Python数据分析利器:pandas深度学习教程
版权申诉
35 浏览量
更新于2024-06-15
收藏 2.29MB PDF 举报
"pandas教学详细课件,涵盖了pandas在数据科学与统计计算中的应用"
在数据科学领域,pandas是一个不可或缺的开源库,它提供了一系列强大的数据分析工具。pandas库的核心是用Cython(C+Python的混合语言)实现的,这使得它在处理速度上有了显著的优势。其设计灵感部分来源于R语言中的数据库结构,同时又很好地融入了numpy和scipy生态系统,优化了常用操作,如向量化运算和对表格数据行的操作。
pandas的主要特点在于其快速、灵活且表达性强的数据结构,如Series(一维带标签的数据结构)和DataFrame(二维表格型数据结构),它们使得处理“关系型”或“标记型”的数据变得简单直观。这个库旨在成为Python进行实际、现实世界数据分析的基础高层构建块。
要安装pandas,可以通过多种方式:
1. 使用conda包管理器:
```
conda install pandas
```
2. 使用pip包管理器:
```
pip install pandas
```
3. 直接从二进制文件安装(不推荐,因为可能不稳定):
可以从Python的包索引网站(PyPI)下载最新版本:http://pypi.python.org/pypi/pandas
需要注意的是,pandas的更新有时可能会引入破坏性变更,即某些函数的参数数量、默认值或其他行为会发生变化。因此,确保使用的是最新版本是非常重要的,以避免因旧版API的改变而引发的问题。
pandas的核心组件包括:
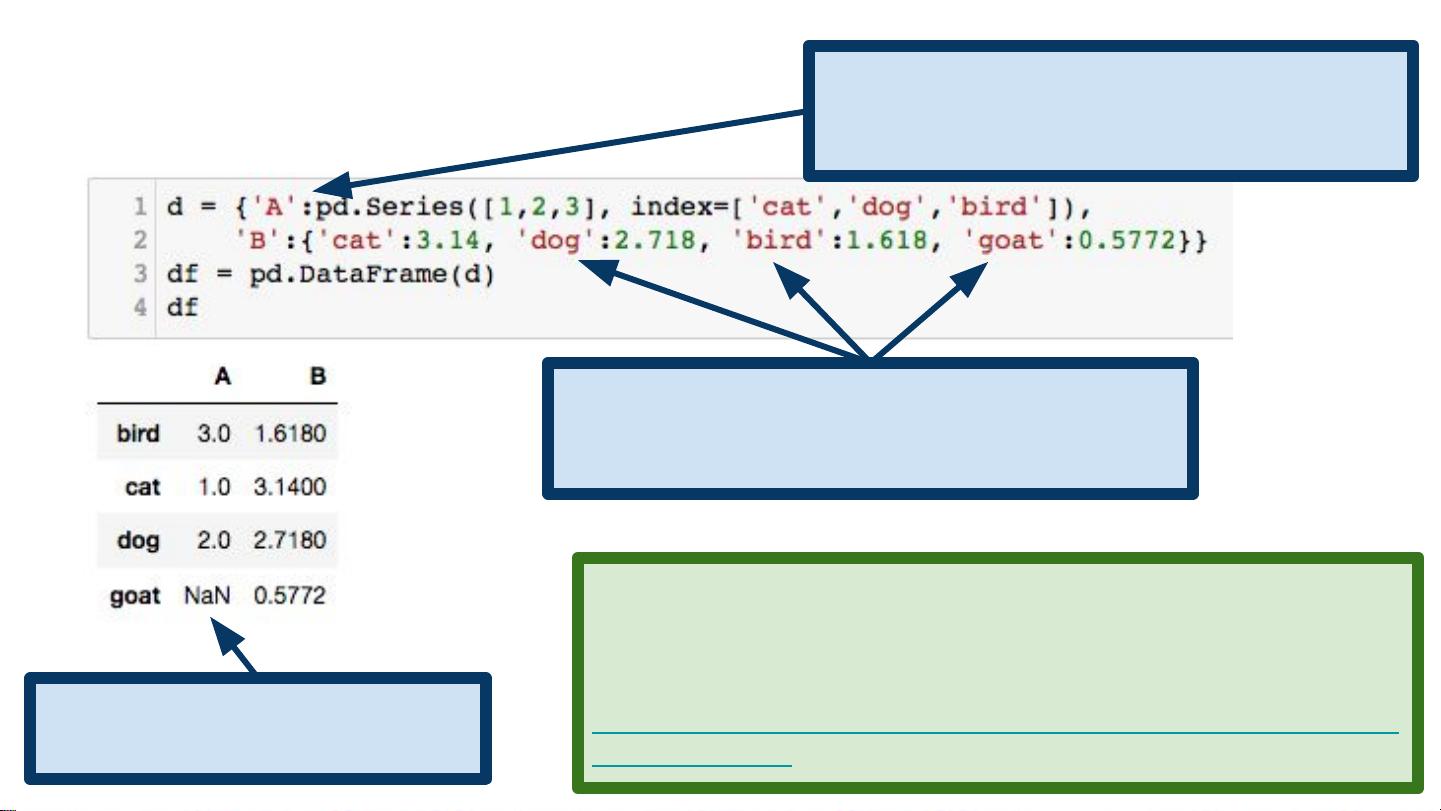
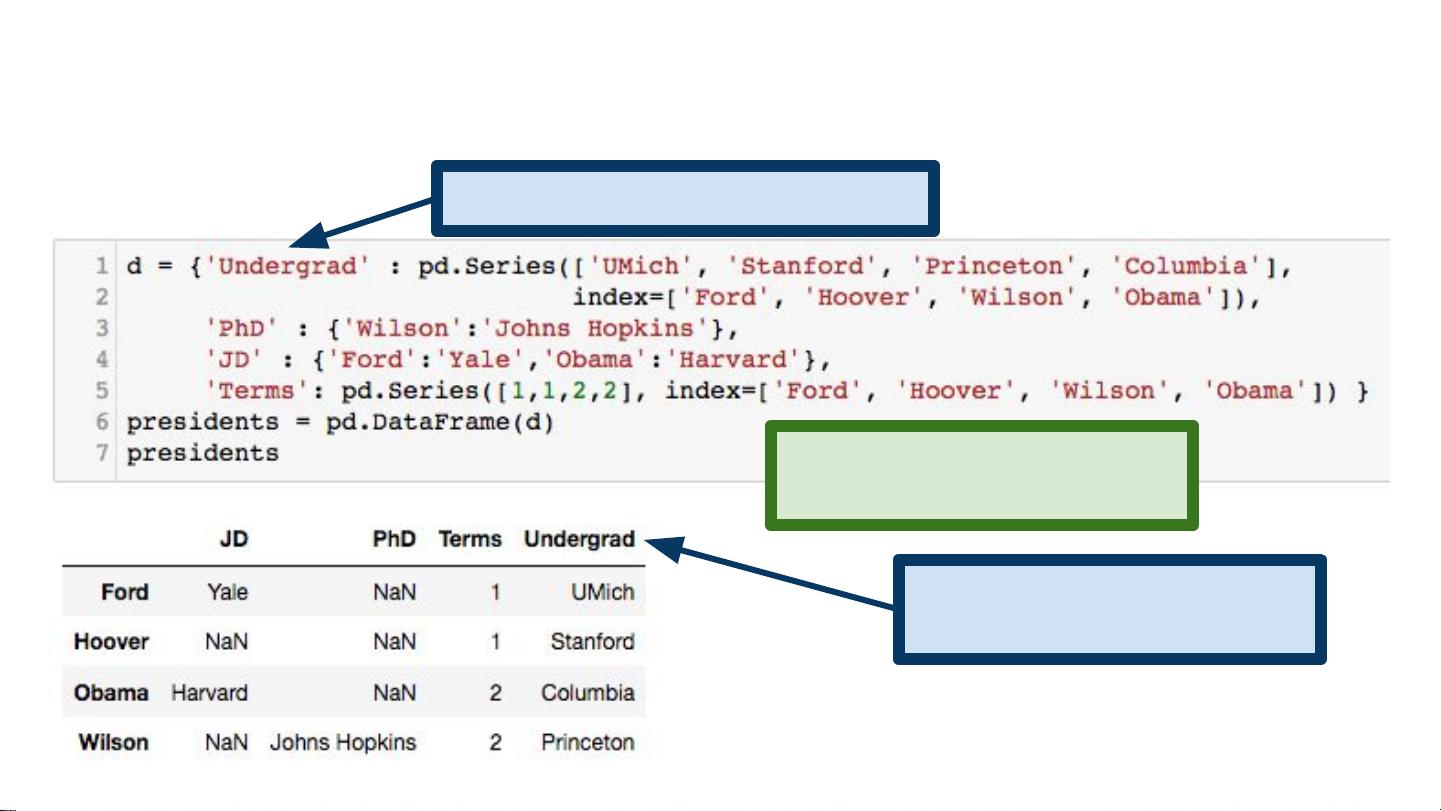
- Series:类似于一维数组,但每个元素都有一个标签(即索引)。可以存储各种类型的数据(整数、字符串、浮点数等)。
- DataFrame:二维表格数据结构,包含列(Series)和行索引。DataFrame可以看作是表格的集合,每个列都有自己的数据类型。
- Index:用于定义和操作数据的标签系统。
- Panel:三维数据结构,类似DataFrame的扩展,用于处理多维数据。
pandas提供了丰富的数据操作方法,如选择、过滤、排序、合并、重塑、分组、时间序列分析等。此外,它还支持缺失数据处理,可以方便地读写各种文件格式(如CSV、Excel、SQL数据库等),并与其他Python库(如matplotlib和seaborn)无缝集成进行数据可视化。
学习pandas,不仅要掌握其基本数据结构,还要熟悉其数据操作接口,如`.loc`和`.iloc`用于基于标签和位置的选取,以及`.head()`, `.tail()`, `.describe()`等用于数据概览的方法。通过深入理解和实践,可以提高数据处理的效率和质量,使数据分析工作更加得心应手。

Mapping and linking Series values
Series map also allows us to change
values based on another Series. Here,
we’re changing the fruit/animal category
labels to binary labels.

剩余89页未读,继续阅读
119 浏览量
点击了解资源详情
点击了解资源详情
1756 浏览量
2021-11-25 上传
2022-03-18 上传
109 浏览量
2022-06-12 上传
2024-06-01 上传

柒然
- 粉丝: 1861
 我的内容管理
展开
我的内容管理
展开







最新资源
- webacus工具实现自动页面生成与报表导出功能
- 深入理解FAT32文件系统及其数据存储与管理
- 玛纳斯·穆莱全栈Web开发学习与WakaTime统计
- mini翼虎播放器官方安装版:CG视频教程全能播放器
- CoCreate-pickr:轻便的JavaScript选择器组件指南与演示
- 掌握Xdebug 5.6:PHP代码调试与性能追踪
- NLW4节点项目:使用TypeORM和SQLite进行用户ID管理
- 深入了解Linux Bluetooth开源栈bluez源代码解析
- STM32与A7105射频芯片的点对点收发控制实现
- 微信高仿项目实践:FragmentUtil使用与分析
- 官方发布的CG视频教程播放器 mini翼虎x32v2015.7.31.0
- 使用python-lambder自动化AWS Lambda计划任务
- 掌握异步编程:深入学习JavaScript的Ajax和Fetch API
- LTC6803电池管理系统(BMS)经典程序解析
- 酷音传送v2.0.1.4:正版网络音乐平台,歌词同步功能
- Java面向对象编程练习:多态在游戏对战模拟中的应用
