2007年Frey提出的Affinity Propagation聚类算法:高效发现大规模数据的代表性类
Affinity Propagation是一种由Brendan J. Frey和Delbert Dueck在2007年发表于《科学》(Science)杂志上的创新聚类算法。这一独特的算法旨在解决传统聚类方法中存在的问题,特别是当数据集包含大量类别且事先未知的集群数量时。其核心思想是通过在数据点之间传递相似性度量的消息来进行无监督学习,从而自动发现代表性的样本(exemplars)并形成相应的簇。
算法流程分为两个主要步骤:首先,输入数据集中的每对数据点之间的相似性或亲和力(affinity)矩阵,这些矩阵通常由某种距离度量或相似性度量计算得出,如欧氏距离、余弦相似度等。然后,数据点之间开始交换实值消息,这些消息反映了它们对成为其他点的代表候选人的支持程度。这个过程被称为“消息传递”。
在迭代过程中,数据点根据收到的消息调整其对其他点的支持度,并更新自身作为代表的能力。随着时间的推移,高质量的代表性样本和它们对应的簇逐渐形成,而无需人工设定初始簇的数量。这种方法的优势在于它能够自适应地找到最佳的聚类结构,避免了因初始选择不佳而导致的传统方法可能面临的低效或错误结果。
Affinity Propagation的应用广泛,包括但不限于图像人脸识别(通过识别人脸的特征),基因表达数据中的基因检测(通过识别模式或相关性),文本数据中关键句子的选择,以及航空旅行数据中高效访问城市网络的发现。由于其高效性和准确性,相比于其他聚类算法,如K-means或层次聚类,Affinity Propagation能够在更短的时间内产生更低的错误率。
总结来说,Affinity Propagation是一种强大的无监督聚类工具,它的独特之处在于无需预设聚类数量,通过智能的消息传递机制找出数据的内在结构,适用于处理大规模复杂数据集,极大地提升了数据挖掘和分析的效率与精度。在现代信息技术领域,特别是在大数据和机器学习领域,这种算法的应用前景广阔。
linear program with a constant factor approxima-
tion. There, the input was assumed to be metric,
i.e., nonnegative, symmetric, and satisfying the
triangle inequality . In contrast, affinity propagation
can take as input general nonmetric similarities.
Affinity propagation also provides a conceptually
new approach that works well in practice. Where-
as the linear programming relaxation is hard to
solve and sophisticated software packages need to
be applied (e.g., CPLEX) , affinity propa gation
makes use of intuitive message updates that can
be implemented in a few lines of code (2).
Affinity propagation is related in spirit to tech-
niques recently used to obtain record-breaking
results in quite different disciplines (16). The ap-
proach of recursively propagating messages
(17)ina“loopy graph” has been used to ap-
proach Shannon’s limit in error-correcting de-
coding (18, 19), solve random satisfiability
problems with an order-of-magnitude increase in
size (20), solve instances o f the NP-hard two-
dimensional phase-unwrapping problem (21), and
efficiently estimate depth from pairs of stereo
images (22). Yet, to our knowledge, affinity prop-
agation is the first method to make use of this idea
t o s o l ve the age-old , fundamental problem of
clustering data. Because of its simplicity, general
applicability, and performance, we believ e aff in -
ity propagation will prove to be of broad value in
science and engineering.
References and Notes
1. J. MacQueen, in Proceedings of the Fifth Berkeley
Symposium on Mathematical Statistics and Probability,
L. Le Cam, J. Neyman, Eds. (Univ. of California Press,
Berkeley, CA, 1967), vol. 1, pp. 281–297.
2. Supporti ng material is available on Science Online.
3. Software implementations of affinity propagation, along
with the data sets and similarities used to obtain the
results described in this manuscript, are available at
www.psi.toronto.edu/affinitypropagation.
4. B. J. Frey et al., Nat. Genet. 37 , 991 (2005).
5. K. D. Pruitt, T. Tatusova, D. R. Maglott, Nucleic Acids Res.
31, 34 (2003).
6. C. D. Manning, H. Schutze, Foundations of Statistical
Natural Language Processing (MIT Press, Cambridge, MA,
1999).
7. J. J. Hopfield, Proc. Natl. Acad. Sci. U.S.A. 79, 2554 (1982).
8. M. Charikar, S. Guha, A. Tardos, D. B. Shmoys, J. Comput.
Syst. Sci. 65, 129 (2002).
9. J. S. Yedidia, W. T. Freeman, Y. Weiss, IEEE Trans. Inf.
Theory 51, 2282 (2005).
10. F. R. Kschischang, B. J. Frey, H.-A. Loeliger, IEEE Trans.
Inf. Theory 47, 498 (2001).
11. A. P. Dempster, N. M. Laird, D. B. Rubin, Proc. R. Stat.
Soc. B 39, 1 (1977).
12. S. Dasgupta, L. J. Schulman, Proc. 16th Conf. UAI (Morgan
Kaufman, San Francisco, CA, 2000), pp. 152–159.
13. S. Jain, R. M. Neal, J. Comput. Graph. Stat. 13, 158
(2004).
14. R. R. Sokal, C. D. Michener, Univ. Kans. Sci. Bull. 38 ,
1409 (1958).
15. J. Shi, J. Malik, IEEE Trans. Pattern Anal. Mach. Intell. 22,
888 (2000).
16. M. Mézard, Science 301, 1685 (2003).
17. J. Pearl, Probabilistic Reasoning in Intelligent Systems
(Morgan Kaufman, San Mateo, CA, 1988).
18. D. J. C. MacKay, IEEE Trans. Inf. Theory 45, 399 (1999).
19. C. Berrou, A. Glavieux, IEEE Trans. Commun. 44, 1261
(1996).
20. M. Mézard, G. Parisi, R. Zecchina, Science 297, 812 (2002).
21. B. J. Frey, R. Koetter, N. Petrovic, in Proc. 14th Conf.
NIPS (MIT Press, Cambridge, MA, 2002), pp. 737–743.
22. T. Meltzer, C. Yanover, Y. Weiss, in Proc. 10th Conf. ICCV
(IEEE Computer Society Press, Los Alamitos, CA, 2005),
pp. 428–435.
23. We thank B. Freeman, G. Hinton, R. Koetter, Y. LeCun,
S. Roweis, and Y. Weiss for helpful discussions and
P. Dayan, G. Hinton, D. MacKay, M. Mezard, S. Roweis,
and C. Tomasi for comments on a previous draft of this
manuscript. We acknowledge funding from Natural
Sciences and Engineering Research Council of Canada,
Genome Canada/Ontario Genomics Institute, and the
Canadian Institutes of Health Research. B.J.F. is a Fellow
of the Canadian Institute for Advanced Research.
Supporting Online Material
www.sciencemag.org/cgi/content/full/1136800/DC1
SOM Text
Figs. S1 to S3
References
26 October 2006; accepted 26 December 2006
Published online 11 January 2007;
10.1126/science.1136800
Include this information when citing this paper.
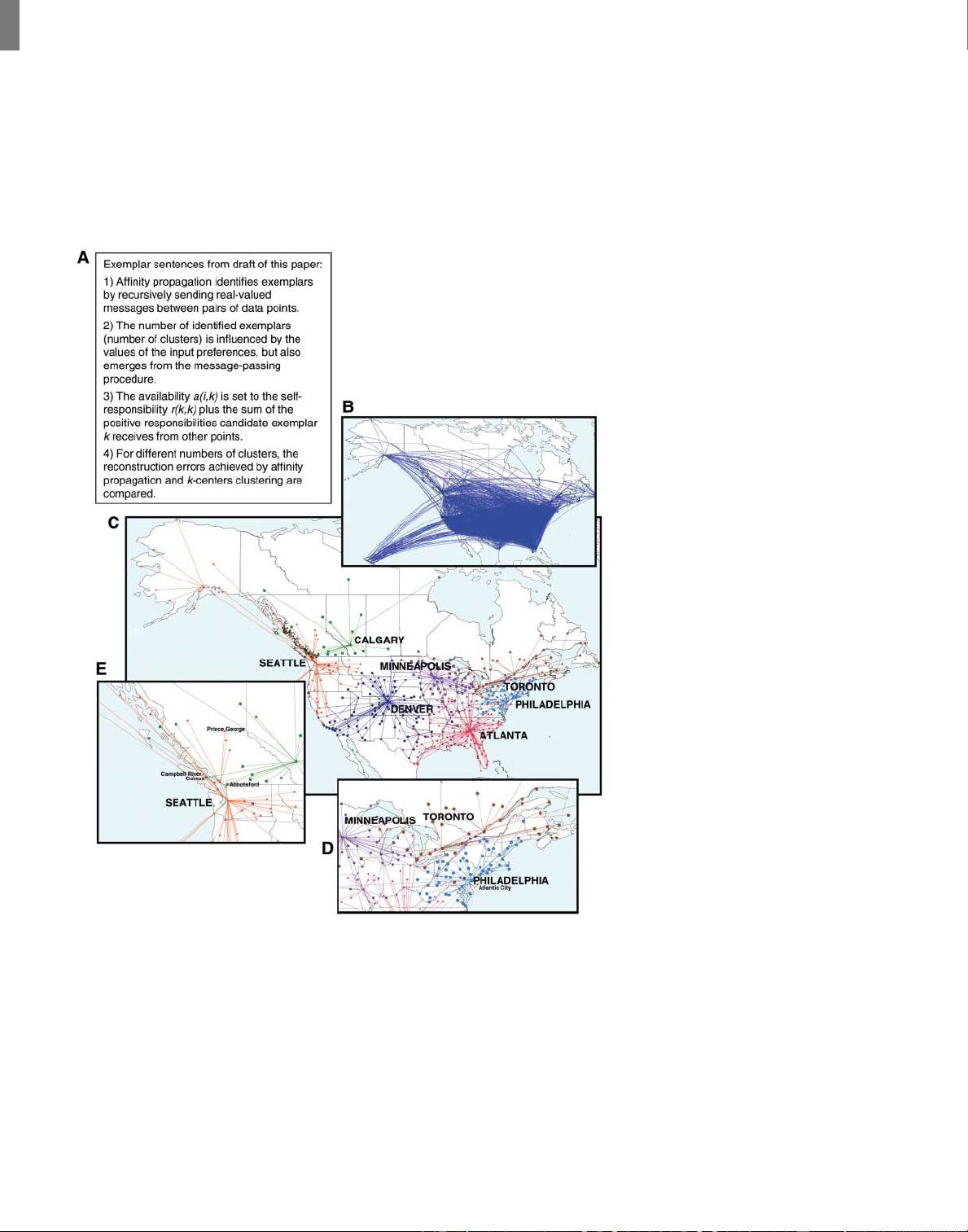
Fig. 4. Identifying key sentences and air-travel routing. Affinity propagation can be used to explore
the identification of exemplars on the basis of nonstandard optimization criteria. (A) Similarities between
pairs of sentences in a draft of this manuscript were constructed by matching words. Four exemplar
sentences were identified by affinity propagation and are shown. (B) Affinity propagation was applied to
similarities derived from air-travel efficiency (measured by estimated travel time) between the 456 busiest
commercial airports in Canada and the United States—the travel times for both direct flights (shown in
blue) and indirect flights (not shown), including the mean transfer time of up to a maximum of one
stopover, were used as negative similarities (3). (C) Seven exemplars identified by affinity propagation are
color-coded, and the assignments of other cities to these exemplars is shown. Cities located quite near to
exemplar cities may be members of other more distant exemplars due to the lack of direct flights between
them (e.g., Atlantic City is 100 km from Philadelphia, but is closer in flight time to Atlanta). (D)Theinset
shows that the Canada-USA border roughly divides the Toronto and Philadelphia clusters, due to a larger
availability of domestic flights compared to international flights. However, this is not the case on the west
coast as shown in (E), because extraordinarily frequent airline service between Vancouver and Seattle
connects Canadian cities in the northwest to Seattle.
16 FEBRUARY 2007 VOL 315 SCIENCE www.sciencemag.org
976
REPORTS
on February 15, 2007 www.sciencemag.orgDownloaded from
剩余22页未读,继续阅读
2014-03-26 上传
2020-01-09 上传
2019-08-24 上传
点击了解资源详情
点击了解资源详情
2018-05-16 上传
146 浏览量
点击了解资源详情

ght1102
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
