Kafka万亿消息实践:资源组流量掉零故障分析
版权申诉
71 浏览量
更新于2024-08-07
收藏 885KB DOC 举报
"Kafka 万亿级消息实践之资源组流量掉零故障排查分析"
本文主要探讨了在处理万亿级消息的Kafka集群中遇到的一个典型故障——资源组流量突然降至零的问题,以及如何进行故障排查和分析。作者是vivo互联网服务器团队的LuoMingbo。
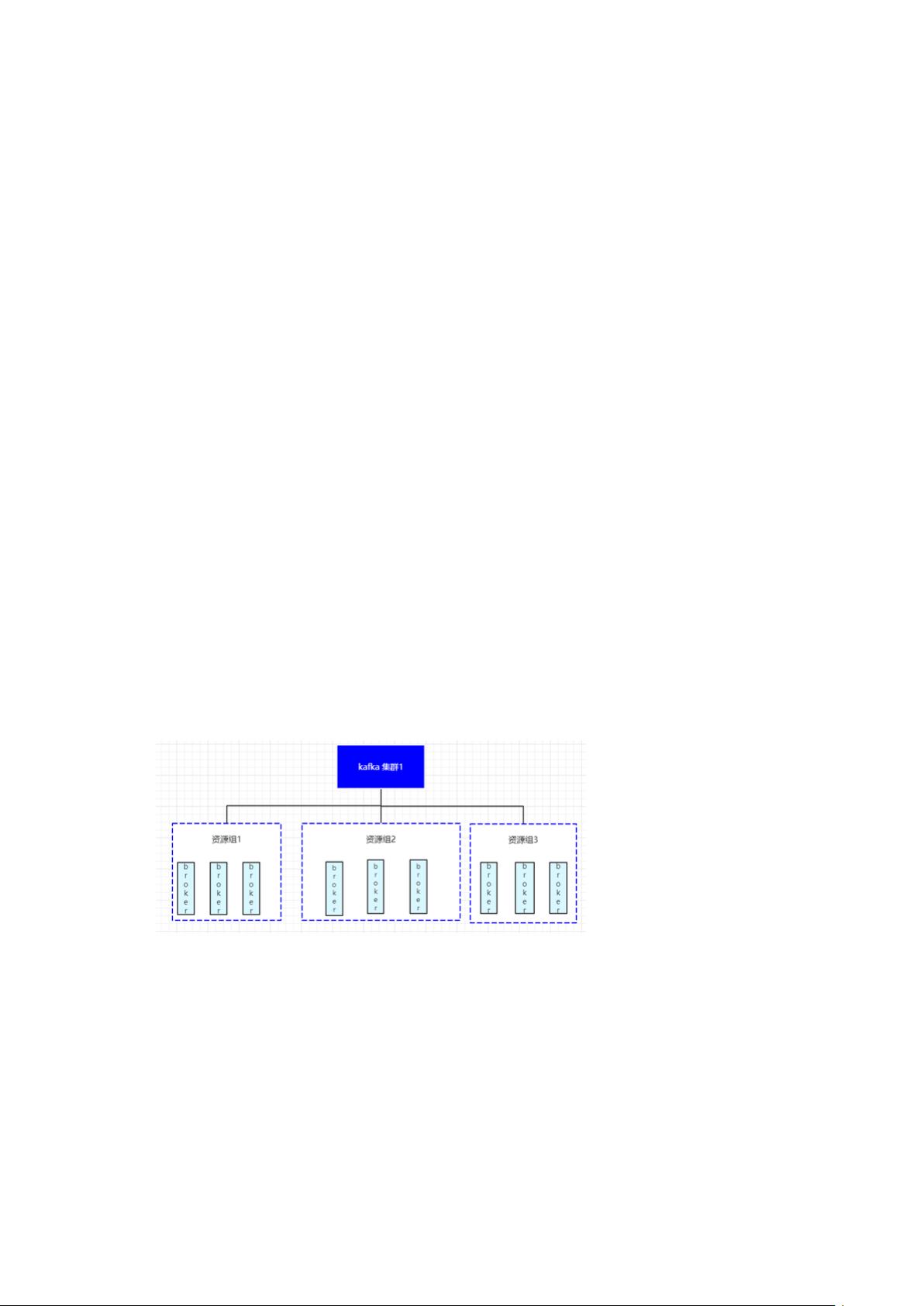
首先,文章介绍了Kafka集群的部署架构。为了管理和维护的效率,以及提高系统的稳定性和可用性,他们将大型Kafka集群按业务维度划分为多个小集群。每个集群内部,进一步采用了“资源组”的逻辑概念,使得节点共享资源,同时在组间保持资源隔离,以防止故障扩散。资源组的设计考虑了流量突变、资源隔离和限速等因素,以增强抗风险能力。
接着,文中阐述了业务接入Kafka集群的流程。业务方需要在Kafka平台上注册项目,根据数据的重要性来决定是否创建独立的资源组。创建topic时,必须遵循严格的分区分布规则,确保topic的分区只存在于指定的资源组内的broker节点上。此外,还需进行权限设置,确保读写操作的安全性。
然后,作者描述了故障的具体情况。在故障发生时,涉及的资源组内的多个topic流量突然几乎全部消失。为了分析问题,通常会关注Kafka集群的磁盘指标,如READ、WRITE、IO.UTIL、AVG等,这些指标对于理解系统性能和可能的瓶颈至关重要。
故障排查通常会涉及以下几个关键步骤:
1. **监控检查**:查看系统日志、性能监控数据,确定故障发生的时间点和具体表现。
2. **网络检查**:检查网络连接是否正常,是否存在网络中断或拥塞的情况。
3. **资源瓶颈**:分析磁盘I/O、CPU、内存使用情况,确认是否存在资源耗尽导致的问题。
4. ** broker状态**:检查受影响的broker节点是否正常运行,包括进程状态、分区分配等。
5. **客户端行为**:分析生产者和消费者的日志,看是否有异常行为或错误提示。
6. **配置审查**:复查Kafka配置,确认是否有可能导致流量波动的参数设置。
在排查过程中,可能需要采取的解决措施包括但不限于调整资源分配、优化配置、修复网络问题、重启服务或升级系统。通过这种逐步深入的分析,可以定位到问题的根源,并提出有效的解决方案。
Kafka在处理大规模消息场景中的稳定性是至关重要的,而资源组的设计是保证这一稳定性的重要手段。通过对故障的深入分析,不仅可以解决当前问题,也能为未来的系统优化和故障预防提供宝贵经验。
Kafka 万亿级消息实践之资源组流量掉零故障排查分析
本篇对在 kafak 万亿消息实践中一次典型的故障进行详细分析和说明。深入到 kafka
架构原理层分析故障出现的根因及对应的解决方案。
笔者:vivo 互联网服务器团队-Luo Mingbo
一、Kafka 集群部署架构
为了让读者能与小编在后续的问题分析中有更好的共鸣,小编先与各位读者朋友对齐一下
我们 Kafka 集群的部署架构及服务接入 Kafka 集群的流程。
为了避免超大集群我们按照业务维度将整个每天负责十万亿级消息的 Kafka 集群拆分成
了多个 Kafka 集群。拆分粒度太粗会导致单一集群过大,容易由于流量突变、资源隔离、
限速等原因导致集群稳定性和可用性受到影响,拆分粒度太细又会因为集群太多不易维护,
集群内资源较少应对突发情况的抗风险能力较弱。
由于 Kafka 数据存储和服务在同一节点上导致集群扩缩容周期较长,遇到突发流量时不
能快速实现集群扩容扛住业务压力,因此我们按照业务维度和数据的重要程度及是否影响商
业化等维度进行 Kafka 集群的拆分,同时在 Kafka 集群内添加一层逻辑概念“资源组”,资
源组内的 Node 节点共享,资源组与资源组之间的节点资源相互隔离,确保故障发生时不
会带来雪崩效应。
二、业务接入 Kafka 集群流程
在 Kafka 平台注册业务项目。
若项目的业务数据较为重要或直接影响商业化,用户需申请创建项目独立的资源组,若项
目数据量较小且对数据的完整性要求不那么高可以直接使用集群提供的公共资源组无需申
下载后可阅读完整内容,剩余8页未读,立即下载
2020-11-05 上传
2020-10-27 上传
2020-07-28 上传
2020-11-11 上传
2019-09-27 上传
2023-04-20 上传
2021-10-12 上传
2023-07-10 上传
2021-06-10 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
