大数据场景下:倒排索引原理与应用
需积分: 0 152 浏览量
更新于2024-09-07
收藏 972KB DOCX 举报
"倒排索引是大数据场景下用于高效检索文档的重要技术,尤其在分布式数据库和OLAP(在线分析处理)中具有广泛的应用。它与传统的正向索引相反,能够快速定位到包含特定关键词的文档。"
倒排索引是一种在大规模数据集上实现高效全文检索的技术,其核心思想是将文档中出现的关键词作为索引的主键,而非文档本身。在正向索引中,我们通过文档ID找到关键词及其相关信息,而在倒排索引中,我们通过关键词来查找包含该关键词的文档ID。
倒排索引由两大部分构成:单词词典和倒排文件。单词词典是所有出现过的单词集合,包含每个单词的信息,如词频、词性等,并且每个单词都链接到对应的倒排列表。倒排文件则存储这些倒排列表,其中每个倒排列表详细记录了含有特定单词的所有文档ID,以及这些单词在文档中的位置信息。
例如,对于一个包含多个文档的集合,每个文档可能包含多个单词。在构建倒排索引时,首先需要对文档进行分词,然后为每个唯一的单词分配一个编号,并记录哪些文档包含了这个单词。更进一步,倒排索引还可以记录单词的文档频率,即在多少文档中出现过,以及单词在文档内的位置和出现次数,这些信息在计算搜索结果的相关性评分时非常关键,比如TF-IDF算法就利用了这些数据。
在大数据环境下,传统的正向索引效率低下,因为它需要遍历所有文档来寻找匹配的关键词,而倒排索引则可以直接定位到包含目标关键词的文档,大大提高了检索速度。因此,倒排索引成为搜索引擎、数据库系统和大数据分析平台的首选索引结构,特别是在OLAP系统中,它能支持快速的多维度分析和聚合操作。
分布式数据库利用倒排索引可以在多个节点间高效地分散查询负载,提高整体系统的并行处理能力。通过将倒排索引分布式存储和处理,大数据环境下的信息检索变得更为实时和高效。
总结来说,倒排索引是大数据时代的一种关键技术,它通过优化数据结构,提升了在海量数据中进行文本搜索和分析的性能。通过单词词典和倒排文件的联合运用,实现了从关键词到文档的快速映射,从而在大规模数据集上实现了高效的全文检索和分析。
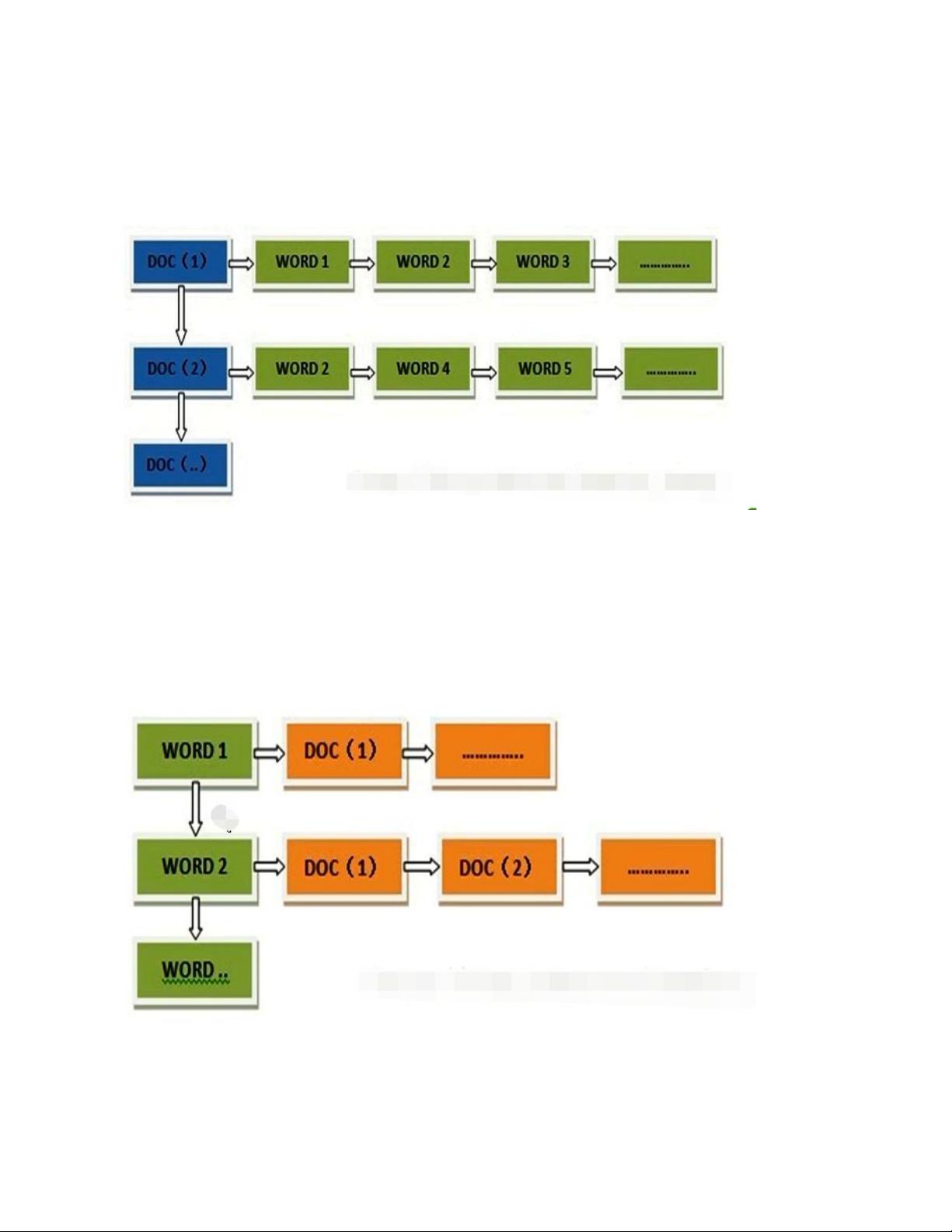
1.正向索引(forward index)和反向索引(inverted index)更熟悉的名字是倒排索引。
正向索引的结构如下:
“文档 1”的 ID > 单词 1:出现次数,出现位置列表;单词 2:出现次数,出现位置列表;…………。
“文档 2”的 ID > 此文档出现的关键词列表。
一般是通过 key,去找 value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引,那么就需要扫描索引库中的所有文
档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因
为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排
名结果的要求。所以,搜索引擎会将正向索引重新构建为倒排索引。
得到倒排索引的结构如下:
“关键词 1”:“文档 1”的 ID,“文档 2”的 ID,…………。
“关键词 2”:带有此关键词的文档 ID 列表。
从词的关键字,去找文档。
2.倒排索引基本概念
下载后可阅读完整内容,剩余5页未读,立即下载
115 浏览量
858 浏览量
288 浏览量
235 浏览量
2008-12-11 上传
174 浏览量
119 浏览量
2021-10-09 上传
151 浏览量

舍得先森V
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Juicy-Potato:Windows本地权限提升工具新秀
- Matlab实现有限差分声波方程正演程序
- SQL Server高可用Alwayson集群搭建教程
- Simulink Stateflow应用实例教程
- Android平台四则运算计算器简易实现
- ForgeRock身份验证节点:捕获URL参数到共享状态属性
- 基于SpringMVC3+Spring3+Mybatis3+easyui的家庭财务管理解决方案
- 银行专用大华监控视频播放器2.0
- PDRatingView:提升Xamarin.iOS用户体验的评分组件
- 嵌入式学习必备:Linux菜鸟入门指南
- 全面的lit文件格式转换解决方案
- 聊天留言网站HTML源码教程及多功能项目资源
- 爱普生ME-10打印机清理软件高效操作指南
- HackerRank问题解决方案集锦
- 华南理工数值分析实验3:计算方法实践指南
- Xamarin.Forms新手指南:Prism框架实操教程
