Apriori算法:关联规则挖掘基础与应用详解
下载需积分: 0 | PDF格式 | 1.04MB |
更新于2024-08-05
| 177 浏览量 | 举报
关联规则基本算法及其应用是数据挖掘领域的重要组成部分,它起源于1993年Agrawal等人的工作。他们在试图解决购物篮分析问题时提出了关联规则的概念,这是一个关于商品之间购买模式的发现过程。最初,他们提出的AIS算法性能不佳,随后在1994年引入了Apriori算法,这个算法因其高效性和经典性而被广泛关注。
Apriori算法的核心思想是基于先验信息,即在搜索潜在关联规则时,先检查项集的支持度,然后只保留那些在小规模子集上有足够支持度的项集,避免了无用的搜索。它通过构建项目集格空间来组织数据,使得算法能够有效地减少搜索空间,提高效率。算法的关键步骤包括频繁项集的挖掘、生成关联规则和剪枝操作。
关联规则的基本概念包括以下几个方面:
1. 交易数据库:由一组事务组成,每个事务是一个项集,表示顾客一次购物的购买行为,与唯一的交易标识符TID关联。
2. 关联规则:由两个部分组成,即前提(LHS,左部)和结果(RHS,右部)。例如,“网球拍 -> 网球”,其中LHS是网球拍,RHS是网球,表明在购买网球拍的交易中,通常也会购买网球。
3. 支持度:衡量规则在所有事务中出现的频率,是规则的前提部分在所有事务中同时存在的概率。
4. 置信度:衡量规则的可信度,即在包含前提的事务中,后续结果发生的概率。若一个规则的置信度高于用户设定的阈值,那么这个规则被认为是有趣的。
例如,对于数据库D,如果设置支持度阈值为3/6(50%)和置信度阈值为3/4(75%),则规则“网球拍 -> 网球”的支持度为3(3个事务中有这个组合),置信度为1(因为包含网球拍的事务必然包含网球)。只有当这两个阈值都被满足时,规则才会被视为有意义。
关联规则挖掘在市场营销、推荐系统等领域有着广泛应用,有助于商家了解消费者的购买习惯,制定个性化营销策略,提升销售额。随着大数据的发展,关联规则挖掘技术也在不断优化和扩展,以适应不断增长的数据处理需求。
关联规则基本算法及其应用
1.关联规则挖掘
1.1 关联规则提出背景
1993 年,Agrawal 等人在首先提出关联规则概念,同时给出了相应的挖掘算法 AIS,但
是性能较差。1994 年,他们建立了项目集格空间理论,并依据上述两个定理,提出了著名的
Apriori 算法,至今 Apriori 仍然作为关联规则挖掘的经典算法被广泛讨论,以后诸多的研究
人员对关联规则的挖掘问题进行了大量的研究。关联规则挖掘在数据挖掘中是一个重要的课
题,最近几年已被业界所广泛研究。
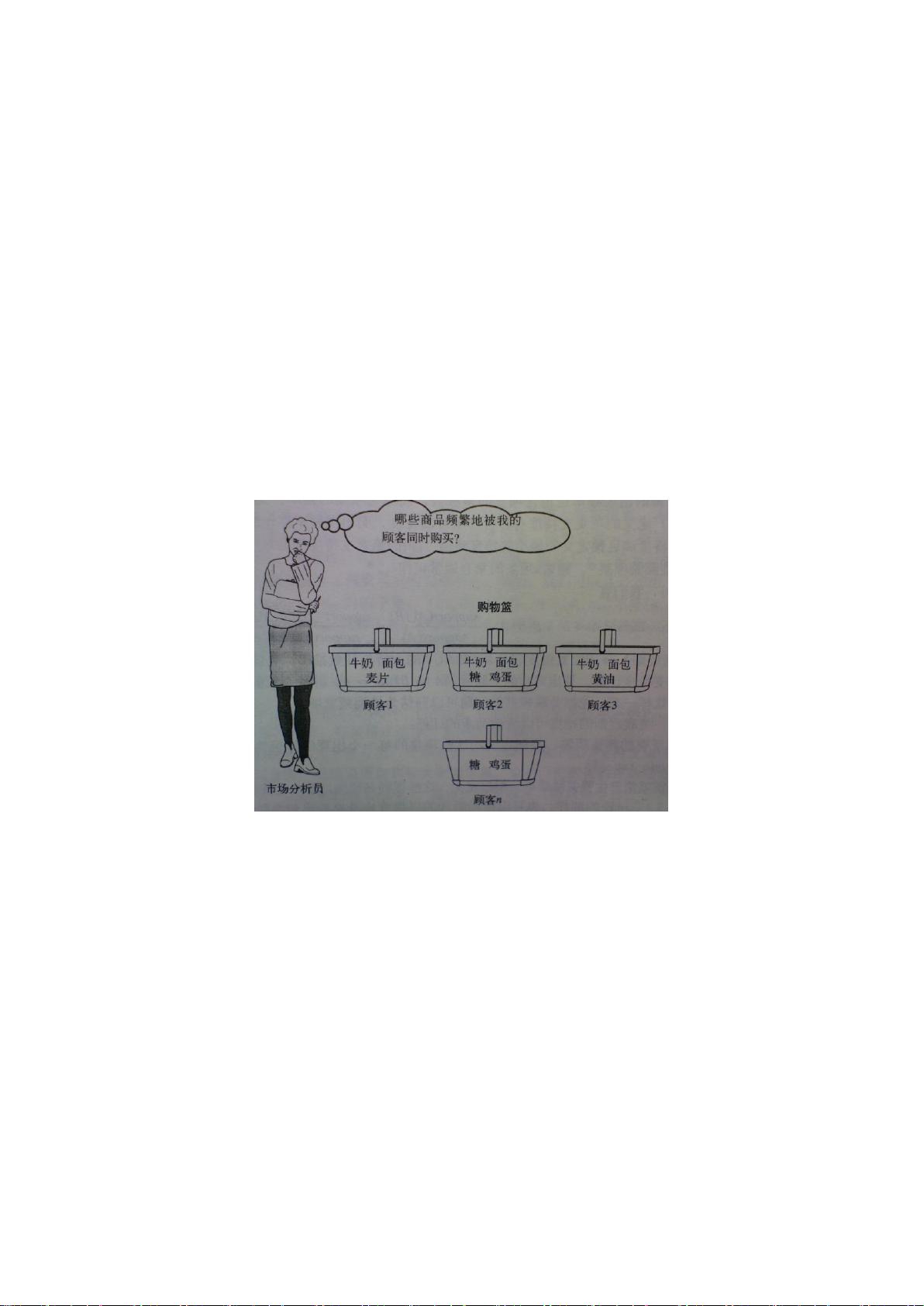
关联规则最初提出的动机是针对购物篮分析(Market Basket Analysis)问题提出的。假设
分店经理想更多的了解顾客的购物习惯(如下图)。特别是,想知道哪些商品顾客可能会在
一次购物时同时购买?为回答该问题,可以对商店的顾客事物零售数量进行购物篮分析。该
过程通过发现顾客放入“购物篮”中的不同商品之间的关联,分析顾客的购物习惯。这种关
联的发现可以帮助零售商了解哪些商品频繁的被顾客同时购买,从而帮助他们开发更好的营
销策略。
1.2 关联规则的基本概念
关 联 规 则 定 义 为 : 假 设
12
{ , ,... }
m
I i i i
是 项 的 集 合 , 给 定 一 个 交 易 数 据 库
, 其中每个事务(Transaction)t 是 I 的非空子集,即 ,每一个交易都与
一个唯一的标识符 TID(Transaction ID)对应。关联规则是形如 的蕴涵式, 其中
且 , 和 分别称为关联规则的先导(antecedent 或 left-hand-side, LHS)
和后继(consequent 或 right-hand-side, RHS)。关联规则 在 D 中的支持度(support)是 D
中事务包含 X∩Y 的百分比,即概率 P(X∩Y);置信度(confidence)是包含 X 的事务中同时
包含 Y 的百分比,即条件概率 。如果满足最小支持度阈值和最小置信度阈值,则
称关联规则是有趣的。这些阈值由用户或者专家设定。
用一个简单的例子说明。
12
D={t ,t ,...,t }
m
tI
XY
X,Y I
XY
X
Y
XY
( | )P Y X
下载后可阅读完整内容,剩余8页未读,立即下载
相关推荐






lowsapkj
- 粉丝: 1019
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言实现LED灯控制的源码教程及使用说明
- zxingdemo实现高效条形码扫描技术解析
- Android项目实践:RecyclerView与Grid View的高效布局
- .NET分层架构的优势与实战应用
- Unity中实现百度人脸识别登录教程
- 解决ListView和ViewPager及TabHost的触摸冲突
- 轻松实现ASP购物车功能的源码及数据库下载
- 电脑刷新慢的快速解决方法
- Condor Framework: 构建高性能Node.js GRPC服务的Alpha框架
- 社交媒体图像中的抗议与暴力检测模型实现
- Android Support Library v4 安装与配置教程
- Android中文API合集——中文翻译组出品
- 暗组计算机远程管理软件V1.0 - 远程控制与管理工具
- NVIDIA GPU深度学习环境搭建全攻略
- 丰富的人物行走动画素材库
- 高效汉字拼音转换工具TinyPinYin_v2.0.3发布
