MySQL入门:编码问题详解与ASCII、GBK、Unicode发展史
161 浏览量
更新于2024-08-29
收藏 169KB PDF 举报
在MySQL入门教程的第四集中,主要探讨的是编程过程中的编码问题,因为正确理解和处理编码是程序员在开发过程中不可或缺的一部分。编码的产生是由于计算机内部仅支持二进制的0和1,而人类使用的字符和信息则更为复杂,因此需要通过人为的方式进行映射。
首先,让我们回顾编码发展的历程。ASCII码(American Standard Code for Information Interchange)作为最早的编码标准,由美国制定,用于表示英文字符,它占用一个字节,共256个编码位置,其中[0-127]用于英文字符,剩下的可用于扩展。然而,ASCII码无法满足中文汉字的需求,因为汉字数量庞大,ASCII码仅能覆盖大约128种字符。
为解决这个问题,GB2312编码应运而生。它采用了两个字节的模式,增加了对中文字符的支持,特别是将中文字符的范围设在[129-255],确保了与ASCII的兼容性,虽然识别中文的数量减少,但足以涵盖常用汉字,但一些不常见的汉字则无法被识别,因此产生了后续的GBK编码。
GBK编码进一步扩展了字符集,允许第二个字节使用ASCII的范围,这样可以更准确地区分中英文字符。据统计,GBK收录了21003个汉字、883个符号以及1897个造字码位,大大增强了字符的覆盖能力。
然而,针对全球化的需要,ANSI本地字符集(在中国代表GBK)存在局限,可能导致跨地区应用时出现乱码。于是,Unicode编码应运而出,这是一个世界通用的字符编码标准,使用4个字节来表示全球几乎所有的字符,约42亿个编码,虽然实际使用中我们通常只用到前两个字节。Unicode编码解决了字符集的国际化问题,使得不同语言和字符都能得到统一的表示。
在MySQL中,理解并正确处理这些编码至关重要,特别是在处理多语言和多字符集的数据时,选择合适的字符集(如UTF-8,它是MySQL默认的多字节字符集,可以处理包括中文在内的多种语言)能够确保数据的一致性和准确性。当涉及到数据输入、查询和输出时,编码转换和适配也是一项必不可少的技能,这将直接影响到程序的稳定性和用户体验。
总结来说,本篇内容介绍了编码在数据库管理特别是MySQL中的重要性,以及ASCII、GB2312、GBK和Unicode等几种常见编码体系的发展、特点和适用场景,这对于理解和处理各种编码问题,特别是处理中文字符,有着深远的影响。
MySQL入门集锦(四)入门集锦(四)
今天的主要是编码问题,在学习一门语言的过程中,编码是不可避避免遇到的问题,而且有时候一困扰就会让人挠破脑袋,所
以
接下来我们一起了解一下每一种编码吧~
编码的产生:
由于计算机只有0和1两种符号,但人的世界里有更为复杂的东西,所以就出现了人为规定。
例如,0100 0001 是表示A,还是65?这就要看上下文环境来决定。
首先,我们先来了解一些编码的发展历史。
一、编码发展
1、ASCII码( American Standard Code for Information Interchange )
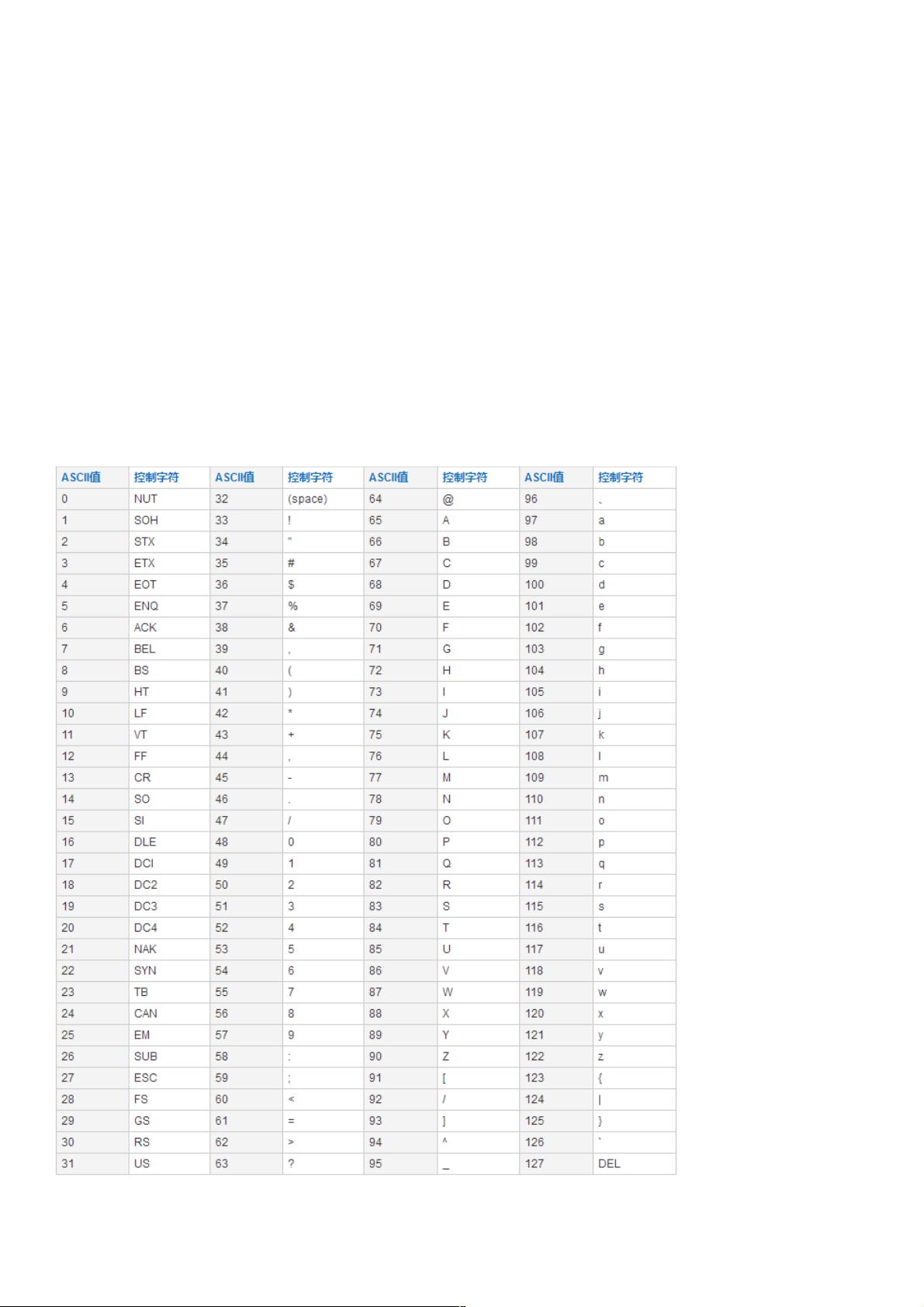
这是最早使用的编码方式,这是美国发明的一种方式,它们认为英文字符总数少于127,所以它们用一个字节的位置来代表不
同
的字符。一个字节有八个比特,一个有256个不同的结果,所以ASCII的最高为长为0来表示不同的字符。
ASCII码对照表
2、GB2312
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-04-24 上传
2023-08-27 上传
2009-08-24 上传
2009-11-19 上传
2013-10-08 上传
2551 浏览量

weixin_38713306
- 粉丝: 3
- 资源: 883
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
