Kafka理论详解:分布式消息队列在大数据实时处理中的关键
需积分: 3 9 浏览量
更新于2024-06-14
收藏 2.11MB PDF 举报
Kafka理论基础详解深入探讨了Apache Kafka这一分布式消息队列系统的核心概念和技术。Kafka最初由LinkedIn开发,现已成为大数据实时处理领域的重要工具。本教程由尚硅谷大数据研发部提供,版本更新至V2.1。
第1章概述了Kafka的基本定义,它是一种基于发布/订阅模式的消息传递系统,主要用于实时处理大规模数据。Kafka的主要特点是其分布式架构,支持高吞吐量、低延迟和可靠性,适用于异步处理和数据流处理场景。
1.2 节重点介绍了消息队列的应用场景和优势。在传统的应用场景中,消息队列常用于异步处理,如发送短信服务,通过将请求放入消息队列,即使处理延迟也不会阻塞用户操作。使用消息队列的好处包括:
- 解耦:通过消息队列,生产和消费过程可以独立扩展和修改,只需遵循统一的接口标准。
- 可恢复性:当系统部分组件故障时,不影响整体服务,提高系统的鲁棒性。
- 控制数据流速度:优化数据处理速度,解决生产与消费速度不一致的问题。
- 峰值处理能力:通过消息队列,应用可以在高峰期应对流量波动,避免资源浪费。
- 异步通信:消息队列支持非阻塞处理,允许用户按需处理消息,提高响应速度。
1.2.2 指出两种常见的消息队列模式:点对点模式(一对一,消费者主动拉取消息,消息消费后从队列中移除)和发布/订阅模式(一对多,消息发布到主题,所有订阅者都能接收,消息不被删除)。这两种模式在Kafka中分别对应Topic和Consumer Group的概念。
1.3 Kafka的基础架构涉及ZooKeeper(ZookeeperKeeper),在Kafka 0.9版本及其后续版本中,Zookeeper作为分布式协调服务,负责主题分区、消费者组管理等核心功能。Zookeeper为Kafka提供了配置存储、元数据管理以及节点间的通信同步。
总结来说,Kafka理论基础详解讲解了Kafka在大数据领域的核心价值,其分布式、可靠性和灵活的消息传递机制使其成为实时数据处理不可或缺的组件。学习者可以通过理解这些基础知识,掌握如何设计、实现和管理Kafka集群,以满足现代应用对高效数据流动和处理的需求。
尚硅谷大数据技术之 Kafka
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic first
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
--from-beginning:会把主题中以往所有的数据都读取出来。
6)查看某个 Topic 的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
hadoop102:2181 --describe --topic first
7)修改分区数
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
第 3 章 Kafka
hadoop102:2181 --alter --topic first --partitions 6
架构深入
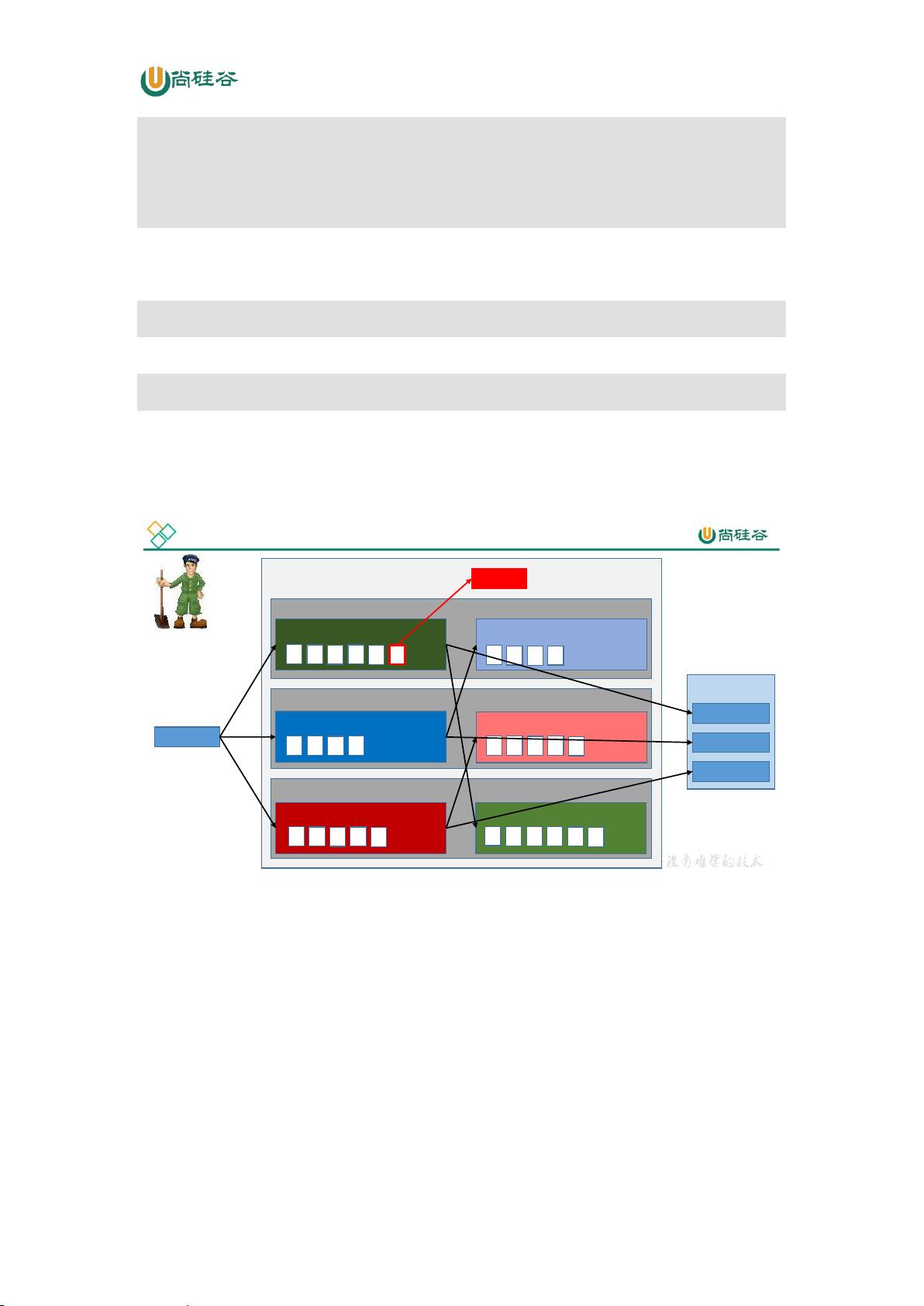
3.1 Kafka 工作流程及文件存储机制
offset
Zookeeper
group
Consumer
Consumer
Consumer
4
3
2
1
0
5
4
3
2
1
0
3
2
1
0
4
3
2
1
0
3
2
1
0
5
4
3
2
1
0
follower-partition0-TopicA
follower-partition2-TopicA
follower-partition1-TopicA
leader-partition2-TopicA
leader-partition1-TopicA
TopicA-partition0-leader
broker2
broker1
broker0
Kafka cluster
Producer
Kafka 工作流程
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic
的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文
件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该
log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己
消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
一个segment一个G
剩余35页未读,继续阅读
点击了解资源详情
136 浏览量
618 浏览量
2024-10-15 上传
点击了解资源详情
点击了解资源详情

做个专注的工程师
- 粉丝: 370
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSH整合资料(doc版)
- 人力资源 管理系统需求说明
- 学生成绩管理系统需求说明书
- Data Mining Practical Machine Learning Tools and Techniques Second Edition
- ireport图文教程
- LINUX 内核注释(PDF)
- 手写邮政编码的模糊识别方法
- PROTEUS中文教程
- 数据挖掘概念及技术系统学习教程
- 计算机类期刊中英文对照
- Weblogic管理指南
- java编写的: 编写程序,判断一个IP地址是否合法,并判断该地址是否属于一个给定的子网。
- java 编写的: 写一个程序来模拟网桥功能。
- IA-32卷3:系统编程指南[123457+11+12]
- 用java 编写的 ,编写一个计算机程序用来计算一个文件的16位效验和。最快速的方法是用一个32位的整数来存放这个和。
- java实验方法教程
