Ubuntu下快速搭建单机Hadoop环境教程
需积分: 9 175 浏览量
更新于2024-09-11
收藏 782KB DOC 举报
本文主要介绍了如何在一台计算机上进行Hadoop的单机部署。首先,作者强调了在Windows环境中安装Ubuntu Linux作为基础操作系统,推荐使用wubi.exe简易安装方法,尽管这种方法可能在安装过程中存在卡顿问题,但因其简便性而被选择。安装过程中需要注意重启时选择进入Ubuntu。
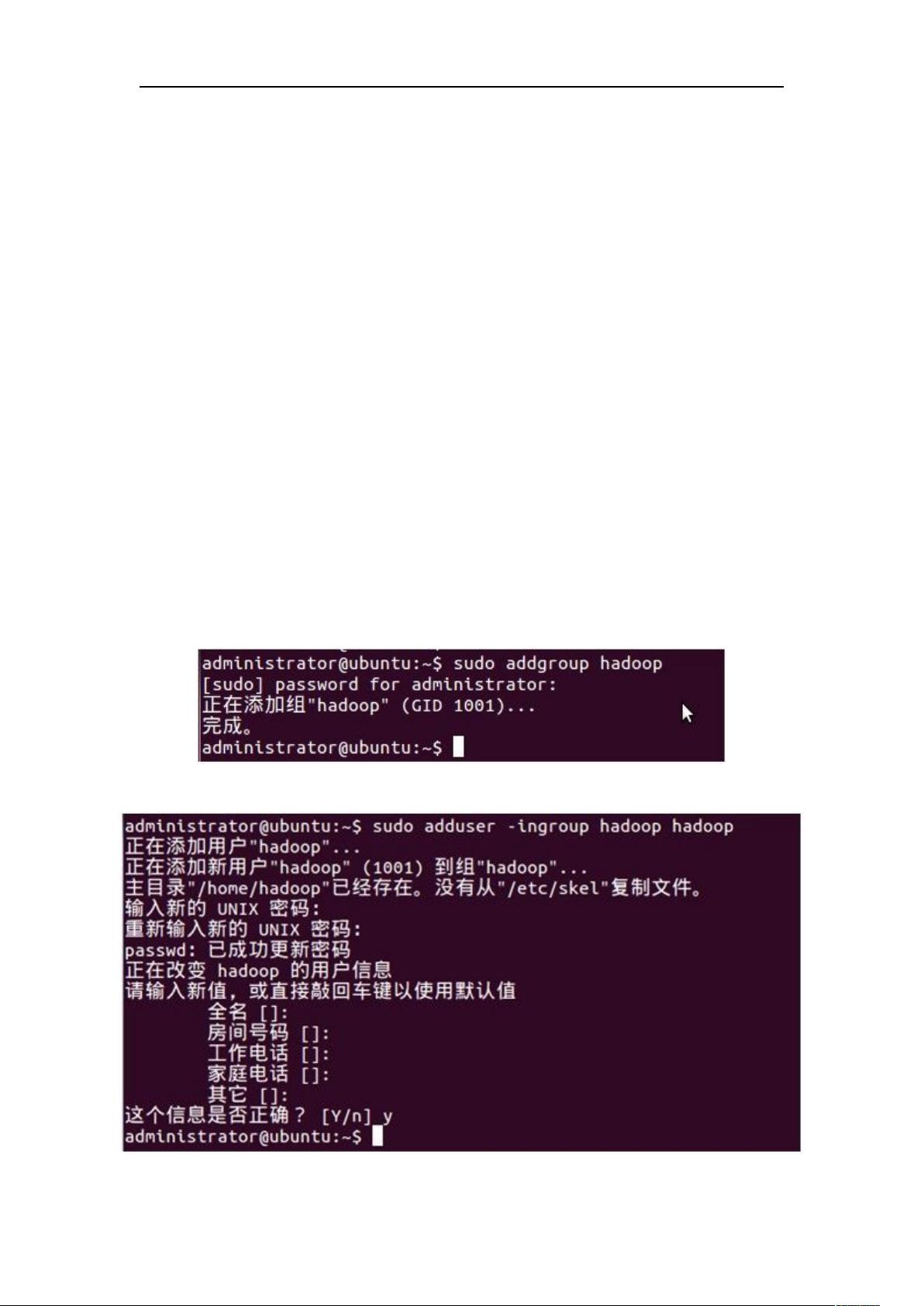
接着,文章详细指导如何在Ubuntu环境下创建专用的Hadoop用户组和用户,命名为"hadoop"。创建步骤包括:1) 使用"sudo addgroup hadoop"命令创建用户组,2) 使用"sudo useradd -g hadoop hadoop"创建用户,并确保用户拥有管理员权限。为了实现这一点,作者提到编辑/etc/sudoers文件,增加"hadoop ALL=(ALL:ALL)ALL"这一行,赋予hadoop用户root级别的权限。
核心部分在于安装Java Development Kit (JDK),因为Hadoop需要JDK支持。作者没有提供具体的URL链接,但提到了通过博客文章获取安装教程,建议读者查阅博主weixiaolu的iteye博客获取详细步骤。安装JDK对于Hadoop的运行至关重要,因为它提供了Hadoop MapReduce和HDFS(Hadoop Distributed File System)运行所需的Java环境。
最后,虽然文章没有详细说明,但在单机上运行Hadoop通常涉及配置Hadoop的环境变量、配置文件(如core-site.xml、hdfs-site.xml和mapred-site.xml),以及可能的Hadoop守护进程(如namenode、datanode和jobtracker)的启动。这些步骤完成后,用户就可以在本地测试Hadoop的运行,比如上传数据到HDFS,运行简单的MapReduce任务。
本文为初学者提供了一个从零开始在单机上配置Hadoop环境的基础指南,包括操作系统选择、用户管理、JDK安装以及后续的基本配置流程。
在弹出的窗口中设置一些具体的参数,自动跟新完成后需要重启。重启时,就
会出现 ubuntu 系统的选择了,系统一般默认开机启动 windows 系统,所以
这里要自己手动选择哦~,进入 ubuntu 后,系统就自动下载,跟新、安装了。
(注:安装的过程中可能会卡在一个阶段很长时间(我卡了半个小时),这时
我选择了强制关机,重启时同样选择进入 ubuntu。一般第二次就不会卡,具
体原因我也不是很清楚,可能和 wubi.exe 程序有关吧。 在网上看到,有些人
认为用 wubi.exe 安装 ubuntu 不是很好,可能这就是它的不好之处吧。不过
这是非常简单的方法,所以我们还是选择这种安装方法吧。)
二、在 Ubuntu 下创建 hadoop 用户组和用户
这里考虑的是以后涉及到 hadoop 应用时,专门用该用户操作。用户组名和用
户名都设为:hadoop。可以理解为该 hadoop 用户是属于一个名为 hadoop
的用户组,这是 linux 操作系统的知识,如果不清楚可以查看 linux 相关的书
籍。
1、创建 hadoop 用户组,如图(3)
2、
创建
hadoop 用户,如图(4)
剩余12页未读,继续阅读
2013-08-27 上传
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传
2024-12-27 上传

yangyan21
- 粉丝: 0
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | mtgpu-0.2.5-py3-none-any.whl
- endpoint-testing-afternoon:一个下午的项目,以帮助使用Postman巩固测试端点
- 经济中心
- z7-mybatis:针对mybatis框架的练习,目前主要技术栈包含springboot,mybatis,grpc,swgger2,redis,restful风格接口
- Cloudslides-Android:云幻灯同步演示应用-Android Client
- testingmk:做尼采河
- ecom-doc-static
- kindle-clippings-to-markdown:将Kindle的“剪贴”文件转换为Markdown文件,每本书一个
- 减去图像均值matlab代码-TVspecNET:深度学习的光谱总变异分解
- 自动绿色
- Alexa-Skills-DriveTime:该存储库旨在演示如何建立ALEXA技能,以帮助所有人了解当前流量中从源头到达目的地所花费的时间
- 灰色按钮克星易语言版.zip易语言项目例子源码下载
- HTML5:基本HTML5
- dubbadhar-light
- 使用Xamarin Forms创建离线移动密码管理器
- matlab对直接序列扩频和直接序列码分多址进行仿真实验源代码
