支持向量回归机(SVR)原理与应用解析
需积分: 45 17 浏览量
更新于2024-09-12
1
收藏 482KB DOC 举报
"支持向量回归机(SVM从分类到回归)"
支持向量机(SVM)最初被设计用于解决二分类问题,而支持向量回归机(Support Vector Regression,SVR)则将其应用扩展到了回归分析领域。SVR的核心思想是在找到一个最优回归超平面的过程中,尽可能减小所有样本点与该超平面的“总偏差”。与SVM分类不同的是,SVR不再追求将两类样本分开的最大间隔,而是寻找使得样本点距离超平面的总偏差最小的边界。
3.3.1 SVR基本模型
在处理线性问题时,SVR会尝试用线性回归函数来拟合数据。假设输入变量为x,输出变量为y,目标是确定权重w和偏置b,以便构建函数f(x) = wx + b。为了构建这个模型,SVR引入了不灵敏度函数作为损失函数,用于衡量预测值与真实值之间的差距。
常见的损失函数有多种,例如ε-不灵敏度函数、拉普拉斯函数、高斯函数、鲁棒损失函数、多项式函数和分段多项式函数。其中,ε-不灵敏度函数是标准支持向量机中常用的选择。它假设在一定的误差范围内(ε)可以接受预测误差,超过这个范围的误差将受到惩罚。
对于ε-不灵敏度函数,如果预测误差小于或等于ε,则损失为0;否则,损失为超出ε部分的误差。因此,SVM的目标是最小化以下目标函数:
1. 使拟合函数更平坦,增强泛化能力(第一项)
2. 减小误差(第二项)
3. 对超出误差ε的样本施加惩罚(第三项)
目标函数的形式为:
J(w, b) = 1/2 * w^T * w + C * Σξ_i
其中,w^T * w是第一项,C是常数,表示对超出误差ε的样本的惩罚程度,ξ_i是松弛因子,代表每个样本点的误差。通过引入拉格朗日乘数,可以将这个问题转换为求解一组双层优化问题,以找到最佳的权重w、偏置b和拉格朗日乘数。
解决这个凸二次优化问题后,可以得到支持向量,这些支持向量是离超平面最近的样本点,它们决定了超平面的位置。最终,SVR模型可以通过支持向量确定的超平面进行预测,实现对未知数据的连续输出。
支持向量回归机(SVR)是SVM理论在回归问题上的应用,它利用ε-不灵敏度函数处理误差,寻找最优的回归超平面以最小化所有样本点的总偏差。通过解决一个凸二次优化问题,SVR可以构建出具有强泛化能力的回归模型。
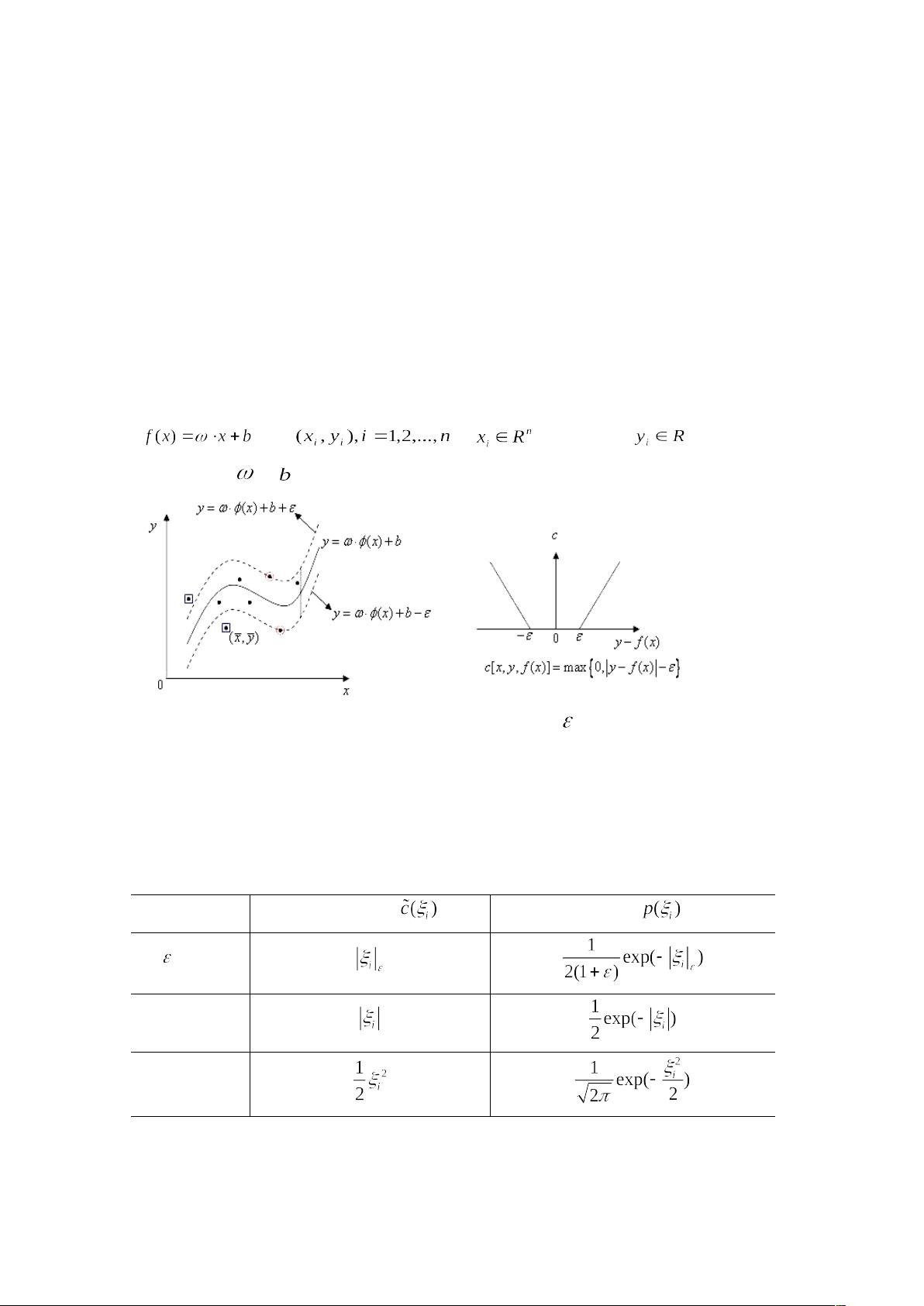
3.3 支持向量回归机
SVM
本身是针对经典的二分类问题提出的,支持向量回归机(
Support
Vector Regression
,
SVR
)是支持向量在函数回归领域的应用。
SVR
与
SVM
分
类有以下不同:
SVM
回归的样本点只有一类,所寻求的最优超平面不是使两类
样本点分得“最开”,而是使所有样本点离超平面的“总偏差”最小。这时样本点都
在两条边界线之间,求最优回归超平面同样等价于求最大间隔。
3.3.1 SVR 基本模型
对 于 线 性 情 况 , 支 持 向 量 机 函 数 拟 合 首 先 考 虑 用 线 性 回 归 函 数
拟合 , 为输入量, 为输出量,
即需要确定 和 。
图 3-3a SVR 结构图 图 3-3b 不灵敏度函数
惩罚函数是学习模型在学习过程中对误差的一种度量,一般在模型学习前
己经选定,不同的学习问题对应的损失函数一般也不同,同一学习问题选取不
同的损失函数得到的模型也不一样。常用的惩罚函数形式及密度函数如表
3-1
。
表 3-1 常用的损失函数和相应的密度函数
损失函数名称 损失函数表达式 噪声密度
-不敏感
拉普拉斯
高斯
下载后可阅读完整内容,剩余9页未读,立即下载
2019-05-22 上传
2024-04-22 上传
2022-07-14 上传
2021-10-04 上传
2019-06-28 上传
2023-09-03 上传

nishuihan19880108
- 粉丝: 4
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
