C++实现经典排序算法详解
需积分: 5 94 浏览量
更新于2024-08-04
收藏 1.89MB PDF 举报
"C++编程语言中的排序算法是数据结构与算法学习的重要部分,涉及到的排序算法包括冒泡排序、选择排序、插入排序、希尔排序、堆排序、快速排序和归并排序。这些算法各有特点,如稳定性、平均时间复杂度、最好情况和最坏情况的时间复杂度以及空间复杂度。
冒泡排序是一种简单的排序方法,它通过重复遍历数组,每次比较相邻元素并根据需要交换它们来排序。其稳定性的特点是,相等的元素在排序过程中不会改变它们的相对位置。冒泡排序的平均时间复杂度为O(n^2),最好的情况是已排序的数组,只需进行n-1次比较,最坏的情况是逆序数组,需要进行n*(n-1)/2次比较。优化后的冒泡排序可以在未发生交换的情况下提前结束,但最坏时间复杂度依然为O(n^2)。
选择排序的基本思想是在每一轮中找到未排序部分的最小值(或最大值),将其放到已排序部分的末尾。选择排序是不稳定的,因为它可能会改变相等元素的相对位置。无论输入顺序如何,选择排序的平均和最坏时间复杂度都是O(n^2)。
插入排序的工作方式类似于玩扑克牌,每次将一个未排序的元素插入到已排序的部分。插入排序是稳定的,因为相等元素的相对位置保持不变。其时间复杂度在最好情况(已排序数组)下为O(n),最坏情况(逆序数组)下为O(n^2),平均情况为O(n^2)。
希尔排序是一种改进的插入排序,通过增量序列分组元素进行插入排序,然后逐步减小增量直到为1。其时间复杂度依赖于增量序列的选择,通常介于O(n)到O(n^2)之间,但不是稳定的排序算法。
堆排序利用了二叉堆的数据结构,可以在O(n log n)的时间复杂度内完成排序,但它是不稳定的,因为排序过程中可能会交换相等元素。
快速排序是一种非常高效的排序算法,采用分治策略,选取一个“基准”元素,将数组分为小于和大于基准的两部分,然后对这两部分递归地进行快速排序。快速排序的平均时间复杂度为O(n log n),但最坏情况下(已排序或逆序数组)的时间复杂度为O(n^2),不过这种情况在实际应用中很少出现。
归并排序则通过将数组分成两半,分别排序,然后合并两个已排序的子数组来实现。它具有O(n log n)的时间复杂度,且是稳定的排序算法,适合处理大数据集。
掌握这些经典的排序算法不仅有助于理解数据结构和算法,也是面试和实际项目中解决问题的基础。通过C++实现这些排序算法并理解其工作原理,可以提升编程能力。建议练习编写和理解每种排序算法的代码,以便更好地掌握它们的精髓。"
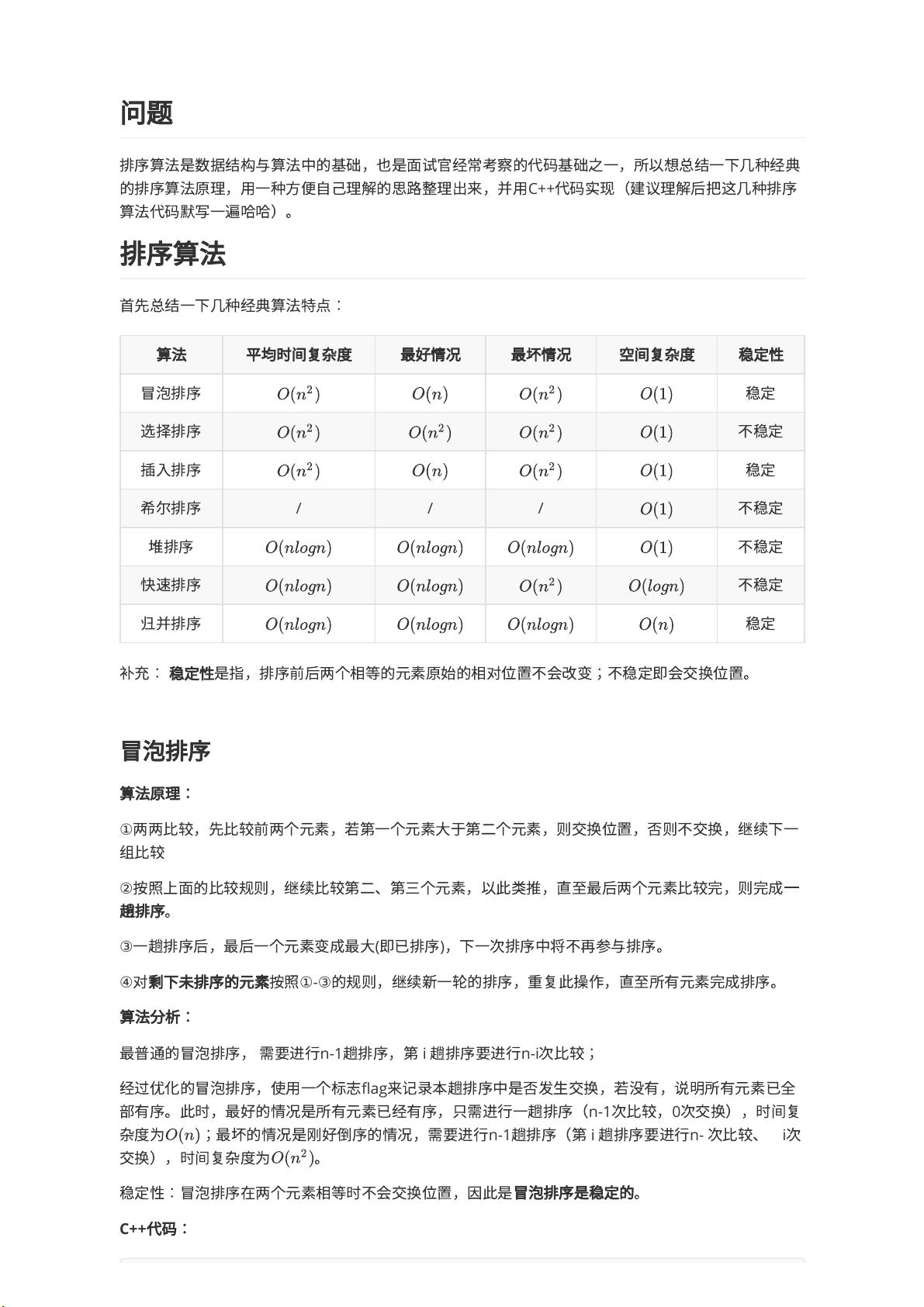
算
法
平
均
时
间
复
杂
度
最
好
情
况
最
坏
情
况
空
间
复
杂
度
稳
定
性
冒
泡
排
序
稳
定
选
择
排
序
不
稳
定
插
⼊
排
序
稳
定
希
尔
排
序
/ / /
不
稳
定
堆
排
序
不
稳
定
快
速
排
序
不
稳
定
归
并
排
序
稳
定
问
题
排
序
算
法
是
数
据
结
构
与
算
法
中
的
基
础
,
也
是
⾯
试
官
经
常
考
察
的
代
码
基
础
之⼀
,
所
以
想
总
结
⼀下
⼏
种
经
典
的
排
序
算
法
原
理
,
⽤
⼀
种
⽅
便
⾃
⼰
理
解
的
思
路
整
理
出
来
,
并
⽤
C++
代
码
实
现
(
建
议
理
解
后
把
这
⼏
种
排
序
算
法
代
码
默
写
⼀
遍
哈哈
)
。
排
序
算
法
⾸
先
总
结
⼀下
⼏
种
经
典
算
法
特
点
:
补
充
:
稳
定
性
是
指
,
排
序
前
后
两个
相
等
的
元
素
原
始
的相
对
位
置
不
会
改
变
;
不
稳
定
即
会
交
换
位
置
。
冒
泡
排
序
算
法
原
理
:
①
两两
⽐
较
,
先
⽐
较
前
两个
元
素
,
若
第
⼀个
元
素
⼤
于
第
⼆
个
元
素
,
则
交
换
位
置
,
否
则
不
交
换
,
继续
下⼀
组
⽐
较
②
按
照
上
⾯
的
⽐
较
规
则
,
继续
⽐
较
第
⼆
、
第
三个
元
素
,
以
此
类
推
,
直
⾄
最
后
两个
元
素
⽐
较
完
,
则
完
成
⼀
趟
排
序
。
③
⼀
趟
排
序
后
,
最
后
⼀个
元
素
变
成
最
⼤
(
即
已
排
序
)
,
下⼀
次
排
序
中
将
不
再
参
与
排
序
。
④
对
剩
下
未
排
序
的
元
素
按
照
①-③
的
规
则
,
继续
新
⼀
轮
的
排
序
,
重
复
此
操
作
,
直
⾄
所
有
元
素
完
成
排
序
。
算
法
分
析
:
最
普
通
的
冒
泡
排
序
,
需
要
进
⾏
n-1
趟
排
序
,
第
i
趟
排
序
要
进
⾏
n-i
次
⽐
较
;
经
过
优
化
的
冒
泡
排
序
,
使
⽤
⼀个
标
志
flag
来
记
录
本
趟
排
序
中
是
否发
⽣
交
换
,
若
没
有
,
说
明
所
有
元
素
已
全
部
有
序
。
此
时
,
最
好
的
情
况
是
所
有
元
素
已
经
有
序
,
只
需
进
⾏
⼀
趟
排
序
(
n-1
次
⽐
较
,
0
次
交
换
),
时
间
复
杂
度
为
;
最
坏
的
情
况
是
刚
好
倒
序
的
情
况
,
需
要
进
⾏
n-1
趟
排
序
(
第
i
趟
排
序
要
进
⾏
n-i
次
⽐
较
、
n-i
次
交
换
),
时
间
复
杂
度
为
。
稳
定
性
:
冒
泡
排
序
在
两个
元
素
相
等
时
不
会
交
换
位
置
,
因
此
是
冒
泡
排
序
是
稳
定
的
。
C++
代
码
:
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-05-23 上传
2014-08-10 上传
2020-11-24 上传
2020-12-31 上传

SmartDemo
- 粉丝: 173
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
