机器学习常用指标及其应用介绍:回归算法指标和分类算法指标
需积分: 0 57 浏览量
更新于2023-12-10
收藏 466KB PPTX 举报
机器学习是一种利用算法和统计学习模型来实现智能系统设计的技术。在机器学习中,常常需要使用不同的指标来评估和比较不同模型的性能。这些指标包括回归算法指标和分类算法指标,用于衡量模型预测结果与真实值之间的差异和模型分类的准确性。
在回归算法中常用的指标包括平均绝对误差(Mean Absolute Error)、均方误差(Mean Squared Error)、均方根误差(Root Mean Squared Error)和决定系数(Coefficient of determination)。平均绝对误差是预测值和真实值之间差异的绝对值的平均值,均方误差是预测值和真实值之间差异的平方的平均值,均方根误差是均方误差的平方根,决定系数用于衡量模型对数据变化的解释能力。
在分类算法中常用的指标包括精度(Accuracy)、混淆矩阵(Confusion Matrix)、准确率(Precision)、召回率(Recall)、Fβ Score、ROC曲线和AUC。精度是模型预测正确的样本数占总样本数的比例,混淆矩阵是一种用于衡量分类模型性能的矩阵,准确率是指模型将正样本预测为正样本的概率,召回率是指在所有正样本中,模型成功找到的正样本的比例,Fβ Score是准确率和召回率的加权调和平均,ROC曲线是一种用来评价分类模型的性能的图表,AUC表示ROC曲线下的面积,表示正样本的预测结果大于负样本的预测结果的概率。
此外,机器学习中还有各种损失函数,如0-1损失函数、绝对值损失函数、平方损失函数、log对数损失函数、Hinge损失函数和交叉熵损失函数。这些损失函数在模型训练和评估中起着重要的作用,根据不同的任务和数据特点选择合适的损失函数对模型性能具有重要影响。
总的来说,机器学习常用指标是衡量模型性能的重要工具,能够帮助我们评估不同模型的优劣,并选择最适合特定任务的模型。了解这些指标和损失函数的特点和应用场景对于机器学习工程师和数据科学家来说至关重要,能够帮助他们更好地设计和评估机器学习模型,提高模型的准确性和可靠性。
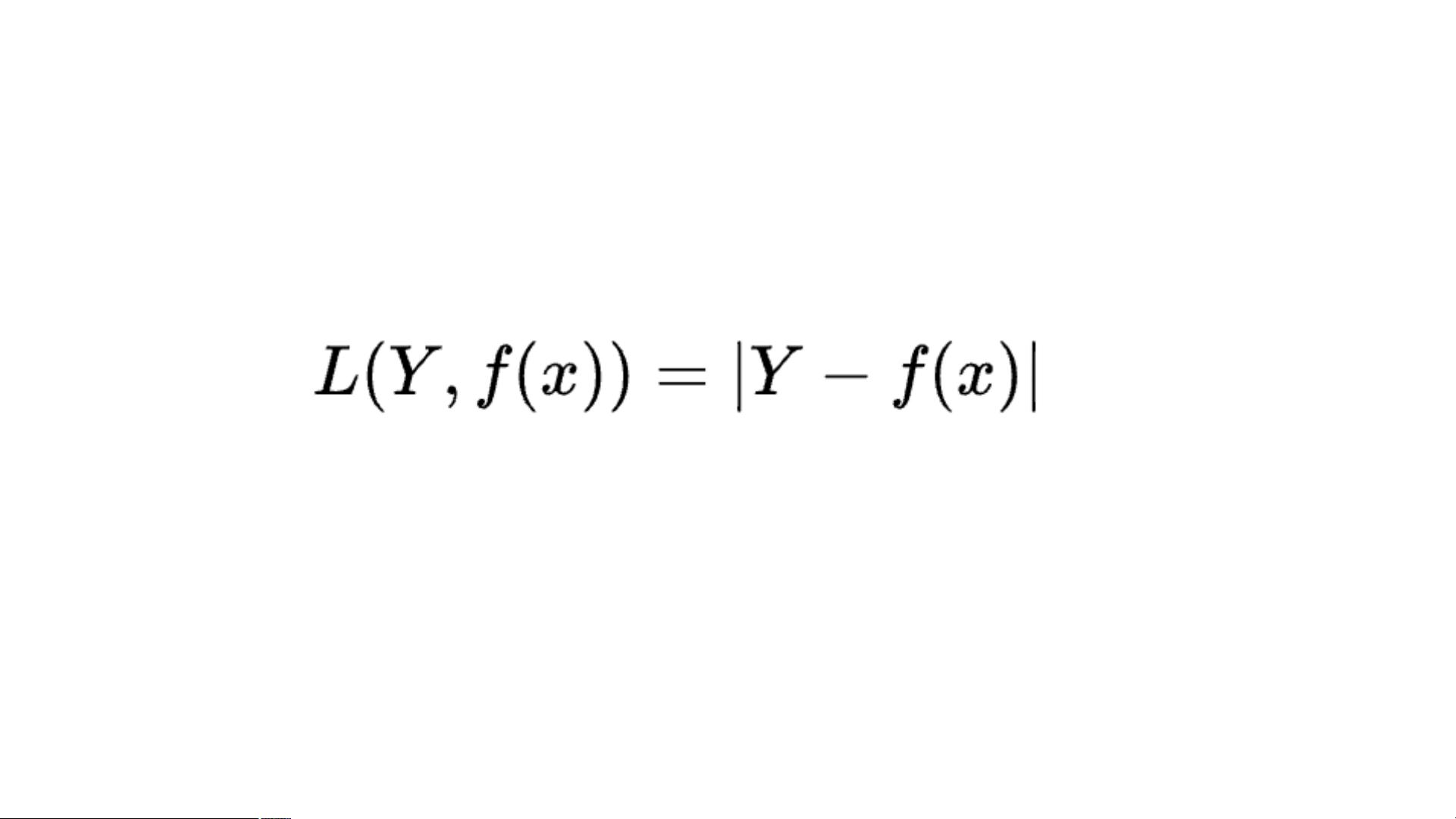
绝对值损失函数
剩余15页未读,继续阅读
132 浏览量
2021-05-11 上传
332 浏览量
2018-09-10 上传
2023-09-19 上传
2020-11-12 上传

5pig
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
