HDFS操作详解:分布式文件系统原理与实践
下载需积分: 5 | DOCX格式 | 1.16MB |
更新于2024-06-14
| 201 浏览量 | 举报
"本资源主要介绍了大数据技术中HDFS(Hadoop Distributed File System)的基本概念和工作原理,以及HDFS的关键特性。实验2重点在于熟悉HDFS的常用操作,包括分布式文件系统设计的需求、高扩展性实现、块的概念、名称节点和数据节点的功能,以及中心节点(名称节点)的设计挑战。"
在大数据分析领域,HDFS是一个关键组件,它是一个分布式文件系统,设计用于处理和存储海量数据。HDFS的核心设计原则是满足大规模数据处理的需求,这包括以下几个方面:
1. **透明性**:HDFS提供了访问透明性,允许用户通过统一的接口访问本地和远程文件,但不完全实现位置、性能和伸缩透明性。
2. **并发性**:系统支持多个客户端同时读取或写入文件,但写操作仅允许一个客户端进行,以保证数据一致性。
3. **文件复制**:HDFS采用多副本策略,每个文件都有多个副本分布在不同的节点上,增强了数据的可用性和容错性。
4. **异构性**:HDFS使用JAVA编写,可在不同硬件和操作系统上运行,具备良好的跨平台性。
5. **可伸缩性**:HDFS允许节点动态加入或退出,随着集群规模的扩大,系统容量和性能随之提升。
6. **容错性**:通过多副本和故障检测恢复机制,HDFS能够在节点故障时保证服务的连续性。
7. **安全性**:尽管HDFS的安全性相对较弱,但在实际部署中通常会结合其他安全机制如Kerberos进行增强。
分布式文件系统实现高扩展性的方法是将文件分割成块并分散存储在多台计算机上,形成计算机集群。HDFS中的块通常远大于传统文件系统的块,这减少了寻道时间,提高了数据传输效率。
HDFS包含两个核心组件:名称节点(NameNode)和数据节点(DataNode)。名称节点负责元数据管理,包括文件和目录的创建、删除、重命名,以及维护文件到数据块的映射关系。数据节点则实际存储数据,执行数据的读写操作。
为了减轻中心节点(名称节点)的负担,HDFS设计时避免了名称节点参与数据传输,仅处理元数据操作。然而,这种设计也带来了局限性:
- **命名空间限制**:名称节点的内存限制了它可以管理的对象数量。
- **性能瓶颈**:整个系统的吞吐量受到单个名称节点性能的制约。
- **隔离问题**:所有应用程序共享同一个命名空间,难以实现资源隔离。
- **集群可用性**:名称节点的单点故障可能导致整个系统不可用,需通过HA(高可用性)或 Federation 解决。
理解这些基本概念和挑战对于有效地利用HDFS进行大数据分析至关重要。在实际操作中,用户需要掌握如何在HDFS上执行文件操作,同时关注如何优化和扩展系统以应对不断增长的数据需求。
“大数据技术原理与应用”课程实验报告
实验 2 熟悉常用的 HDFS 操作 姓名: 日期:2024/3/21
一、实验目的
(1)理解 HDFS 在 Hadoop 体系结构中的角色
(2)熟练使用 HDFS 操作常用的 Shell 命令。
(3)熟悉 HDFS 操作常用的 Java API。
二、实验平台
操作系统:Ubuntu 18.04
Hadoop 版本:3.1.3
JDK 版本:1.8
Java IDE: Eclipse
三、实验内容与完成情况:
(1) 编程实现以下指定功能,并利用 Hadoop 提供的 Shell 命令完成相同的任
务。
①向 HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,由用户指定是追
加到原有文件末尾还是覆盖原有文件。
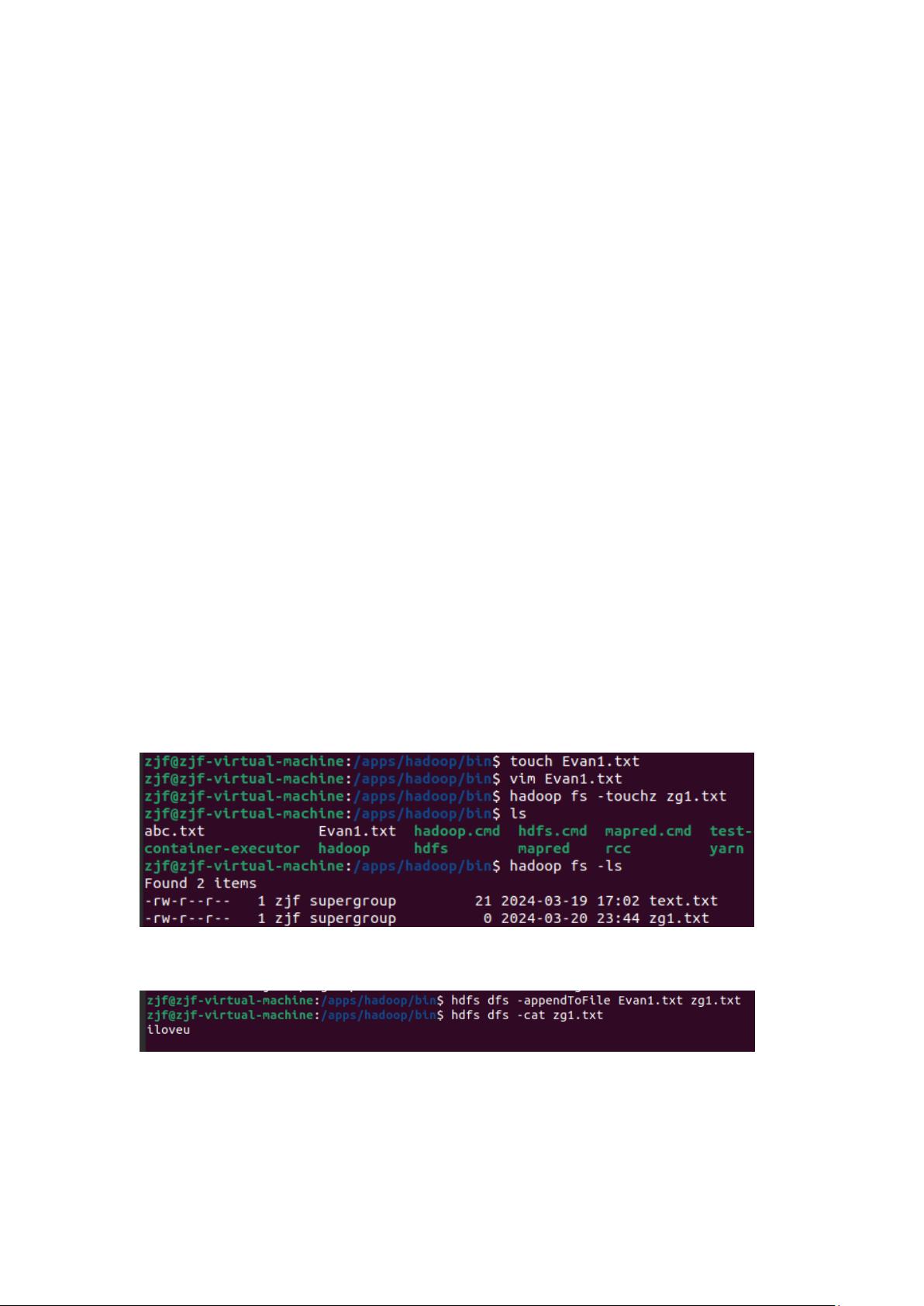
创建本地文件 Evan1.txt,写入文本 iloveu,创建 hadoop 文件 zg1.txt;
将 Evan1.txt 追加到 zg1.txt 末尾,查看 zg1.txt 文件;
检查 HDFS 中是否存在名为 zg2.txt 的文件;
如果 zg2.txt 存在,则将本地文件 Evan1.txt 的内容追加到 HDFS 中的 zg2.txt 文件中;
如果 Evan1.txt 不存在,则将本地文件 Evan1..txt 拷贝到 HDFS 中,并命名为 zg2.txt。
查看 zg2.txt 文件
剩余17页未读,继续阅读
相关推荐





深蓝-DeepBlue
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安装Oracle必备:unixODBC-2.2.11-7.1.x86_64.rpm
- Spring Boot与Camel XML聚合快速入门教程
- React开发新工具:可拖动、可调整大小的窗口组件
- vlfeat-0.9.14 图像处理库深度解析
- Selenium自动化测试工具深度解析
- ASP.NET房产中介系统:房源信息发布与查询平台
- SuperScan4.1扫描工具深度解析
- 深入解析dede 3.5 Delphi反编译技术
- 深入理解ARM体系结构及编程技巧
- TcpEngine_0_8_0:网络协议模拟与单元测试工具
- Java EE实践项目:在线商城系统演示
- 打造苹果风格的Android ListView实现与下拉刷新
- 黑色质感个人徒步旅行HTML5项目源代码包
- Nuxt.js集成Vuetify模块教程
- ASP.NET+SQL多媒体教室管理系统设计实现
- 西北工业大学嵌入式系统课程PPT汇总
