Hive数据导入与管理
"Hive DML操作主要涉及数据导入、数据导出以及查询等关键功能。Hive不支持像传统数据库那样的更新或修改已存在数据的功能,因此一旦数据被导入,就不能直接修改,只能通过删除表或创建新表来处理。Hive提供了`LOAD DATA`命令用于数据导入,以及`INSERT`语句进行数据插入。此外,Hive还支持数据的导出操作,将查询结果输出到本地或HDFS。"
在Hive中,`LOAD DATA`命令用于将数据加载到表中。有两种形式:`LOAD DATA LOCAL INPATH`和`LOAD DATA INPATH`。前者从本地文件系统加载数据,后者则直接从HDFS加载。`INPATH`后面跟的是文件或目录的路径。如果使用`OVERWRITE`选项,原有的表数据会被覆盖;否则,数据会被追加到现有数据后面。`INTO TABLE`指定加载的目标表,如果表有分区,还需要指定分区参数`PARTITION`。
例如,以下命令将本地文件系统中的数据加载到Hive表的特定分区中:
```sql
LOAD DATA LOCAL INPATH '/path/to/file' OVERWRITE INTO TABLE table_name PARTITION (part_col1=value1, part_col2=value2);
```
`INSERT`语句分为两种形式:`INSERT OVERWRITE`和`INSERT INTO`。`INSERT OVERWRITE`会清除目标表或分区中的原有数据,然后插入新数据;`INSERT INTO`则会在保留原有数据的基础上添加新数据。`INSERT`语句可以与`SELECT`语句结合,从一个表中选择数据并插入到另一个表中。
例如,以下命令将`table2`中的数据插入到`table1`中:
```sql
INSERT INTO TABLE table1 SELECT * FROM table2;
```
或者,如果要覆盖`table1`的所有数据:
```sql
INSERT OVERWRITE TABLE table1 SELECT * FROM table2;
```
数据导出是Hive的另一个重要功能,通常使用`INSERT OVERWRITE DIRECTORY`命令。这会清空指定目录,然后将查询结果写入该目录。可以导出到本地文件系统或HDFS。例如:
```sql
INSERT OVERWRITE LOCAL DIRECTORY '/local/path' SELECT * FROM table_name;
```
除了Hive SQL命令,还可以通过Hadoop的命令行工具或Hive Shell将数据导出到本地。例如,使用Hadoop的`fs`命令或在Hive Shell中执行SQL语句并将结果重定向到文件。
Hive DML操作提供了基本的数据管理能力,包括数据导入、插入和导出,这些操作对于大数据处理和分析至关重要,尤其是在不支持数据更新的场景下。
Hive DML
数据导入数据导入
Hive不支持update的操作。数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。
load:加载数据到表:加载数据到表
load data [local] inpath ‘filepath’ overwrite | into table 表名 [partition (partcol1=val1,…)];
单纯的复制/移动:将 filepath 中指定的文件复制到目标文件所指定的目录中。如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新
文件所替代。其中:
load data:表示加载数据
local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表。
inpath:表示加载数据的路径
filepath:可以引用一个文件(这种情况下,Hive 会将文件移动到表所对应的目录中)或者是一个目录(在这种情况下,Hive 会将目录中的所有文件移动至表所对应的目录中)。
overwrite:表示覆盖(先将表中原有数据删除)表中已有数据,否则表示追加。
into table:表示加载到哪张表。加载的目标可以是一个表或者分区。如果表包含分区,必须指定每一个分区的分区名。
partition:表示上传到指定分区
示例:
示例:
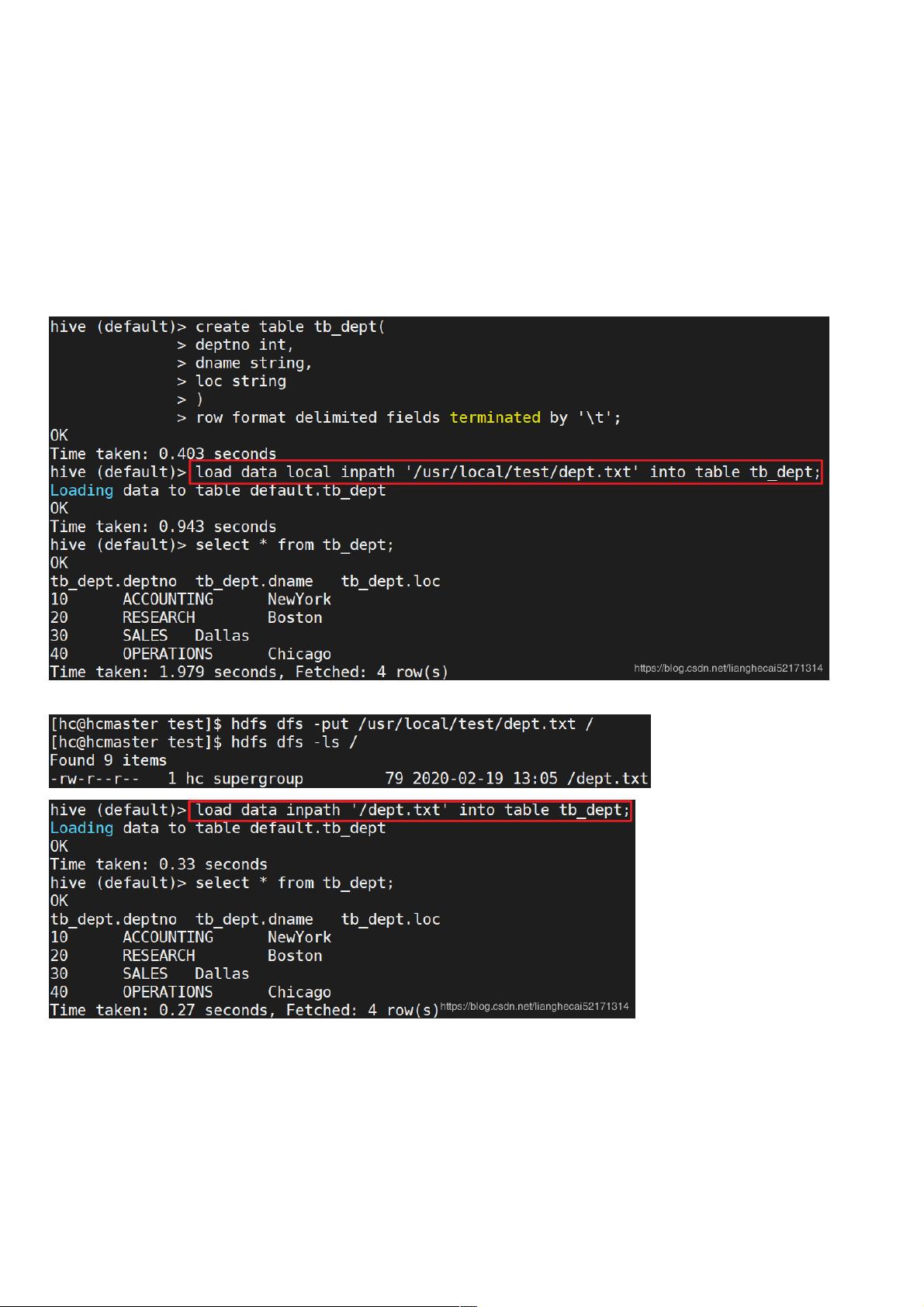
上传文件到HDFS
加载数据到Hive
示例:
下载后可阅读完整内容,剩余5页未读,立即下载
2024-05-31 上传
2024-09-13 上传
2024-10-15 上传
2024-10-17 上传
2023-06-02 上传
2024-10-31 上传

weixin_38562085
- 粉丝: 6
- 资源: 964
 我的内容管理
展开
我的内容管理
展开







最新资源
- 进程与线程的管理 .PPT 进程、线程和优先级
- 第10章 控件.PPT 通用控件的创建和使用
- PLSQL高级编程资料
- EMI-EMC设计秘籍
- 单片机编程实例教程内含代码
- Learning Compressed Sensing
- Linux进程管理教程.pdf
- dac8032资料 pdf
- MapXtreme2005简介.doc
- MapXtreme2004应用问答.txt
- Head.First设计模式_PDF79-107.pdfg高清中文版
- Head.First设计模式_PDF高清中文版37-78.pdf
- C语言程序设计100例
- Head.First设计模式_PDF高清中文版
- Oracle9i 数据库管理基础1.1.pdf
- linux内核完全注释--赵炯
