大数据处理中的数据流计算模型详解与执行引擎对比
163 浏览量
更新于2024-08-28
收藏 1.51MB PDF 举报
本文主要探讨了数据流计算模型在大数据处理中的关键作用和应用。随着无界、乱序的大规模数据集的日益增长,用户对于高效、灵活的数据处理能力的需求也在不断提升,包括对时间语义、窗口操作和处理时延的精确控制。数据流计算模型作为一种强大的工具,应运而生,它通过抽象的数据流图和统一编程模型来应对这些挑战。
首先,文章从执行引擎的角度深入剖析了数据流计算模型在大数据处理中的具体体现。数据流图(Data Flow Graph, DFG)是数据流计算的核心概念,它将数据处理过程视为一系列相互连接的节点,每个节点代表一个操作或数据源,数据沿着这些节点间的边流动,形成一个无始无终的处理流程。这有助于理解如何在分布式环境中管理和优化数据的流动,以达到实时性和低延迟的目标。
另一方面,数据流编程模型提供了一种统一的方式来编写和执行数据处理任务。这种编程模型强调事件驱动和函数式编程,使得开发者能够以简洁的方式定义处理逻辑,而不必关心底层的并发细节。它允许用户通过声明式编程来描述数据的流动路径,从而简化了复杂的数据处理任务的设计和维护。
为了更全面地评估数据流模型的实际应用,文章对比研究了多个执行引擎,如Spark的批处理引擎和Flink的流计算引擎。Spark以其强大的批处理能力闻名,适合离线数据分析,而Flink则专长于实时流处理,提供了低延迟、高吞吐量的优势。作者深入比较了这两种引擎在数据流图和数据流编程模型上的实现差异,帮助读者了解它们各自的优缺点和适用场景。
本文通过对数据流计算模型的深入分析和多引擎对比,展示了其在满足大数据处理复杂需求方面的潜力,这对于设计、开发和优化大规模数据处理系统具有重要的理论指导和实践价值。对于数据科学家、工程师以及研究人员来说,理解和掌握数据流计算模型是提升大数据处理效能的关键。
TOPIC 专题 75
操作后产生输出数据。顶点和顶点之间
通过有向边连接,每条有向边代表了数
据的流动和数据的依赖。与有向边起点
相 连 的 顶 点 表 示 数 据 的 生 产 者 ,与 有 向
边 终点 相 连的顶点表 示 数 据 的 消费 者,
数据由生产者流向消费者,消费者对数据
的处理依赖于生产者的处理结果。如
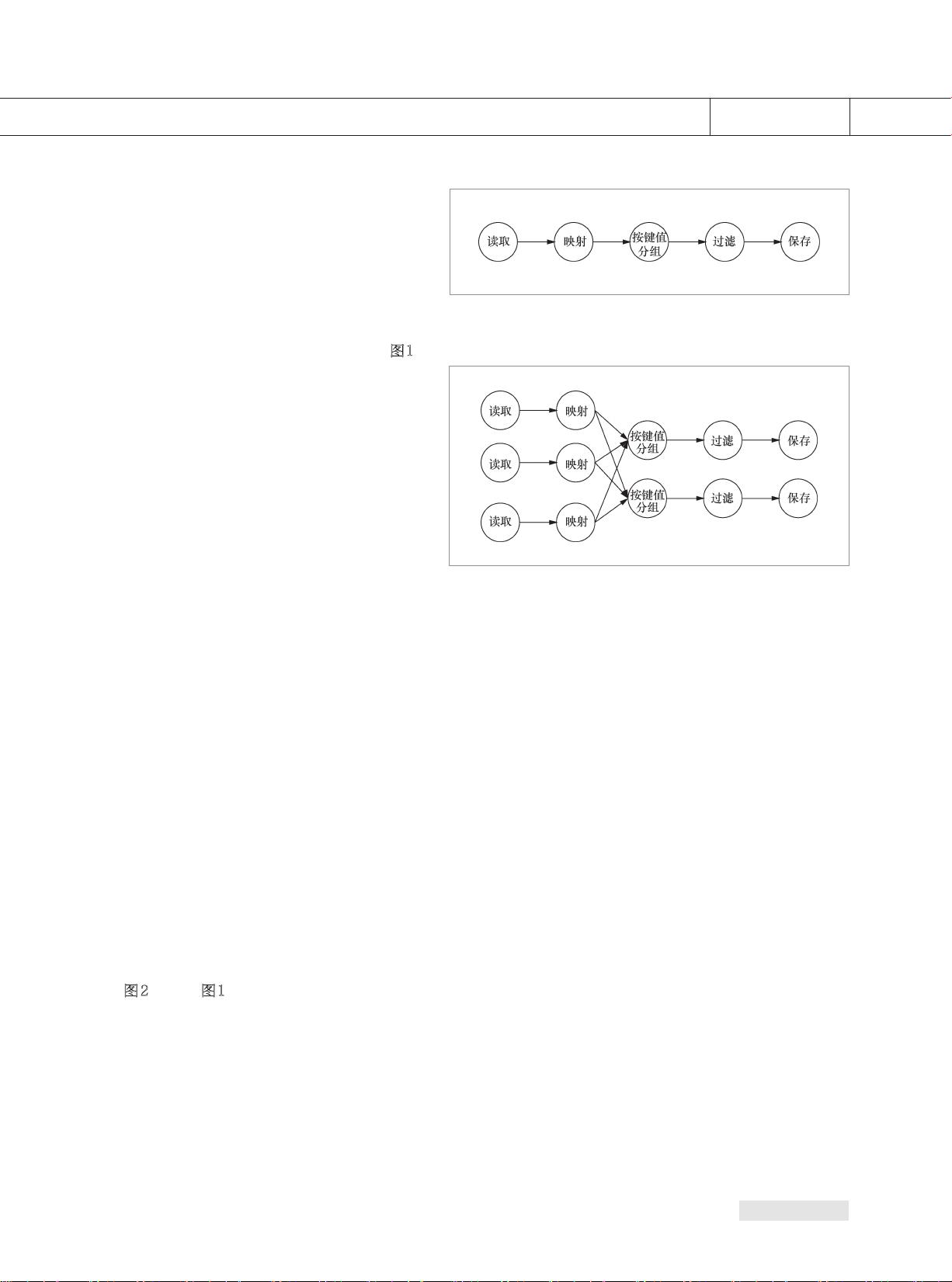
图1
所示,该逻辑数据流图由5个表示计算逻
辑的顶点和4条表示数据流动和数据依
赖 的 有 向 边 组 成 ,表 达 了 数 据 从 读 取 顶
点被读取后,依次流经映射、按键值分组
和过滤3个顶点,并在这3个顶点中进行
转换处理,最终通过保存顶点将处理结
果存储下来的整个数据处理流程。
2.2 物理数据流图
大数据处理系统通常采用并行化的
策略进行数据处理,将数据按照特定的分
区策略进行分区,并为每个数据处理顶点
设定并行度,让不同的数据分区流入各自
相应的数据处理顶点实例,以达到并行
处理的目的。但是逻辑数据流图中的顶
点和边仅仅是对处理过程的逻辑抽象,
即每个顶点是一个逻辑的处理步骤,不
包含系统实际处理数据时并行化的概
念,每条边也只描述了逻辑顶点之间的数
据流动。因此,逻辑数据流图不能被直接
应用到底层执行引擎,而需要先在逻辑
数 据 流 图 中 引 入 并 行 度 ,将 其 转 换 为 物
理数据流图后才能交给底层执行引擎。
图2展示了图1中描述的逻辑数据流图根
据特定的并行度转换后得到的物理数据
流图,该物理数据流图中读取和映射2个
数 据 处 理 顶 点 的 并 行 度 为 3 ,按 键 值 分
组、过滤和保存3个数据处理顶点的并
行度为2。由于批处理引擎和流计算引擎
2种执行引擎的数据交换机制不同,物理
数据流图在这2种执行引擎中的具体体
现也有所不同。
2.2.1 批处理引擎中的物理数据流图
在批处理引擎中,一个物理数据流图
通常被划分为多个阶段,阶段之间根据依
赖关系按序执行,一个阶段只有等其依赖
的所有阶段都执行结束后才能开始执行。
每个阶段由与分区数相同个数的任务组
成,一个任务负责一个分区,各个任务之
间相互独立执行,不会发生数据交换。当
某个任务中的一条数据被处理完成后,并
不会立刻通过网络将其传输到下一个阶段
的任务中,而是 先 将 其 放 在 缓存 中,当缓 存
达 到 一 定 的 阈 值 时 ,再 将 缓 存 中 的 数 据 溢
写到本地磁盘上。只有当一个阶段中所有
的任务都完成数据处理,并将处理结果写
入 磁 盘 后 ,才 开 始 将 这 个 阶 段 处 理 后 的 中
间结果通过网络传输到下一个阶段进行后
续处理。
例如,在基于批处理引擎的Spark系
统中,将每个逻辑数据流图根据给定的并
图 1 逻辑数据流图
图 2 物理数据流图
2020025-3
剩余13页未读,继续阅读
2021-09-14 上传
2021-09-14 上传
2023-04-24 上传
2023-11-04 上传
2024-10-26 上传
2023-09-02 上传
2024-10-27 上传
2023-06-28 上传

weixin_38587473
- 粉丝: 7
- 资源: 891
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
