超详细教程:Gerapy、Scrapy、Scrapyd与Nginx配置及集群部署
需积分: 13 174 浏览量
更新于2024-08-05
收藏 432KB PDF 举报
"本教程详述了数据抓取过程中gerapy、scrapy、scrapyd以及nginx的安装和配置过程,特别关注了集群化部署、安全认证服务的添加以及使用nginx进行服务代理和权限控制。"
在数据抓取领域,高效管理和部署爬虫项目是至关重要的。gerapy、scrapy、scrapyd和nginx都是在这个背景下扮演关键角色的工具。首先,让我们深入了解一下这些工具及其使用方法。
**gerapy** 是一个基于 Django 的 Web 框架构建的 Scrapy 项目管理工具,提供了一个图形化的界面,方便用户对 Scrapy 项目进行远程控制、日志查看、任务调度等操作。安装 gerapy 需要先创建一个 Python 虚拟环境,然后通过 pip 安装 gerapy 包,接着初始化项目、迁移数据库并创建超级用户。最后,启动 gerapy 服务,即可在浏览器中访问其主界面。
**scrapy** 是一个强大的 Python 爬虫框架,支持快速开发和灵活扩展。在 gerapy 中,可以管理多个 scrapy 项目。安装 scrapy 通过 pip 即可,启动服务则使用 scrapyd 命令。
**scrapyd** 是 scrapy 的分布式调度服务,可以接收、管理和运行 Scrapy 项目。通过 scrapyd 可以实现多项目并行运行,提升爬虫效率。部署 scrapyd 到生产环境时,通常会结合 supervisor 实现后台守护进程,确保服务的稳定性。
**supervisor** 是一个进程控制系统,用于监控和管理后台进程。配置 scrapyd 的守护进程需要在 supervisor 的配置文件中指定 scrapyd 的绝对路径,然后通过 supervisorctl 命令进行状态查看、重新加载和重启服务。
**nginx** 是一款高性能的 HTTP 和反向代理服务器,常用于负载均衡和静态资源处理。在本教程中,nginx 用于代理 scrapyd 服务,并添加认证功能。安装 nginx 后,通过 `apache2-utils` 工具生成密码文件,然后在 nginx 的配置文件中设置代理规则和基本认证。这样,访问 scrapyd 服务时就需要提供用户名和密码,增强了安全性。
集群化部署 scrapy 项目时,可以利用 scrapyd 的 API 将任务分发到多台服务器上,实现任务的并行处理。同时,通过 gerapy 的界面可以方便地监控各个节点的状态,进行任务调度。
本教程详细介绍了如何在运维环境中配置数据抓取的相关工具,包括 gerapy 的使用、scrapy 项目的集群部署、scrapyd 的后台服务配置以及 nginx 的代理和认证服务,为高效、安全地管理和运行数据抓取项目提供了全面的指导。
创
建
python
虚
拟
环
境
crawl
1.
执
⾏
命
令
:
conda create --name crawl python=3.7
2.
安
装
完
成
后
,
进
⼊
虚
拟
环
境
:
conda activate crawl
下
⾯
所
有
python
相
关
的
操
作
都
在
此
⽬
录
下
安
装
gerapy
1.
安
装
gerapy
包
: pip install gerapy
2.
初
始
化
gerapy
:
gerapy init
执
⾏
完
毕
之
后
,
本
地
便
会
⽣
成
⼀个
名
字
为
gerapy
的
⽂
件
夹
,
同
时
⾥
⾯
包
含
logs
和
projects
⽂
件
夹
3.
初
始
化
数
据
库
:
cd gerapy && gerapy migrate
这
样
它
就
会
在
gerapy
⽬
录
下
⽣
成
⼀个
SQLite
数
据
库
,
同
时
建
⽴
数
据
库
表
4.
创
建
超
级
⽤
⼾
:
gerapy createsuperuser
根
据
提
⽰
输
⼊
⽤
⼾
名
、
密
码
即可
,
下
⾯
登
录
时
会
⽤
到
。
5.
启
动
服
务
:
gerapy runserver 0.0.0.0:8000
这
样
会
在
8000
端
口
启
动
⼀个
任
意
机
器
可
以
访
问
的
服
务
。
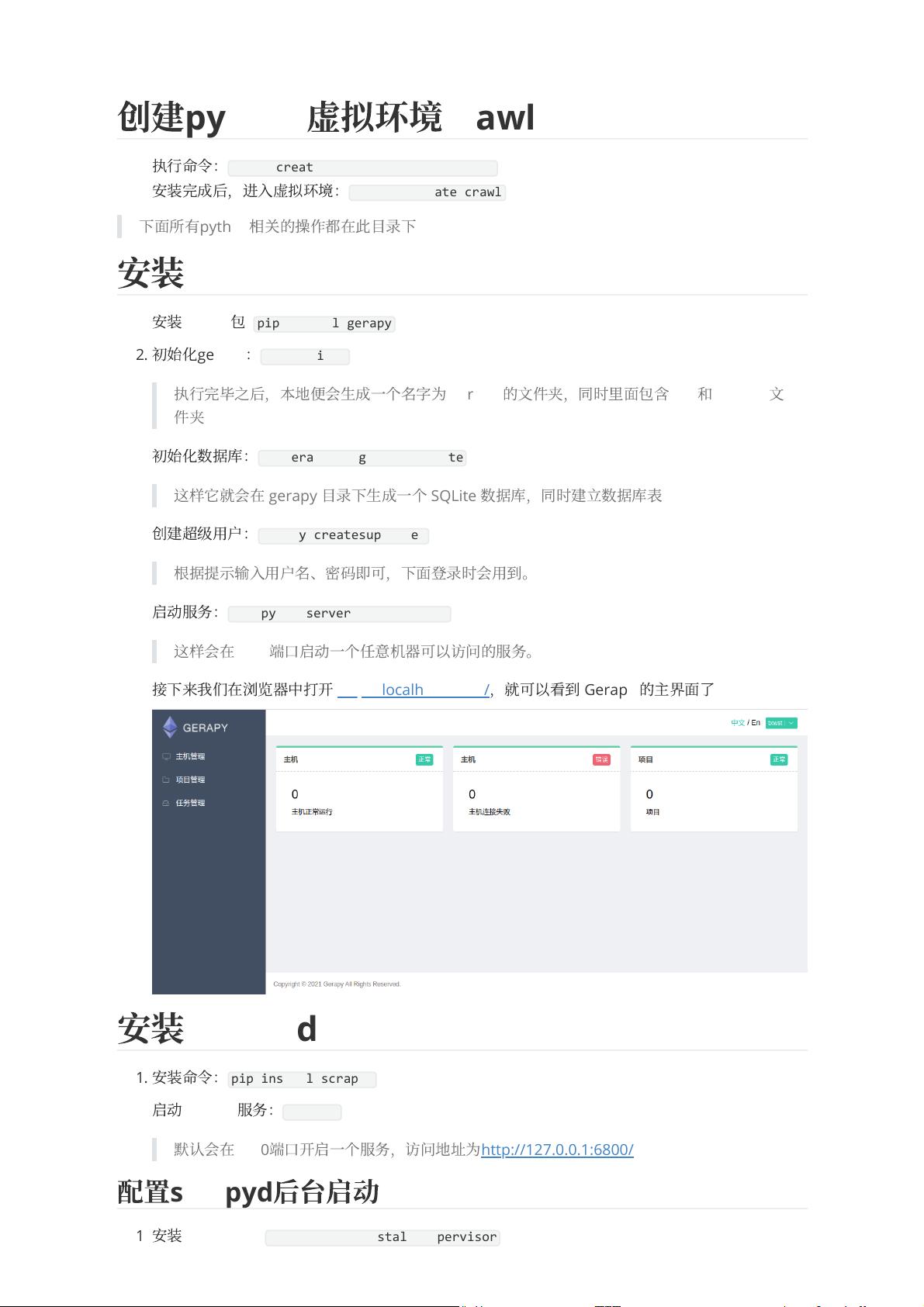
6.
接
下
来
我
们
在
浏
览
器
中
打
开
http://localhost:8000/
,
就
可
以
看
到
Gerapy
的
主
界
⾯
了
安
装
scrapyd
1.
安
装
命
令
:
pip install scrapyd
2.
启
动
scrapyd
服
务
:
scrapyd
默
认
会
在
6800
端
口
开
启
⼀个
服
务
,
访
问
地址
为
http://127.0.0.1:6800/
配
置
scrapyd
后台
启
动
1.
安
装
supervisor: sudo apt-get install supervisor
下载后可阅读完整内容,剩余3页未读,立即下载
2024-01-29 上传
127 浏览量
2021-02-05 上传
2024-08-04 上传
2021-02-26 上传
点击了解资源详情
2021-06-21 上传
2021-05-16 上传
2023-03-13 上传

wst521
- 粉丝: 27
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
