WEKA中文用户指南:数据预处理、分类与更多
"这是一份关于WEKA数据挖掘工具的中文用户指南,涵盖了从启动WEKA、使用WEKA Explorer到各种数据预处理、分类、聚类、关联规则学习、属性选择以及可视化等核心功能的详细说明。"
WEKA是Waikato Environment for Knowledge Analysis的简称,是一个广泛用于数据挖掘任务的开源软件,它提供了大量的机器学习算法和数据预处理工具。该指南主要分为以下几个部分:
1. **启动WEKA**: 提及了WEKA的启动方式,包括使用GUI和命令行接口,特别强调了在非终端环境下,日志窗口对于查看输出信息的重要性。
2. **WEKA Explorer**: 是WEKA的主要界面,包含多个标签页,如数据预处理、分类、聚类等,还有状态栏、Log按钮和WEKA状态图标,便于用户了解操作进度和状态。
3. **预处理**: 阐述了如何加载数据、查看当前数据关系、处理属性以及应用筛选器进行数据清洗和转换。
4. **分类**: 详细介绍了如何在WEKA中选择分类器、设置测试选项、指定类别属性、训练模型以及查看和分析分类结果。
5. **聚类**: 包括选择聚类器、查看聚类模式、忽略属性和执行聚类学习的过程,帮助用户无监督地发现数据的内在结构。
6. **关联规则**: 解释了设置关联规则参数和学习过程,用于发现数据集中的频繁项集和关联规则。
7. **属性选择**: 讨论了属性选择的搜索和评估方法,以及如何配置和执行属性选择过程,以优化模型性能。
8. **可视化**: 提供了各种图表工具,如散点图矩阵、单个二维散点图和实例选择,帮助用户直观地理解数据和模型。
这份指南不仅适用于初学者,也适合有一定经验的用户,通过深入浅出的介绍,帮助用户熟练掌握WEKA的各种功能,从而更好地进行数据挖掘工作。无论是进行分类、聚类还是关联规则挖掘,用户都能从中找到详细的步骤和操作指导。此外,指南还提到了其他如Experimenter(实验者)和KnowledgeFlow(知识流)等高级功能,这些功能为更复杂的实验设计和交互式学习提供了便利。
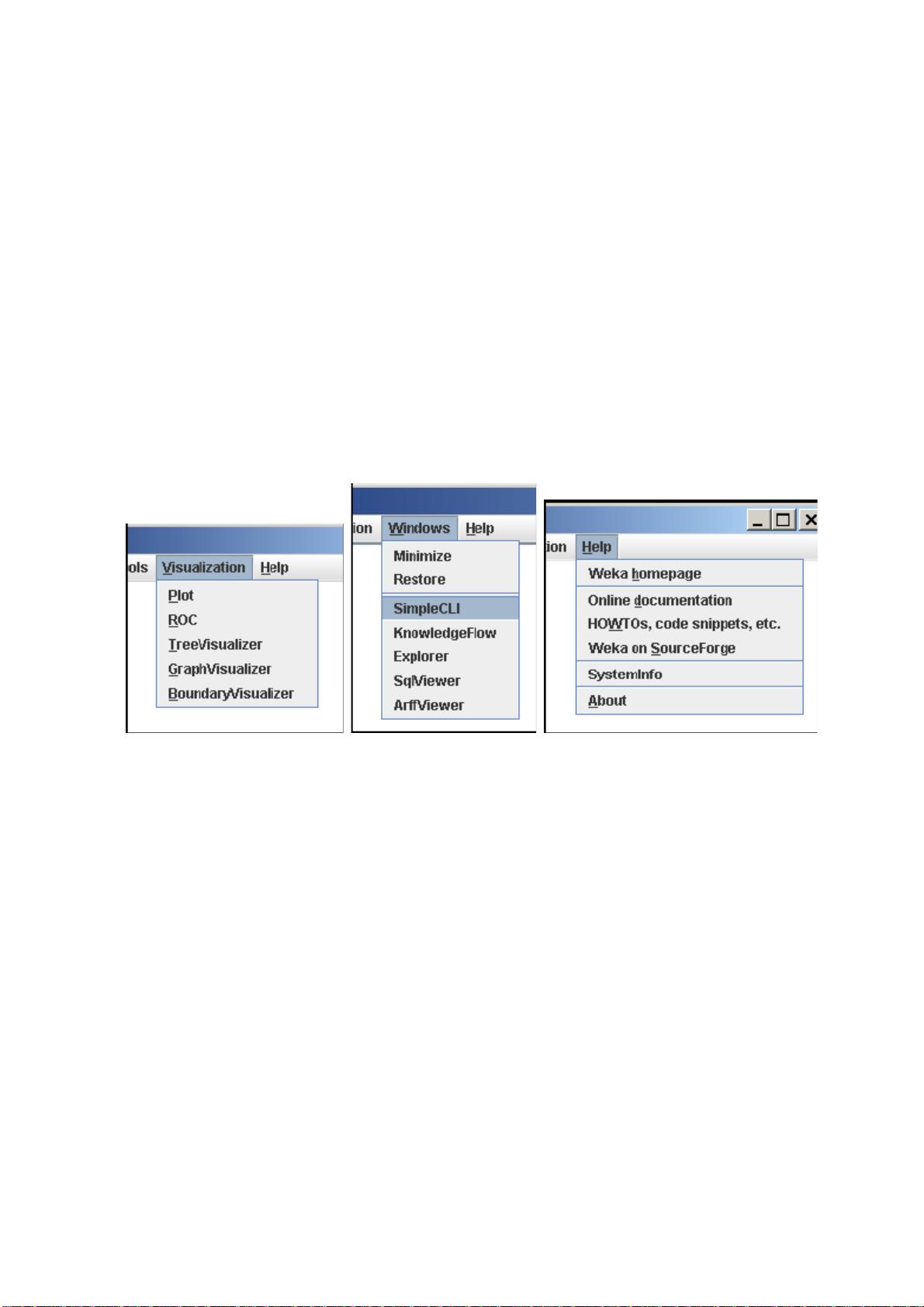
z TreeVisualizer 显示一个有向图,例如一个决策树。
z GraphVisualizer 显示 XML、BIF 或 DOT 格式的图片,例如贝叶斯网络
(Bayesian network)。
z BoundaryVisualizer 允许在二维空间中对分类器的决策边界进行可视化。
5. Windows 所有已打开的窗口都列在这里。
z Minimize 最小化所有当前的窗口。
z Restore 还原所有最小化过的窗口。
6. Help WEKA 的在线资源可以从这里找到。
z Weka homepage 打开一个浏览器窗口,显示 WEKA 的主页。
z Online documentation 链接到 WekaDoc 维基文档 [4]。
z HOWTOs, code snippets, etc. 通用的 WekaWiki [3],包括大量的例子,
以及开发和使用 WEKA 的基本知识(HOWTO)。
z Weka on Sourceforge WEKA 项目在 Sourceforge.net 的主页。
z SystemInfo 列出一些关于 Java/WEKA 环境的信息,例如 CLASSPATH。
z About 不光彩的“About”窗口。
如果从终端启动 WEKA,会有一些文字在终端窗口中出现。这些文字是可以忽略的,
除非某些东西出错了——这时它可以帮助找到错误的原因。(LogWindow 也可以显示那
些信息。)
这份文档也可以从在线的
WekaDoc Wiki
[4] 中找到,它将集中阐述如何使用
Explorer,而不会逐个解释 WEKA 中的数据预处理工具和学习算法。要获得关于各种筛选
器(filter)和学习算法的更多信息,可参考
Data Mining
[2] 一书。
剩余19页未读,继续阅读
2008-12-14 上传
141 浏览量
2018-11-19 上传
点击了解资源详情
2014-06-19 上传
点击了解资源详情
2023-09-18 上传
2019-08-04 上传
191 浏览量

xxs105
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
