"第四章:MapReduce分布式计算框架初探-大数据技术教程"
版权申诉
176 浏览量
更新于2024-02-18
收藏 1.62MB DOCX 举报
MapReduce是一种面向大规模数据并行处理的编程模型,同时也是一种并行分布式计算框架。在Hadoop流行之前,分布式框架虽然存在,但实现相对复杂且多为大公司专利,而小公司缺乏实现分布式系统的能力和人力。然而,Hadoop的出现改变了这一现状,使用MapReduce框架使得分布式编程变得简单。MapReduce主要包括Map阶段和Reduce阶段,每个阶段以键值对为输入和输出。程序员只需实现Map和Reduce函数便可实现分布式计算,同时平台底层处理分布式实现、资源调度和内部通信等细节,使开发者无需关注。基于Hadoop开发项目相对简单,即使是小公司也可以轻松开发分布式处理软件。
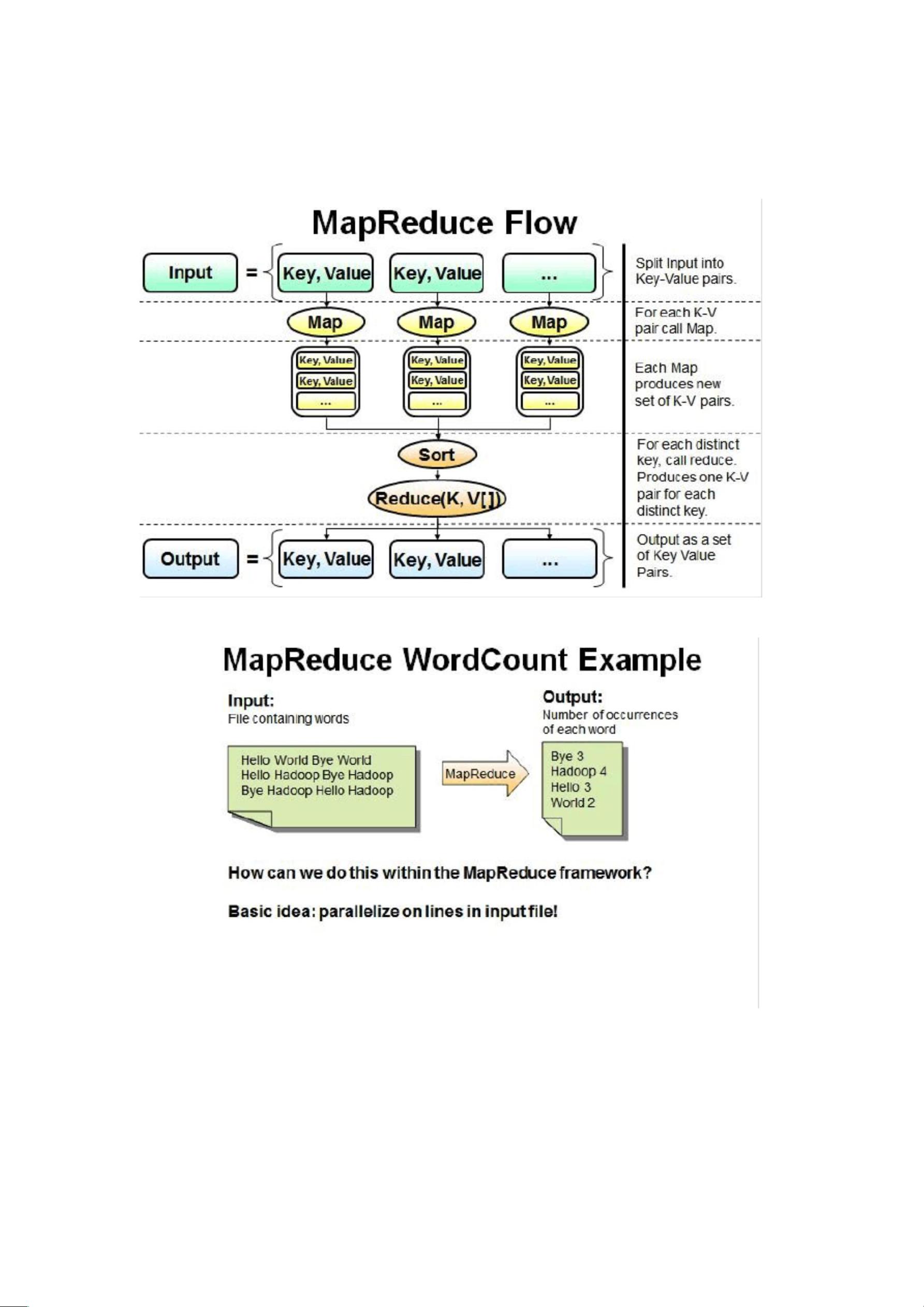
MapReduce的基本过程涉及用户在该模型框架下编写自己的Map函数和Reduce函数以实现分布式数据处理。MapReduce程序的执行过程主要是调用Map函数和Reduce函数来处理数据。在Map阶段,数据按键值对进行映射,而在Reduce阶段,根据相同键的值将数据进行聚合处理。MapReduce框架将整体任务分解为小块并分发到各个节点上同时进行处理,最终将结果合并输出。这种并行处理方式极大地提高了大规模数据处理的效率和速度。
除了Map和Reduce函数外,MapReduce还包括Combiner函数和Partitioner函数。Combiner函数用于将Map任务输出的中间结果进行本地聚合,减少数据传输量,提高效率;而Partitioner函数则用于将Reduce函数的输出结果进行分区处理,并将数据发送到合适的节点上进行Reduce操作。通过合理利用这些函数,可以进一步提高MapReduce处理数据的效率和性能。
总的来说,MapReduce是一种高效、简单的分布式计算框架,能够帮助用户解决大规模数据处理的问题。通过合理利用Map、Reduce、Combiner和Partitioner函数,能够更好地利用集群资源,提高数据处理效率。MapReduce的出现为大数据处理提供了更加便捷和高效的解决方案,使得分布式处理软件开发变得更加容易,同时也为用户提供了更好的数据计算和分析工具。
main 函数将作业控制和文件输入/输出结合起来。
下面我们用一个单词统计的例子来学习 MapReduce 程序执行过程。
并行读取文本中的内容,然后进行 MapReduce 操作。
•
Map 过程:并行读取文本,对读取的单词进行 map 操作,每个词都以<key,value>形式
生成。
•
一个有三行文本的文件进行 MapReduce 操作。
读取第一行 Hello World Bye World ,分割单词形成 Map。
剩余22页未读,继续阅读
2021-12-17 上传
2021-10-05 上传
2023-11-19 上传
2023-06-03 上传
错误: 找不到或无法加载主类 jar.usr.local.hadoop-3.1.4.share.hadoop.mapreduce.hadoop-mapreduce-examples-3.1.4.jar
2024-09-30 上传
2023-05-30 上传
2023-04-29 上传
2023-05-24 上传
2023-05-16 上传

春哥111
- 粉丝: 1w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
