Lucene全文索引引擎:特性、应用与中文支持
需积分: 6 137 浏览量
更新于2024-09-20
收藏 38KB DOCX 举报
"Lucene是一个基于Java的全文索引工具包,用于实现全文检索功能。它不是一个独立的应用,而是一个可以嵌入到其他Java应用中的工具,由Doug Cutting创建,最初在www.lucene.com发布,后来成为Apache Jakarta项目的一部分。Lucene在Java社区中广泛使用,例如在Jive、Eyebrows、Cocoon和Eclipse等项目中都有应用。尽管不直接支持中文,但通过添加中文分词机制,可以实现对中文文本的全文检索。"
全文检索是一种强大的信息检索技术,它不仅查找精确匹配的关键词,还能找到与搜索词相关的文档。Lucene作为全文索引工具包,它提供了一套高效的索引和搜索算法,使得用户可以快速在大量数据中找到所需信息。
Lucene的核心组成部分包括索引器和搜索器。索引器负责读取原始文档,进行文本处理(如分词),并构建倒排索引,这是一种将词汇与文档对应关系反转的数据结构,极大地优化了搜索效率。搜索器则使用倒排索引来执行查询,找到包含指定关键词的文档。
在处理中文文本时,由于中文没有明显的空格分隔词,需要额外的分词机制。Lucene本身并不内置中文分词功能,但可以通过集成第三方的中文分词库(如HanLP、IK Analyzer或jieba分词)来处理中文文档。这些分词库采用词典匹配和自动切分算法,将中文文本拆分成可索引的词汇。
安装和使用Lucene时,首先需要下载最新版本的Lucene库,并将其引入到Java项目中。然后,根据应用需求编写代码,使用Lucene API进行索引和搜索操作。Lucene提供了诸如Document、Field、Analyzer等类,用于表示文档结构、字段类型和文本分析策略。此外,还可以通过自定义Analyzer实现特定的文本处理规则,比如定制中文分词策略。
Lucene的查询分析器可以简化用户输入的查询字符串,处理如拼写纠错、同义词扩展等功能。同时,Lucene还支持删除文档、定制排序逻辑以及扩展应用接口,以满足更复杂的需求。例如,通过实现Collector接口,可以自定义结果集的收集和处理方式。
对于需要更高性能或中文分词支持的场景,Sphinx是一个值得考虑的替代选项。Sphinx相比Lucene在速度上有优势,且内建了中文分词支持和简单的分布式检索功能,适合处理大规模数据和高并发的检索需求。
Lucene是一个强大且灵活的全文检索解决方案,它为Java开发者提供了丰富的工具和接口来实现自定义的全文检索功能。通过深入理解和利用Lucene,开发者可以为各种应用程序增添高效、精准的搜索体验。
所以建立一个高效检索系统的关键是建立一个类似于科技索引一样的反向索引机制,将数
据源(比如多篇文章)排序顺序存储的同时,有另外一个排好序的关键词列表,用于存储
关键词==>文章映射关系,利用这样的映射关系索引:H关键词==>出现关键词的文章编
号,出现次数(甚至包括位置:起始偏移量,结束偏移量),出现频率I,检索过程就是把
模糊查询变成多个可以利用索引的精确查询的逻辑组合的过程。从而大大提高了多关键词
查询的效率,所以,全文检索问题归结到最后是一个排序问题。
由此可以看出模糊查询相对数据库的精确查询是一个非常不确定的问题,这也是大部分数
据库对全文检索支持有限的原因。 最核心的特征是通过特殊的索引结构实现了传
统数据库不擅长的全文索引机制,并提供了扩展接口,以方便针对不同应用的定制。
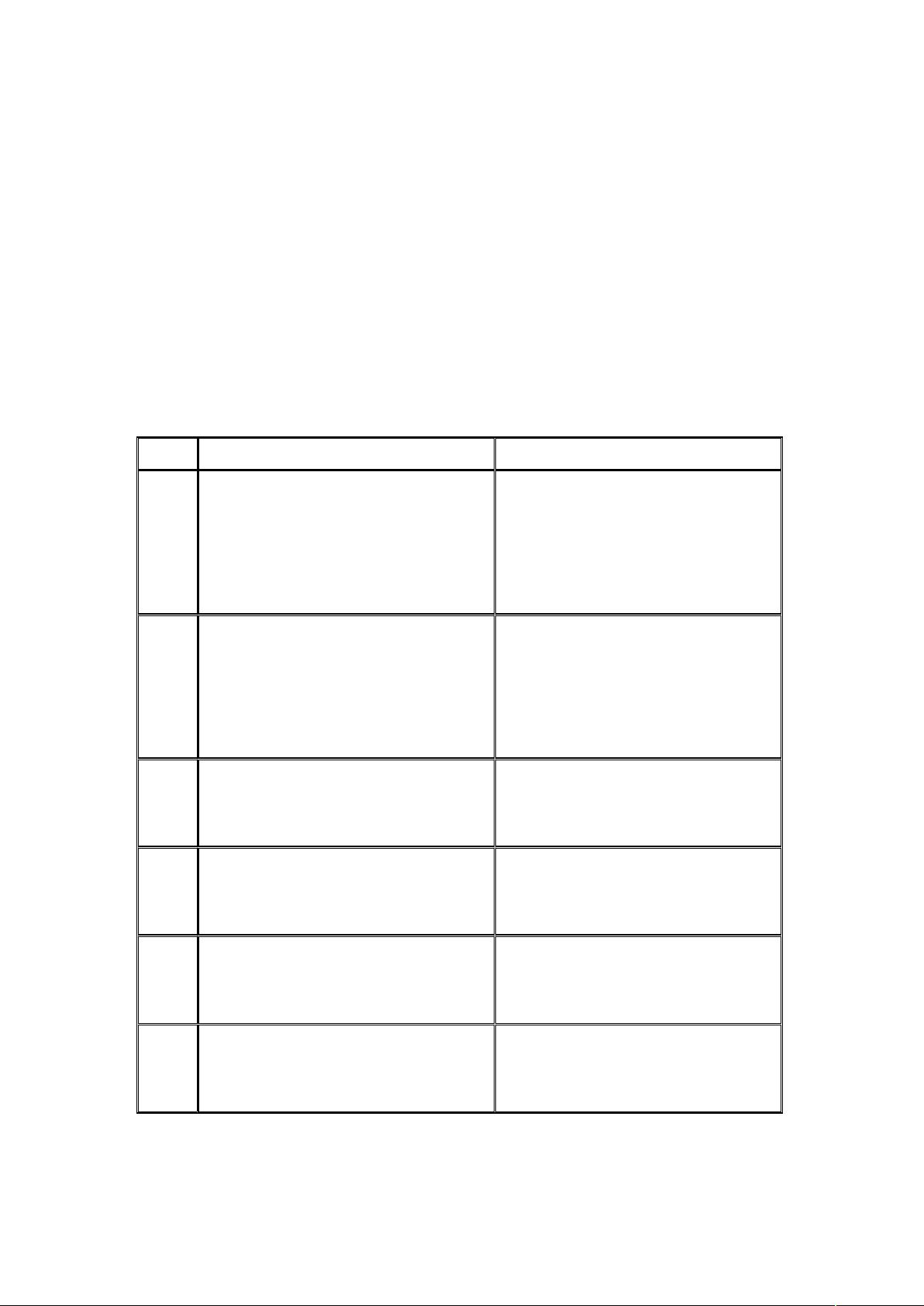
可以通过一下表格对比一下数据库的模糊查询:
全文索引引擎 数据库
索引
将数据源中的数据都通过全文索引
一一建立反向索引
对于 (E' 查询来说,数据传统的
索引是根本用不上的。数据需要逐
个便利记录进行 J*'/ 式的模糊匹
配,比有索引的搜索速度要有多个
数量级的下降。
匹配效
果
通过词元",+&进行匹配,通过语
言分析接口的实现,可以实现对中
文等非英语的支持。
使用:$FGGF会把
,$%6 也匹配出来,
多个关键词的模糊匹配:使用 $
FG+GGF:就不能匹配词
序颠倒的 +
匹配度
有匹配度算法,将匹配程度(相似
度)比较高的结果排在前面。
没有匹配程度的控制:比如有记录
中 出现 词和出现 次的,结
果是一样的。
结果输
出
通过特别的算法,将最匹配度最高
的头 .. 条结果输出,结果集是缓
冲式的小批量读取的。
返回所有的结果集,在匹配条目非
常多的时候(比如上万条)需要大
量的内存存放这些临时结果集。
可定制
性
通过不同的语言分析接口实现,可
以方便的定制出符合应用需要的索
引规则(包括对中文的支持)
没有接口或接口复杂,无法定制
结论
高负载的模糊查询应用,需要负责
的模糊查询的规则,索引的资料量
比较大
使用率低,模糊匹配规则简单或者
需要模糊查询的资料量少
全文检索和数据库应用最大的不同在于:让最相关的头 100 条结果满足 98%以上用户的
需求
剩余13页未读,继续阅读
2015-08-19 上传
2012-05-08 上传
2019-04-19 上传
2019-04-12 上传
2010-10-31 上传
2018-01-25 上传
1458 浏览量
2011-05-31 上传
2010-08-12 上传

duanqz
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
