深度学习与自然语言处理:对抗攻击与防御的综述
版权申诉
"这篇文档是关于自然语言处理中对抗攻防与鲁棒性分析的综述,主要讨论了深度神经网络在NLP领域的应用及其易受对抗文本攻击的问题,同时涵盖了现有的防御策略和未来的研究方向。"
在自然语言处理(NLP)领域,深度神经网络(DNNs)已成为核心技术,广泛应用于机器翻译、自动文本摘要、语音识别、信息抽取与过滤、文本分类等多种任务。然而,随着DNNs的普及,其安全性问题逐渐暴露出来。研究表明,DNNs容易受到对抗性攻击,即通过微小且难以察觉的文本扰动来误导模型的预测结果。这种现象在图像识别领域也有所体现,但NLP领域的攻击方式因文本的结构和语言逻辑而有所不同。
对抗性攻击在NLP中的实现通常涉及生成对抗文本,这类文本能够绕过模型的识别,导致错误的预测。例如,Jia等人首次展示了如何在NLP模型上构造对抗性实例。此后,一系列的对抗攻击策略被提出,包括利用词汇替换、句子结构修改等方式来创建混淆模型的输入。
为了提升模型的鲁棒性,防御策略也得到了研究人员的关注。这些策略主要包括对抗训练、输入清洗、模型集成以及基于解释的方法等。对抗训练通过在训练数据中加入对抗样本,使模型学习抵抗这些攻击的能力。输入清洗则是对输入数据进行预处理,去除或修正可能的对抗性扰动。模型集成则利用多个模型的预测结果,减少单一模型被欺骗的可能性。基于解释的方法则通过模型的可解释性来检测和修复潜在的对抗性输入。
此外,对NLP模型的可验证鲁棒性分析和评估基准数据集的建立也是关键。可验证鲁棒性意味着模型在特定的攻击下能保持稳定的性能。目前,已经有一些公开的数据集用于测试模型的对抗性抵抗力,如TextFooler、DeepWordBug等。同时,开发了如NLPAug、TextAttack等工具包,方便研究者进行对抗性实验和模型优化。
未来的研究方向可能会集中在几个方面:一是探索更有效的防御方法,如开发新的抗攻击模型结构或者改进现有模型的训练策略;二是深化对模型脆弱性的理解,寻找对抗性攻击的新模式;三是推动可解释性NLP的研究,以便更好地理解和量化模型的决策过程;四是构建更加复杂和真实的对抗环境,以模拟实际应用中的安全挑战。
这篇综述文献全面梳理了NLP领域的对抗攻防现状,为该领域的研究提供了有价值的参考,同时也揭示了该领域在未来面临的挑战和可能的发展趋势。

/0.,1 模型
由于 /0. 无法建模超过固定长度的依赖关系,对长文本
编码效果差,且把要处理的文本分割成等长的片段,通常不考虑句子
语义边界,导致上下文碎片化因此, 等人
提出 /0.,
1 模型,使用片段级递归机制,通过引入一个记忆模块,循环用来建
模片段之间的联系,使得片段之间产生交互,解决编码长距离依赖和
上下文碎片化问题/0.,1 模型还使用了相对位置编码机制,
代替绝对位置编码,这是为了实现片段级递归机制而提出,解决可能
出现的时序混淆问题
1.6 XLNet 模型
1 模型
与 26)/ 模型
%
类似的是同样遵循两阶段的过程:
第 个阶段是语言模型预训练阶段;第 阶段是任务数据微调阶
段1 模型主要改动第 个阶段,它不同于 26)/ 模型带掩码符号
的降噪自编码模式,而是采用自回归语言模型的模式通过对输入全排
列来引入上下文信息,并利用双流自注意力机制和注意力掩码实现更
好的效果此外,1 模型直接使用了相对位置编码,并将递归机制
整合到全排列设定中对于生成类的任务,能够在维持表面从左向右的
生成过程前提下,学习隐含上下文的信息,比 26)/ 模型具有更明显
优势
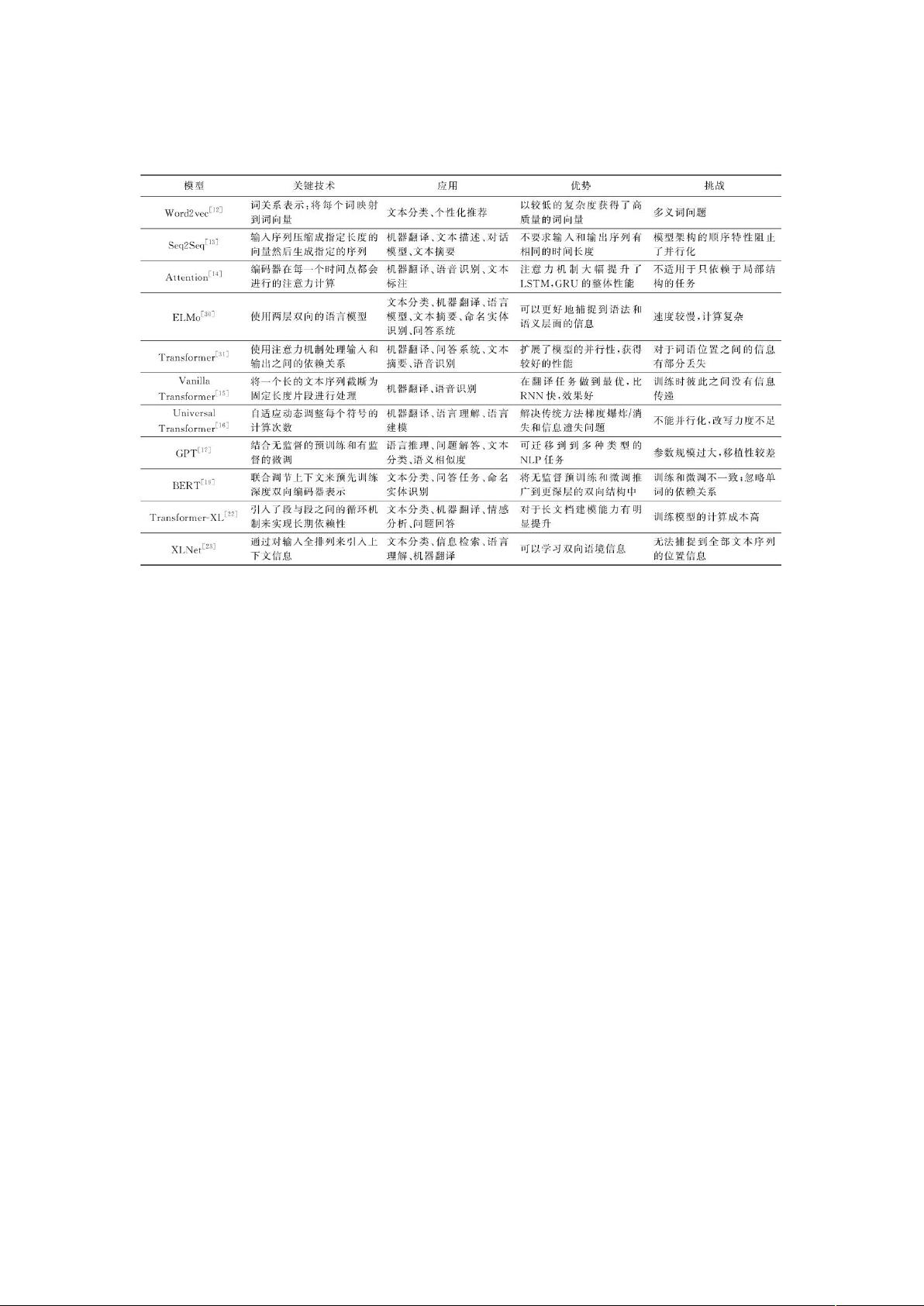
根据上述对 模型的介绍,我们进一步整理并总结其中的关键
技术、应用、优势以及待解决的挑战,如表 所示@
剩余47页未读,继续阅读
2021-09-05 上传
2020-04-19 上传
2023-02-23 上传
2023-08-28 上传
2023-08-02 上传

罗伯特之技术屋
- 粉丝: 4415
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
