高性能RDMA系统设计指南
需积分: 30 46 浏览量
更新于2024-07-09
1
收藏 637KB PDF 举报
"Design Guideline for High Performance RDMA.pdf 是一篇关于如何设计高效率RDMA(Remote Direct Memory Access)系统的论文,由Anuj Kalia、Michael Kaminsky和David G. Andersen在2016年USENIX年度技术会议上发表。论文强调了RDMA设计中的关键选择,包括所使用的RDMA操作及如何使用它们,这些都会显著影响实际性能。"
RDMA是一种先进的网络技术,它允许网络设备直接访问远程计算机的内存,无需经过操作系统内核,从而实现了极低的延迟和高吞吐量。本文主要针对RDMA硬件提供的高性能潜力,提出了一系列设计指南,帮助系统设计师有效地利用这种技术。
首先,论文指出,RDMA设计的关键在于关注底层细节,例如PCIe事务的处理方式。PCIe(Peripheral Component Interconnect Express)是连接RDMA硬件到主机处理器的主要接口,其性能和配置对RDMA的效率至关重要。设计师需要了解如何优化PCIe通道,以减少数据传输的延迟和提高带宽利用率。
其次,选择正确的RDMA操作类型是另一个关键因素。RDMA提供了多种操作,如读、写、原子操作等,每种都有其特定的应用场景和性能特征。设计师需要根据应用需求,权衡这些操作的性能影响,选择最佳方案。
论文还可能探讨了网络拓扑结构、队列对(Queue Pair, QP)的设置、内存缓冲区管理以及错误处理策略。网络拓扑会影响数据传输的路径和延迟,合理的队列对配置可以平衡负载并提高并发性,而高效内存管理则能减少内存冲突和CPU开销。错误处理机制则确保了系统的稳定性和恢复能力。
此外,论文可能还涵盖了软件层面的优化,比如用户空间驱动程序的使用,这可以避免内核上下文切换带来的开销。同时,高效的完成队列(Completion Queue, CQ)处理策略也是提高RDMA性能的重要方面。
"Design Guidelines for High Performance RDMA" 提供了深入理解RDMA技术及其优化方法的框架,对于希望构建高效、低延迟网络应用的系统设计者来说,是一份极具价值的参考资料。通过遵循这些指导原则,设计师可以充分利用RDMA的优势,实现更高效的数据传输和计算。
438 2016 USENIX Annual Technical Conference USENIX Association
Connect-IB
NIC
56 Gb/s InfiniBand
E5-2683-v3
PCIe 3.0 x16
PCIe control
L3 cache
C
1
C
14
DRAM
56 Gb/s InfiniBand
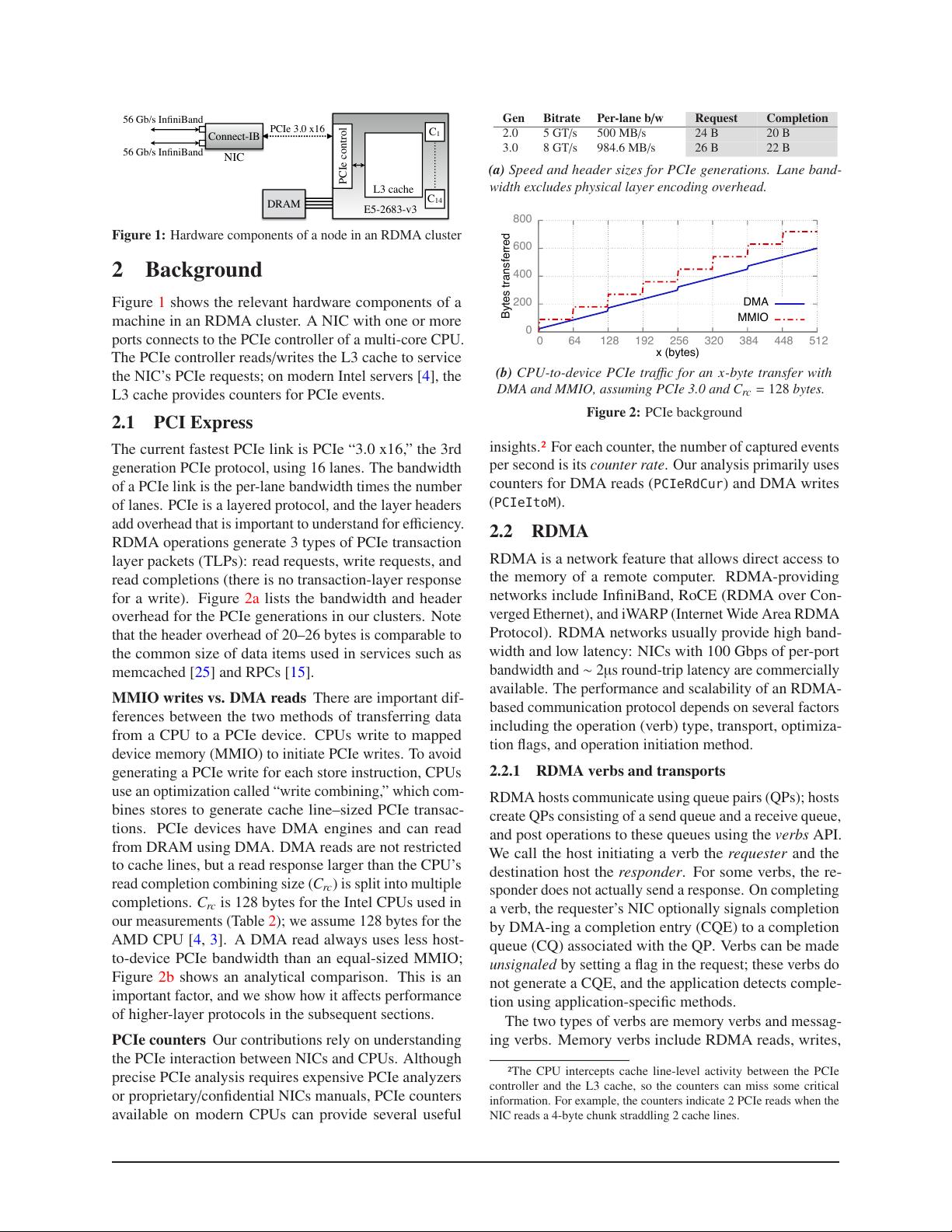
Figure 1:
Hardware components of a node in an RDMA cluster
2 Background
Figure 1 shows the relevant hardware components of a
machine in an RDMA cluster. A NIC with one or more
ports connects to the PCIe controller of a multi-core CPU.
The PCIe controller reads/writes the L3 cache to service
the NIC’s PCIe requests; on modern Intel servers [
4
], the
L3 cache provides counters for PCIe events.
2.1 PCI Express
The current fastest PCIe link is PCIe “3.0 x16,” the 3rd
generation PCIe protocol, using 16 lanes. The bandwidth
of a PCIe link is the per-lane bandwidth times the number
of lanes. PCIe is a layered protocol, and the layer headers
add overhead that is important to understand for efficiency.
RDMA operations generate 3 types of PCIe transaction
layer packets (TLPs): read requests, write requests, and
read completions (there is no transaction-layer response
for a write). Figure 2a lists the bandwidth and header
overhead for the PCIe generations in our clusters. Note
that the header overhead of 20–26 bytes is comparable to
the common size of data items used in services such as
memcached [25] and RPCs [15].
MMIO writes vs. DMA reads
There are important dif-
ferences between the two methods of transferring data
from a CPU to a PCIe device. CPUs write to mapped
device memory (MMIO) to initiate PCIe writes. To avoid
generating a PCIe write for each store instruction, CPUs
use an optimization called “write combining,” which com-
bines stores to generate cache line–sized PCIe transac-
tions. PCIe devices have DMA engines and can read
from DRAM using DMA. DMA reads are not restricted
to cache lines, but a read response larger than the CPU’s
read completion combining size (
C
rc
) is split into multiple
completions.
C
rc
is 128 bytes for the Intel CPUs used in
our measurements (Table 2); we assume 128 bytes for the
AMD CPU [
4
,
3
]. A DMA read always uses less host-
to-device PCIe bandwidth than an equal-sized MMIO;
Figure 2b shows an analytical comparison. This is an
important factor, and we show how it affects performance
of higher-layer protocols in the subsequent sections.
PCIe counters
Our contributions rely on understanding
the PCIe interaction between NICs and CPUs. Although
precise PCIe analysis requires expensive PCIe analyzers
or proprietary/confidential NICs manuals, PCIe counters
available on modern CPUs can provide several useful
Gen Bitrate Per-lane b/w Request Completion
2.0 5 GT/s 500 MB/s 24 B 20 B
3.0 8 GT/s 984.6 MB/s
26 B 22 B
(a)
Speed and header sizes for PCIe generations. Lane band-
width excludes physical layer encoding overhead.
(b)
CPU-to-device PCIe traffic for an
x
-byte transfer with
DMA and MMIO, assuming PCIe 3.0 and C
rc
= 128 bytes.
Figure 2: PCIe background
insights.
2
For each counter, the number of captured events
per second is its counter rate. Our analysis primarily uses
counters for DMA reads (
PCIeRdCur
) and DMA writes
(PCIeItoM).
2.2 RDMA
RDMA is a network feature that allows direct access to
the memory of a remote computer. RDMA-providing
networks include InfiniBand, RoCE (RDMA over Con-
verged Ethernet), and iWARP (Internet Wide Area RDMA
Protocol). RDMA networks usually provide high band-
width and low latency: NICs with 100 Gbps of per-port
bandwidth and
∼
2
µ
s round-trip latency are commercially
available. The performance and scalability of an RDMA-
based communication protocol depends on several factors
including the operation (verb) type, transport, optimiza-
tion flags, and operation initiation method.
2.2.1 RDMA verbs and transports
RDMA hosts communicate using queue pairs (QPs); hosts
create QPs consisting of a send queue and a receive queue,
and post operations to these queues using the verbs API.
We call the host initiating a verb the requester and the
destination host the responder. For some verbs, the re-
sponder does not actually send a response. On completing
a verb, the requester’s NIC optionally signals completion
by
DMA-ing
a completion entry (CQE) to a completion
queue (CQ) associated with the QP. Verbs can be made
unsignaled by setting a flag in the request; these verbs do
not generate a CQE, and the application detects comple-
tion using application-specific methods.
The two types of verbs are memory verbs and messag-
ing verbs. Memory verbs include RDMA reads, writes,
2
The CPU intercepts cache line-level activity between the PCIe
controller and the L3 cache, so the counters can miss some critical
information. For example, the counters indicate 2 PCIe reads when the
NIC reads a 4-byte chunk straddling 2 cache lines.
2
剩余14页未读,继续阅读
2022-04-28 上传
2021-03-13 上传
2021-10-18 上传
2022-08-03 上传
2021-10-03 上传
2024-04-20 上传

bandaoyu
- 粉丝: 18w+
- 资源: 63
 我的内容管理
展开
我的内容管理
展开







最新资源
- Oracle Form觸發器、系統變量精解2
- Oracle Form屬性、內置子程序、觸發器、系統變量精解
- SMSCOM开发手册
- PIC C语言编程实例
- ubuntu命令参考卡片
- How to Write Program in Visual C++
- SVN权限控制全面解析
- apache+svn+MySQL+PHP+svnmanager+bugfree完全安装手册
- Thinking In Java 第三版目录版中文版PDF
- SNMP-简单网络管理协议(PDF)
- 10720路由器信息
- Apache+SVN+Trac配置详解
- 硬盘数据恢复教程 PDF格式
- 软件工程详细设计说明书
- JSON教程.pdf
- wince中文版(部分章节)
