"泰坦尼克号幸存者预测:使用多种机器学习方法"
 已收录资源合集
已收录资源合集
需积分: 0 17 浏览量
更新于2023-12-28
收藏 1.06MB PDF 举报
本文基于Kaggle上的一个著名机器学习项目Titanic: Machine Learning from Disaster,通过数据清洗,并使用不同的机器学习方法预测泰坦尼克号幸存者。通过研究和实践,本文列出了几种不同的机器学习方法,包括决策树、随机森林、支持向量机等,分别应用于泰坦尼克号的乘客数据集,通过对比它们的准确率来评估不同方法的效果。在项目简介部分,介绍了泰坦尼克号沉船事件的背景和数据集的特征,以及项目的目的和意义。通过实验,本文得出了不同机器学习方法在预测泰坦尼克号幸存者方面的优缺点,并提出了未来改进的方向。最后,通过对不同机器学习方法的比较和分析,得出了结论和总结,并展望了未来的研究方向。
关键词:机器学习,泰坦尼克号,幸存者,数据清洗,决策树,随机森林,支持向量机。
一、项目简介
泰坦尼克号沉船事件是历史上著名的海难事件之一,1912年4月15日,泰坦尼克号在首次航行中与冰山相撞后沉没,造成大约1500名乘客和船员死亡。这一事件引起了世界范围内的轰动和关注,也成为了后人研究的对象之一。泰坦尼克号的乘客数据集包含了乘客的姓名、年龄、性别、船舱等级、船票价格和是否幸存等信息。通过对这些数据的清洗和分析,可以帮助我们更好地了解当时的情况,并且通过机器学习方法来预测幸存者,也可以为类似事件的预防和救援提供一定的参考。
二、数据清洗
在进行机器学习之前,首先需要对数据集进行清洗,包括处理缺失值、异常值和无关数据,以及对数据进行特征工程等。在泰坦尼克号的乘客数据集中,我们发现了一些缺失值和异常值,比如年龄和船舱等级等,需要进行处理。同时,对数据进行特征工程,比如对性别和船舱等级进行独热编码,以便后续的机器学习算法能够更好地处理这些特征。通过数据清洗和特征工程,我们得到了一份清洗后的数据集,可以用于后续的机器学习模型。
三、机器学习方法
本文尝试了几种不同的机器学习方法来预测泰坦尼克号的幸存者,包括决策树、随机森林和支持向量机。这些方法分别代表了分类算法、集成算法和核方法,通过对比它们的预测准确率,可以得出不同方法的优劣,也可以为选择合适的方法提供参考。在实验中,我们使用了Python编程语言和相关的机器学习库,比如scikit-learn和pandas等,来构建和训练这些机器学习模型,并评估它们的性能。通过对几种不同方法的预测结果进行对比和分析,可以得出它们的优缺点,以及对泰坦尼克号幸存者预测的不同贡献。
四、实验结果
实验结果表明,随机森林方法在泰坦尼克号幸存者预测中表现较为优异,其准确率高于其他方法。随机森林是一种集成学习算法,能够通过多个决策树的组合来提高预测的准确性,适用于复杂的分类问题。相比之下,决策树和支持向量机在这个问题上的表现略显一般,其准确率不如随机森林。这可能是因为决策树和支持向量机对数据的分布和特征的处理方式不够灵活,导致了预测的准确性下降。然而,随机森林也并非没有缺点,比如在处理过拟合和算法解释方面存在一定的局限性,需要进一步的改进和优化。
五、结论与展望
通过对不同机器学习方法的比较和分析,本文得出了结论:随机森林是一种较为合适的方法,用于预测泰坦尼克号的幸存者。其优异的准确率和对复杂性问题的处理能力,使其成为了这个问题的首选方法。在未来,可以对随机森林进行进一步的优化和改进,比如调整参数、增加特征工程和数据集的扩充等,以提高其预测的准确性。另外,也可以尝试其他的机器学习方法,比如深度学习和强化学习等,来挖掘泰坦尼克号数据集中的更多信息,为预测幸存者提供更多的参考和帮助。希望本文的研究成果能够对类似事件的预防和救援工作有所启发和促进。
几种不同的机器学习方法预测泰坦尼克号幸存者
4
图 1 比赛项目界面
二、工作流程
1. 定义问题:在解决问题之前,我们必须要明白问题是什么。
2. 收集数据,数据清洗:是将原始数据转换为计算机可读取识别处理数据的必需过程。数据包括实现用于
存储和处理的数据架构,开发用于质量和控制的数据治理标准,数据提取(即 ETL 和网络抓取)以及用于识别异
常,丢失或异常数据点的数据清理。
3. 探索性分析:部署描述性和图形化统计信息以查找数据集中的潜在问题,模式,分类,相关性和比较非
常重要。此外,数据分类(即定性与定量)对于理解和选择正确的假设检验或数据模型也很重要。
4. 模型数据:与描述性和推论性统计数据一样,数据建模可以汇总数据或预测未来结果。
5. 验证和实施数据模型:在根据数据子集训练模型后,是时候测试模型了。这有助于确保不会过度拟合模
型或使其特定于所选子集,因为它不能准确地适合同一数据集中的另一个子集。在这一步中,我们确定我们的模
型是否适合,概括或不适合我们的数据集。
6. 优化和策略:改进模型,让它更好,更强,比以前更快。
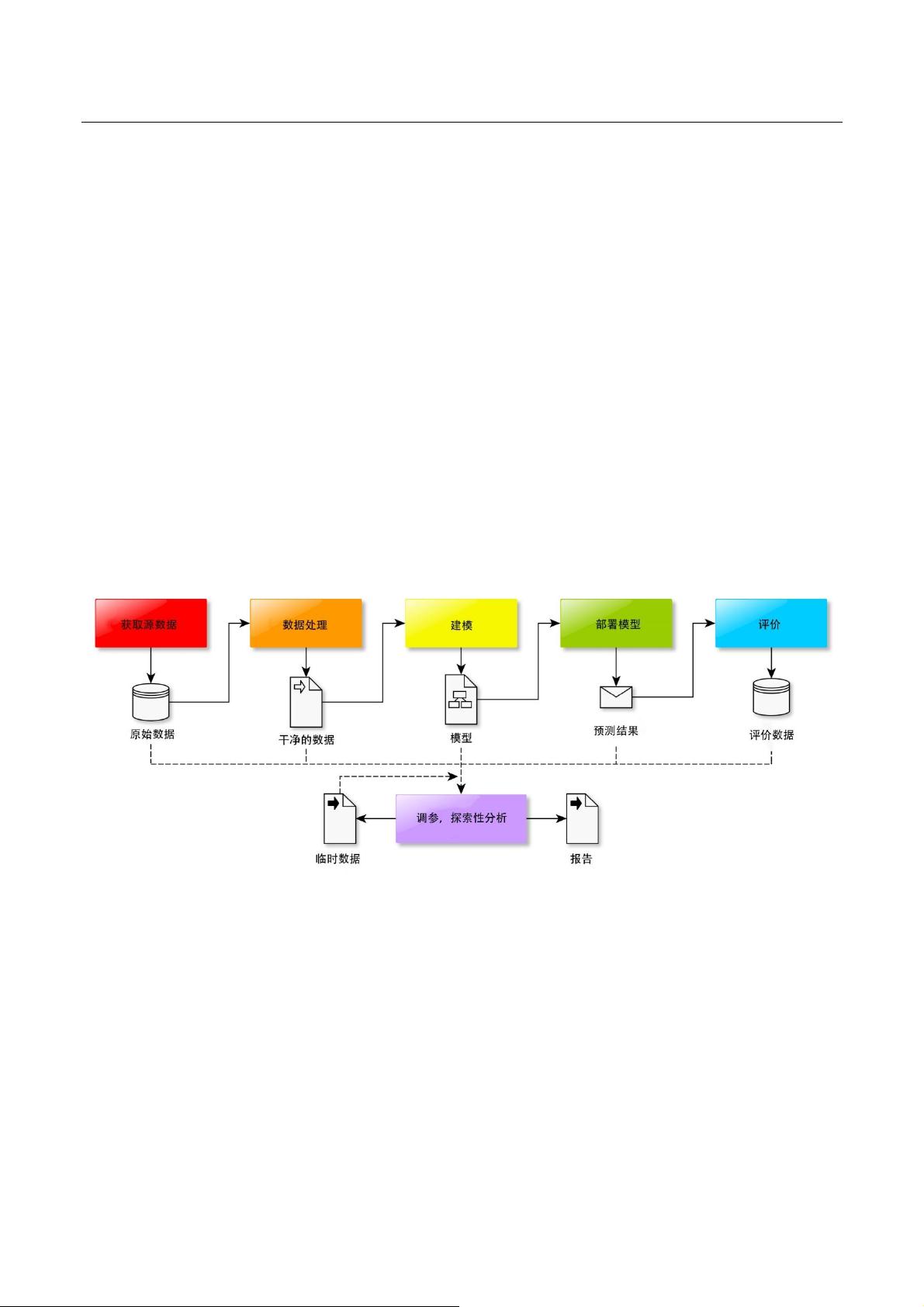
下图展示了一般数据数据分析问题的工作流程。
图 2 一般数据分析问题工作流程
三、使用语言和库的介绍
我们使用 Python 3 语言来进行本次项目的处理,并且使用数据科学处理库 numpy 与 scipy,具有数据处理
和分析功能的 pandas 库,可视化库 matplotlib 与 seaborn,机器学习算法库 Scikit-learn。
作为专门面向机器学习的 Python 开源框架,Scikit-learn 可以在一定范围内为开发者提供非常好的帮助。
它内部实现了各种各样成熟的算法,容易安装和使用,样例丰富,而且教程和文档也非常详细。
Scikit-learn 的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
下面是对 Scikit-learn 的基本功能的简介:
剩余18页未读,继续阅读
2023-10-09 上传
2024-09-18 上传
2023-12-23 上传
2021-06-10 上传
2024-11-06 上传
2024-09-27 上传

MurcielagoS
- 粉丝: 20
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







