2023-06-06 上传

weixin_38713586
- 粉丝: 3
- 资源: 933
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
