2023年ChatGPT技术解析:从原理到开源趋势
版权申诉
99 浏览量
更新于2024-06-13
收藏 88.36MB PDF 举报
《OneFlow技术年货(2023)》是一篇深入探讨了当前热门话题——ChatGPT及其背后技术的文章。它涵盖了多个关键知识点,从ChatGPT的技术原理到语言大模型的发展历程,再到开源语言模型的崛起和训练策略。
首先,文章揭秘了ChatGPT的核心技术,包括编码器和解码器语言模型的工作原理,以及GPTTokenizer的具体实现。通过解析其数据集的秘密和训练过程,包括强化学习(RLHF)的应用,解释了为何选择这种非监督学习方法,以及GPT-3/ChatGPT在技术上的成功经验与教训。
接着,文章详细讨论了语言大模型的演进,特别是如何通过100K上下文窗口来提升模型的性能,以及数据集的选择和组合策略对于模型效果的重要性。此外,还针对大模型处理长上下文的能力、争议和局限性进行了深入分析,强调了复杂推理在模型智能中的关键地位,并探讨了超越ChatGPT的潜在路径。
开源语言大模型部分,文章聚焦于ChatGPT发布一年后对开源社区的影响,回顾了开源语言模型的三个发展阶段,从早期革新到高质量模型竞赛,再到与LLaMA2等先进模型的追赶。文章指出开源模型的价值,并提供了正确的使用和训练建议。
在实际应用层面,文章涵盖了语言大模型的预训练、微调和推理技术。从分布式训练和高效微调策略,到对比GPT-3.5和LLaMA2的微调差异,以及LoRA、QLoRA等微调技术的比较和优化技巧。同时,文章深入剖析了模型规模、计算成本和推理性能的优化,提出了全栈Transformer推理的最佳实践。
《OneFlow技术年货(2023)》提供了一个全面的视角,不仅揭示了ChatGPT技术的内在机制,还对未来语言模型的发展趋势进行了前瞻性的讨论,对于理解并利用这些技术的开发者和研究者来说,具有很高的参考价值。
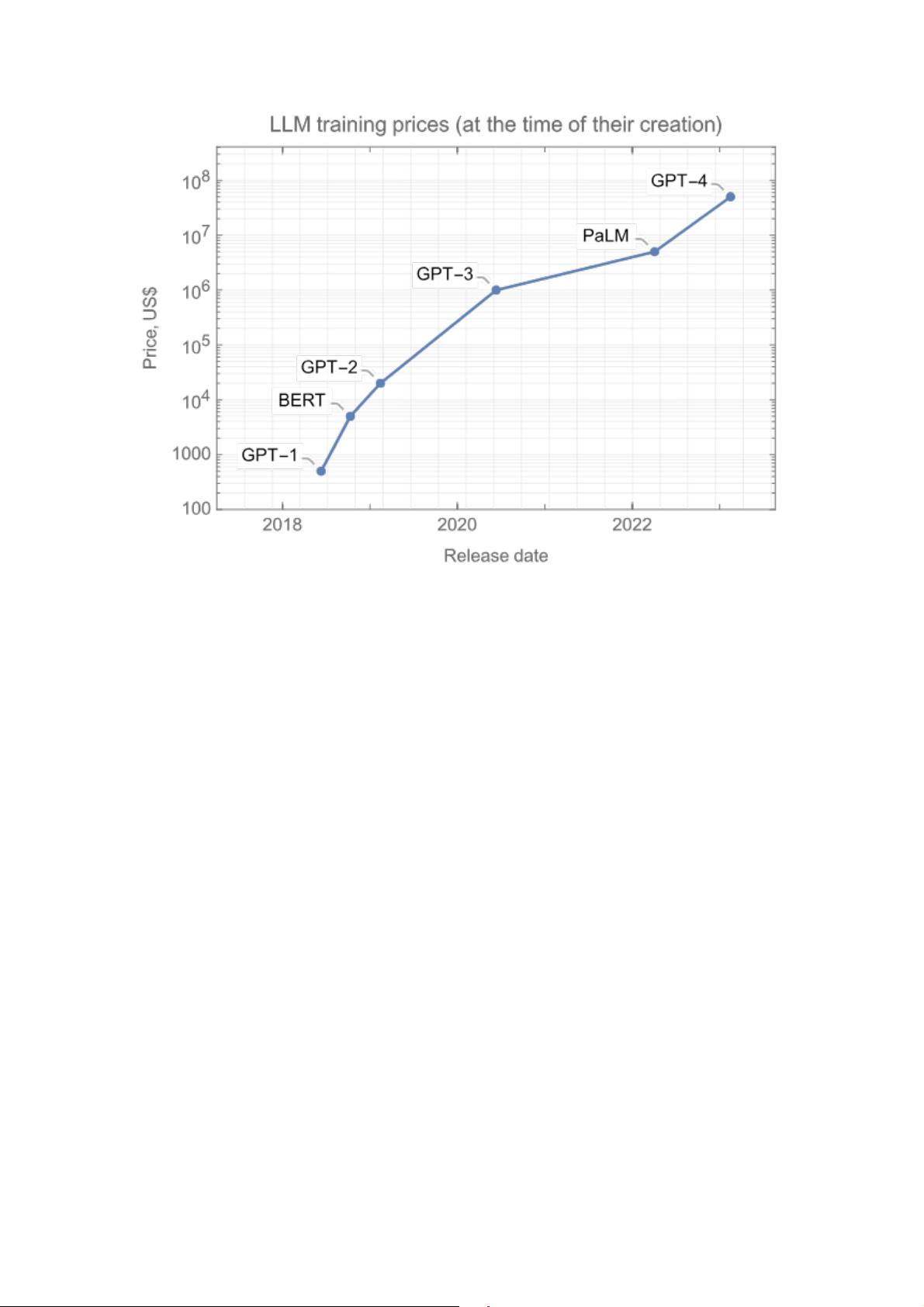
16
为显著超越当前模型的性能,下一代模型需要耗费数亿美元的计算资源。虽然考虑到这些模型
能带来的好处,这一成本是合理的,但如此巨大的花费仍然是一个问题。
模型的扩展变得越来越困难。幸运的是,扩大规模并不是改进 LLM 的唯一途径。2022 年末,
一项创新开启了另一场革命,这次的影响远远超出了 NLP 领域。
5. 指令调优和聊天机器人 LLM
GPT-3 揭示了提示的潜力,但撰写提示并不容易。事实上,传统语言模型经训练可以模仿其
在网络上看到的内容。因此,要想创建一个好的提示,你必须清楚网络上哪种起始文本可能会
引导模型生成你所期望的结果。这是一种奇怪的游戏,也是一种找到正确表述的艺术,你需要
改变措辞,假装自己是专家,展示如何逐步思考的示例等等。这一过程叫做提示工程,这使得
使用这些 LLM 变得困难。
为解决这个问题,研究人员一直在探索如何修改基础 LLM,以让其更好地遵循人类指令。现
主要有两种方法:一是使用人类编写的指令-回答对(instruction-answer pairs),并在此数据
集上对基础 LLM 进行微调(即继续训练)。二是让 LLM 生成几个可能的答案,然后由人类对



剩余872页未读,继续阅读
2020-04-09 上传
2021-09-15 上传
2019-02-13 上传
2022-05-21 上传
2021-02-06 上传
2021-02-27 上传
2020-04-09 上传

猫头虎
- 粉丝: 34w+
- 资源: 599
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
