"中通快递:优化实践中的Spark Shuffle Service源码探究"
版权申诉
76 浏览量
更新于2024-02-22
收藏 3.1MB DOCX 举报
中通快递是一家综合物流服务企业,其业务范围涵盖跨境、快运、商业、云仓、航空、金融、智能、传媒和冷链等生态版块。2021年,中通快递的业务量突破了170亿件,同比增长超过40%。随着业务量不断增长,数据时效性的需求也不断提高,传统的基于hive mapreduce的离线计算已经无法满足需求。因此,中通快递于2021年底开始尝试将hive计算迁移到spark 2.3.2上加速离线计算,以满足对数据处理的更高要求。
随着hive计算迁移到spark计算的进行,夜间ETL任务的总耗时不断减少,同时yarn资源占用也开始降低。然而,这一过程也暴露出了一些问题。其中一个问题是关于spark shuffle service的优化需求。Spark根据算子之间的宽窄依赖划分stage,同一个stage由多个task并行执行,而stage与stage之间的数据传输通过task写入本地文件来实现。上一个stage的task执行完成后,将结果数据写入executor所在机器的本地磁盘。这一过程中,shuffle过程的性能对整体计算性能有很大的影响,因此需要针对spark shuffle service进行优化。
为了解决这一问题,我们进行了一系列的优化实践。首先,我们对spark shuffle service的源码进行了深入的研究,分析了其在中通快递业务中的实际应用情况。在对源码进行全面的了解后,我们提出了一系列的优化方案,包括对shuffle read和shuffle write进行性能调优,优化shuffle数据的传输和存储方式,以及改进shuffle service的并发处理能力。
在优化实践的过程中,我们充分考虑了中通快递业务的特点和实际需求,并在实际应用中进行了有效验证。通过优化spark shuffle service,我们取得了显著的成效。夜间ETL任务的总耗时进一步减少,yarn资源占用也得到了进一步的优化,整体计算性能得到了显著提升。同时,优化后的spark shuffle service也更加稳定可靠,为中通快递的数据处理提供了更加可靠的支持。
总的来说,通过对spark shuffle service进行深入的优化实践,我们成功地解决了中通快递业务中遇到的性能瓶颈和稳定性问题,为业务的持续发展提供了可靠的数据处理支持。我们将继续致力于对大数据计算框架的优化实践,不断提升系统性能和稳定性,为中通快递的未来发展打下坚实的基础。
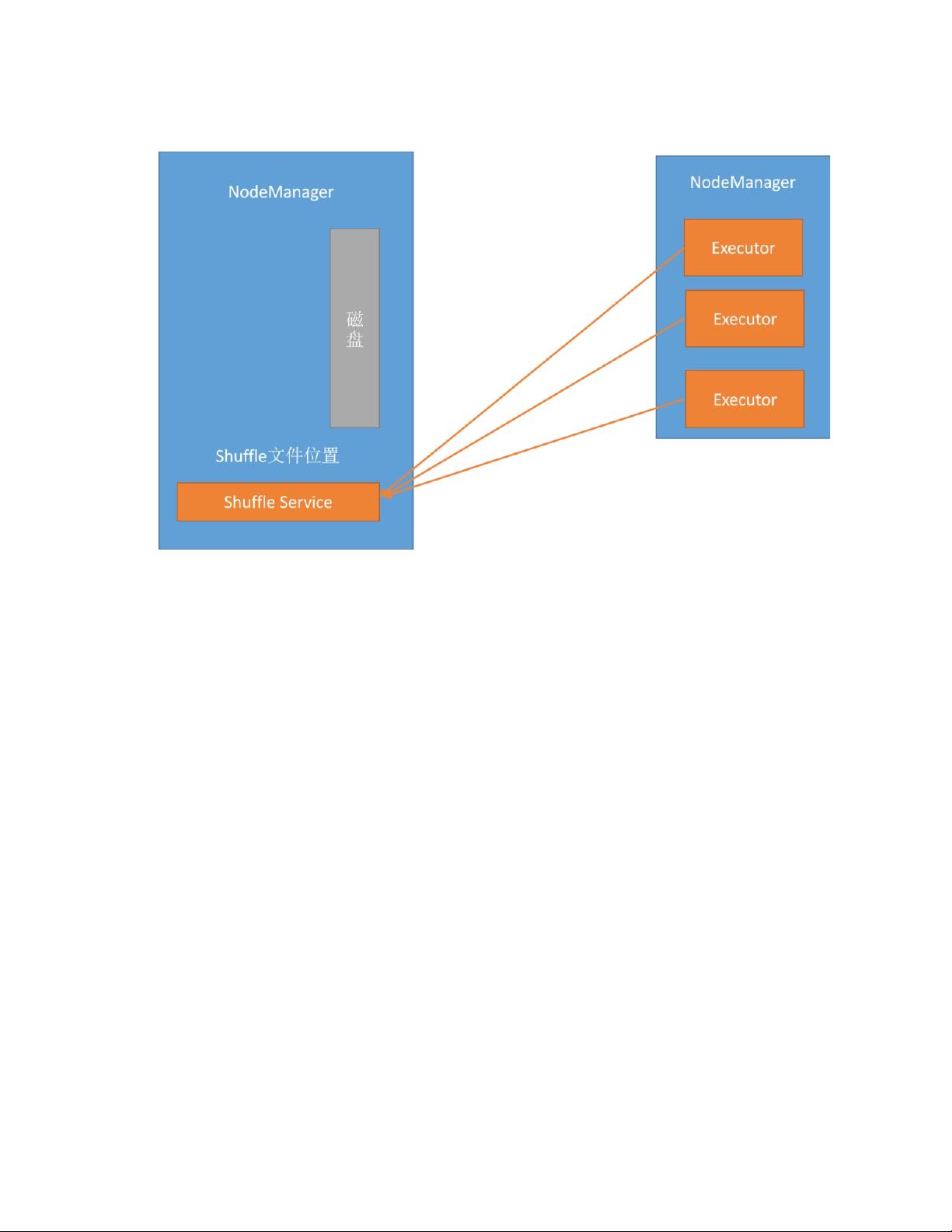
shuffle 文件读取:
二、shue service 引起的 NodeManager 特别
2.1、缓存引起的 NodeManager cpu 特别
在开启 spark external shuffle service 后一段时间,我们发觉夜间 etl 高峰期
间 NodeManager cpu 利用率越来越高,随即我们在监控上加入特别自动触发
脚本,在 cpu 利用率上来超过某一阈值后,会将 NodeManager 进程信息、线
程信息、内存信息、磁盘 io 信息、打开文件信息等现场信息保存下来等待分
析;
脚本信息:
剩余17页未读,继续阅读
430 浏览量
2024-08-31 上传
2024-08-31 上传

bingbingbingduan
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- SMTPSender(iPhone源代码)
- 类似瀑布流的网格视图效果
- win7 64位安装IE11所需补丁
- WIFIRobots
- 多路DA上位机+单片机源码.zip
- cace:CMS管理员命令执行
- cursoKuberneteswildfly:Curso cursoKubernetes野蝇sobre Cubernetes
- mysql-connector-java-8.0.25.zip
- 建筑节能平台登录网页模板
- 网络游戏-基于移动无线网络、通过远程服务器进行地图解析的方法.zip
- PCBMill:PCBMill FABtotum插件
- 房屋出租管理系统.rar
- Google Chrome:trade_mark:的标签管理器-crx插件
- WindowsFormsApp1.zip
- agora:面向目标的敏捷需求获取
- webtesting-ii-guided:Web测试II模块指导项目
