朴素贝叶斯分类原理与应用
需积分: 19 4 浏览量
更新于2024-06-27
1
收藏 7.91MB PPTX 举报
"本文主要介绍了贝叶斯算法中的朴素贝叶斯分类器,这是一种基于贝叶斯定理和特征之间独立假设的统计分类方法。在实际应用中,朴素贝叶斯分类器因其简单高效和良好的预测性能而在文本分类、垃圾邮件过滤等领域得到广泛应用。"
在机器学习领域,分类问题是常见的任务之一,它涉及到根据特定特征对数据进行预设类别的划分。贝叶斯算法是一种基于概率论的分类方法,尤其是通过贝叶斯定理来解决条件概率问题。贝叶斯定理指出,已知事件B发生的条件下,事件A发生的概率P(A|B)可以通过已知的P(B|A)和P(A)以及全概率P(B)来计算,公式为:
\[ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} \]
在这个框架下,朴素贝叶斯分类器的核心思想是假设特征之间相互独立,即使在同一个类别下,一个特征的存在并不影响其他特征的出现概率。这种假设简化了条件概率的计算,使得在给定新数据点时,可以快速估算它属于某个类别的概率。
朴素贝叶斯分类的过程主要包括以下几个步骤:
1. 数据准备:首先,我们需要一个标注好的训练数据集,其中包含待分类项和它们对应的类别标签。
2. 概率估计:对训练数据集进行统计,计算每个类别中各个特征的条件概率P(a|y),其中a代表特征,y代表类别。如果特征是离散的,可以直接统计每个特征在不同类别中的频率。对于连续特征,通常假设其服从高斯分布,需要计算每个类别中特征的均值和标准差。
3. 分类决策:对于新的待分类项x,计算它属于每个类别的后验概率P(y|x)。选择具有最高后验概率的类别作为x的预测类别。这个过程可以通过贝叶斯公式完成:
\[ P(y|x) = \frac{P(x|y) \cdot P(y)}{P(x)} \]
其中,P(x)通常是归一化项,对分类结果影响不大,因此在实际计算中通常被忽略。
4. 模型评估与优化:使用验证集或交叉验证来评估分类器的性能,如准确率、查准率、查全率等指标,并根据需求进行模型参数的调整或优化。
朴素贝叶斯分类器虽然简单,但它在处理大量特征的数据集时表现出高效性,而且对于缺失数据的处理相对宽容。然而,它的“朴素”假设——特征之间的独立性——在现实世界数据中往往不成立,这可能会影响其分类效果。尽管如此,通过集成学习、特征选择等手段,朴素贝叶斯分类器仍能在许多实际问题中获得满意的结果。
在大数据背景下,贝叶斯算法可以与其他大数据处理技术结合,例如MapReduce,以处理大规模数据集。此外,贝叶斯网络则是一种更复杂的贝叶斯模型,它可以表示特征间的条件依赖关系,适用于更复杂的概率推理任务。尽管如此,朴素贝叶斯分类器因其易于理解和实现,仍然是初学者和经验丰富的数据科学家首选的分类工具之一。
分类
○
什么是分类
小
雨
小
朋
旭
哥
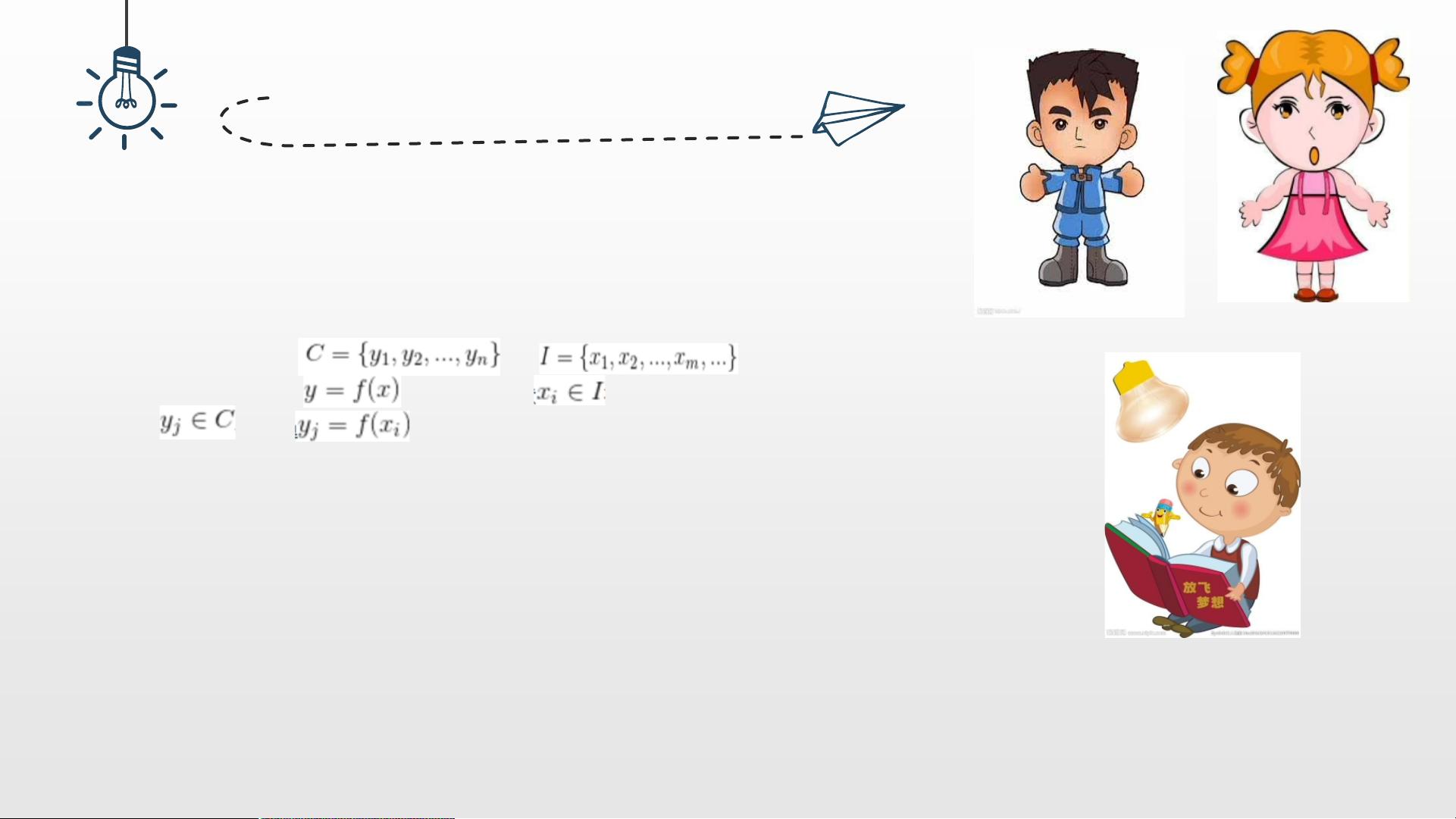
从数学角度来说,分类问题可做如下定义:
已知集合:
和 ,确定映射
规则 ,使得任意 有
且仅有一个 使得
成立。(不考虑模糊数学里的模糊集情况)
其中C叫做类别集合,其中每一个元素
是一个类别,而I叫做项集合,其中每一个元素是一
个待分类项,f叫做分类器。分类算法的任务就是构
造分类器f。
剩余17页未读,继续阅读
点击了解资源详情
102 浏览量
288 浏览量
110 浏览量
276 浏览量
194 浏览量
223 浏览量
2024-06-12 上传
点击了解资源详情

松鼠协会总动员
- 粉丝: 284
- 资源: 180
 我的内容管理
展开
我的内容管理
展开







最新资源
- hareandhounds:一个基于网络的游戏,称为“野兔和猎犬”
- QTranslate v6.8.0 LITE快速翻译工具
- 茶叶商城(含后端)_history3v6_商城小程序_茶叶商城
- marmot:Marmot工作流程执行引擎
- 国际象棋系统
- 易语言超级列表框取单行列
- civo_cloud_network_test
- api:石灰事件的GraphQL API
- lorentz-force:一种在三维场中模拟磁力对粒子影响的工具
- 修正的摩尔库伦模型_abaqus库伦_abaqus隧道_摩尔库伦模型_abaqus修正摩尔_修正的摩尔库伦三维模型
- 易语言超级列表框动态插入
- appcenter:Liri OS的App Center
- food_app
- pipeline-library
- ticTacToe_js
- java各种javaUntils集成工具类源代码
