Hadoop小文件挑战与深度解决方案探析
17 浏览量
更新于2024-06-17
收藏 1.73MB PDF 举报
Hadoop中的小文件问题与解决方案探讨的是Apache Hadoop这一开源软件库在处理大规模数据集时遇到的一种挑战。Hadoop生态系统的两大关键组件,Hadoop分布式文件系统(HDFS)和MapReduce,专为高效处理大文件设计,但在面对文件大小远小于HDFS默认块大小的情况时,性能会显著下降。小文件问题主要表现在它们占用过多的存储空间,消耗独立的磁盘块,导致内存需求增加、访问时间延长和处理效率低下。
文章首先介绍了背景,强调了随着大数据时代的到来,计算范式也在不断演进,这对Hadoop提出了更高的性能要求。系统性文献综述被选为研究方法,因为这样能够全面理解和评估小文件问题的严重性以及现有的解决方案。作者详细阐述了文献综述的目的,包括提出的问题、搜索策略(可能涵盖了学术数据库、会议论文和相关研究报告)、入选和排除的标准,以及文章的筛选过程。
研究的核心部分是构建了一个关于Hadoop生态系统的分类框架,将问题划分为不同的类别,以便更好地理解问题的各个方面。这可能包括了小文件产生的原因、影响性能的具体指标、以及现有解决策略的优缺点。通过深入分析,文章旨在找出一套优化参数,以指导未来针对小文件问题的新解决方案的设计。
本文的贡献在于提供了对Hadoop小文件问题的深入剖析,以及对当前解决方案的批判性评估,这对于改进Hadoop的性能,提升大数据处理效率具有实际意义。值得注意的是,本文遵循了开放获取的CC BY-NC-ND许可证,这意味着读者可以在规定的条件下自由地使用和分享文章的内容。
总结来说,这篇文章深入探讨了Hadoop小文件问题的根源、影响,以及如何通过系统性文献综述来理解并寻求解决方案。对于Hadoop用户和开发者来说,这篇论文提供了一个宝贵的参考资源,帮助他们优化系统配置,提高处理小文件时的性能。
R. Aggarwal
,
J.Verma
和
M.
锡瓦赫
沙特国王大学学报
8661
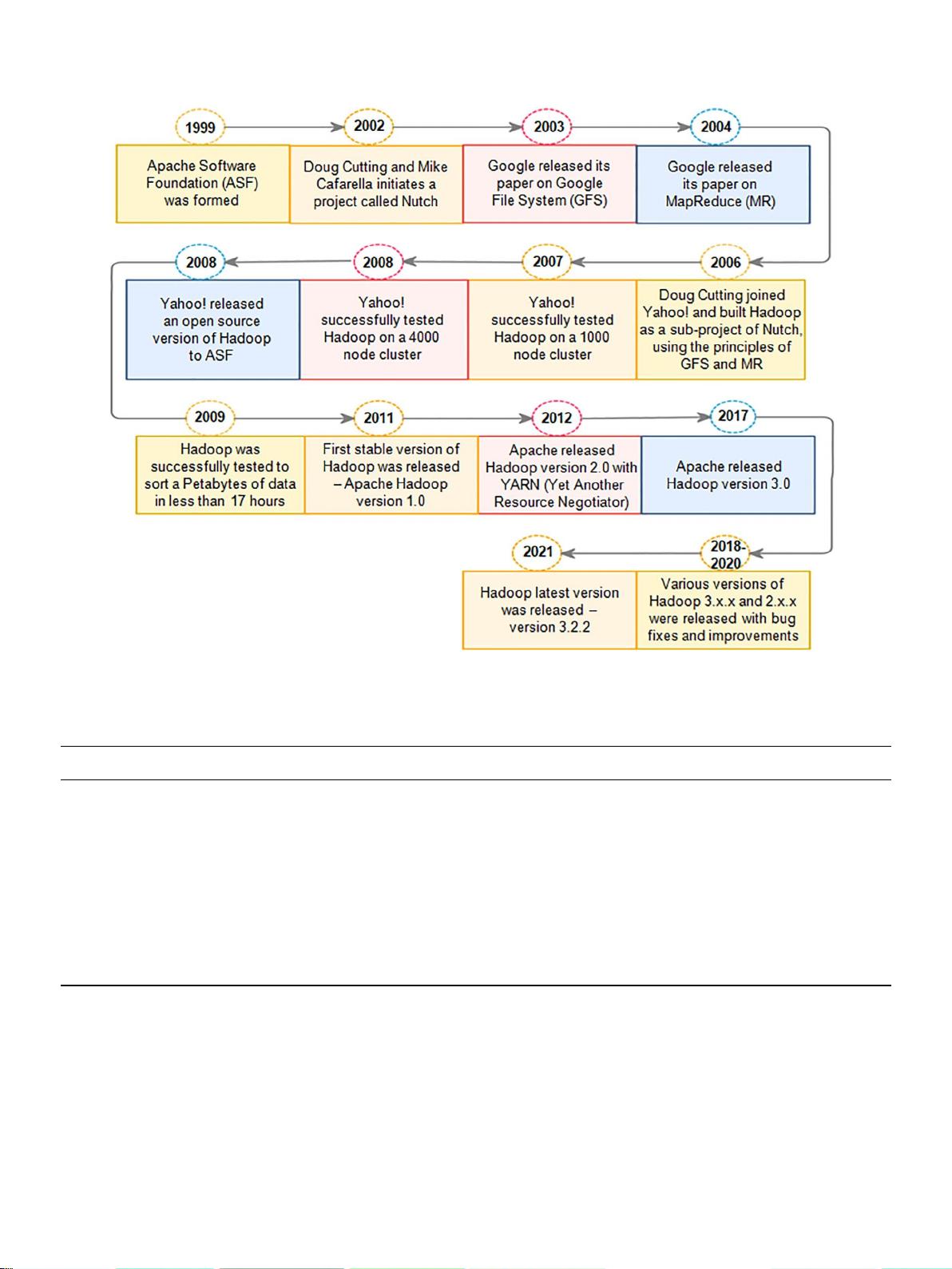
图二
. Hadoop
的演变
表
1
小档案问题的相关调查
参考
发行年
份
覆盖时期
Taxonomy
综合分析
未来方向
重点
(Masadeh等人, 2020
年)
2020
2012–2019
不
有限
不可用
-
描述少数本地和拟议的
可用
解决方案
(
Alange Mathur
,
2019
)
2019
2009–2019
不
中度
不可用
-
现有技术的比较研究
可用
(
El-Sayed
等人,
2019
年
a
、
b
)
2019
2009–2017
不
有限
不可用
- Hadoop
中小文件的影响
可用
(
Huang
等人,
2018
年)
2018
2009–2017
不
中度
中度
- Hadoop
中小文件的影响
可用
-
详细介绍可用的
(Rathidevi Srinivasan,
2018
2008–2017
不
中度
有限
技术
-
现有技术的比较研究
2018
年)
可用
(英迪拉,
2017
年)
2017
2009–2016
不
中度
不可用
- Hadoop
中小文件的影响
可用
4.3.
综述方案
4.3.1.
搜索策略
本文的主要工作是了解
Hadoop
的体系结构,并在此基础上研究
Hadoop
中的小文件为了实现这一目标,从各种来源检索了该领域发
表的大量文章对于初始水平,在以下电子研究数据库中进行了广泛
的 文 献 检 索 :
Elsevier
、
IEEE Xplore
、
ACM
数 字 图 书 馆 、
Springer
和
Google Scholar
。除上述资料库外,还考虑了其他一些
资料来源,如会议记录、讲习班和专题讨论会。的
关键词被仔细识别并基于相似性被分成四组第一组关键词围绕着用于
研究工作中提出的策略的各种形容词第二组关键字由与处理小文件有
关的词组成第三组本身包含
“
小文件
”
的关键字。最后,第四组包含与
托管小文件的平台问题有关的关键字。虽然本文的重点是
Hadoop
平
台,但很多文章都讨论了云或其他分布式文件系统中的小文件。因
此,这些关键词被包括在这一组中,以便不失去一些可以从这些文章
中得出的主要见解。使用各种已识别关键字的仔细组合,
剩余17页未读,继续阅读
点击了解资源详情
2016-02-29 上传
2019-01-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- VxWorks操作系统板级支持包的设计与实现
- Vx Works环境下串口驱动程序设计
- Vx Works环境下IP-CATV网关驱动程序的设计与实现
- Linux与VxWorks的板级支持包开发的比较与分析
- 基于公共机房安排管理系统
- ISaGRAF在SUPMAX500组态软件中的应用
- Ipv6高级套接口的研究和实现
- HTTP在嵌入式系统中的应用及扩展
- Oracle9i数据库管理实务讲座.pdf
- PL/SQL程序設計pdf格式
- CDN网络路由技术CDN网络路由技术
- 1700mm精轧机组液压AGC程序包变量监控
- 4种实时操作系统实时性的分析对比
- DOM文档对象模型(微软最近教程)
- c与c++嵌入式系统编程.pdf
- oracle傻瓜手册
