Windows 10上Spark 2.3.0开发环境搭建指南
需积分: 12 15 浏览量
更新于2024-07-18
收藏 3.27MB DOCX 举报
本文档详细介绍了如何在Windows 10环境中搭建Spark开发环境,特别关注于非Cygwin和非虚拟机方式,适合64位系统且使用x86处理器的用户。以下步骤将指导你完成整个过程:
1. **安装基础环境**:
- 首先,确保你的系统是Windows 10家庭版64位,且CPU为x86架构。
- 安装JDK 1.8.0_171,将其安装到D:\setupedsoft\Java目录下,并配置JAVA_HOME环境变量指向该路径。还需要设置Path环境变量,包含:%JAVA_HOME%\bin和%JAVA_HOME%\jre\bin,以便系统能找到Java执行文件。
2. **Spark和Scala安装**:
- 下载Spark 2.3.0版本,可以从官方或提供的链接(<https://pan.baidu.com/s/1fdpHNo4nzeF44N2eHR_dXQ> 提取码:ftwr)获取。
- 将Spark解压到D:\setupedsoft\spark-2.3.0-bin-hadoop2.7目录,Spark与Hadoop版本需匹配。
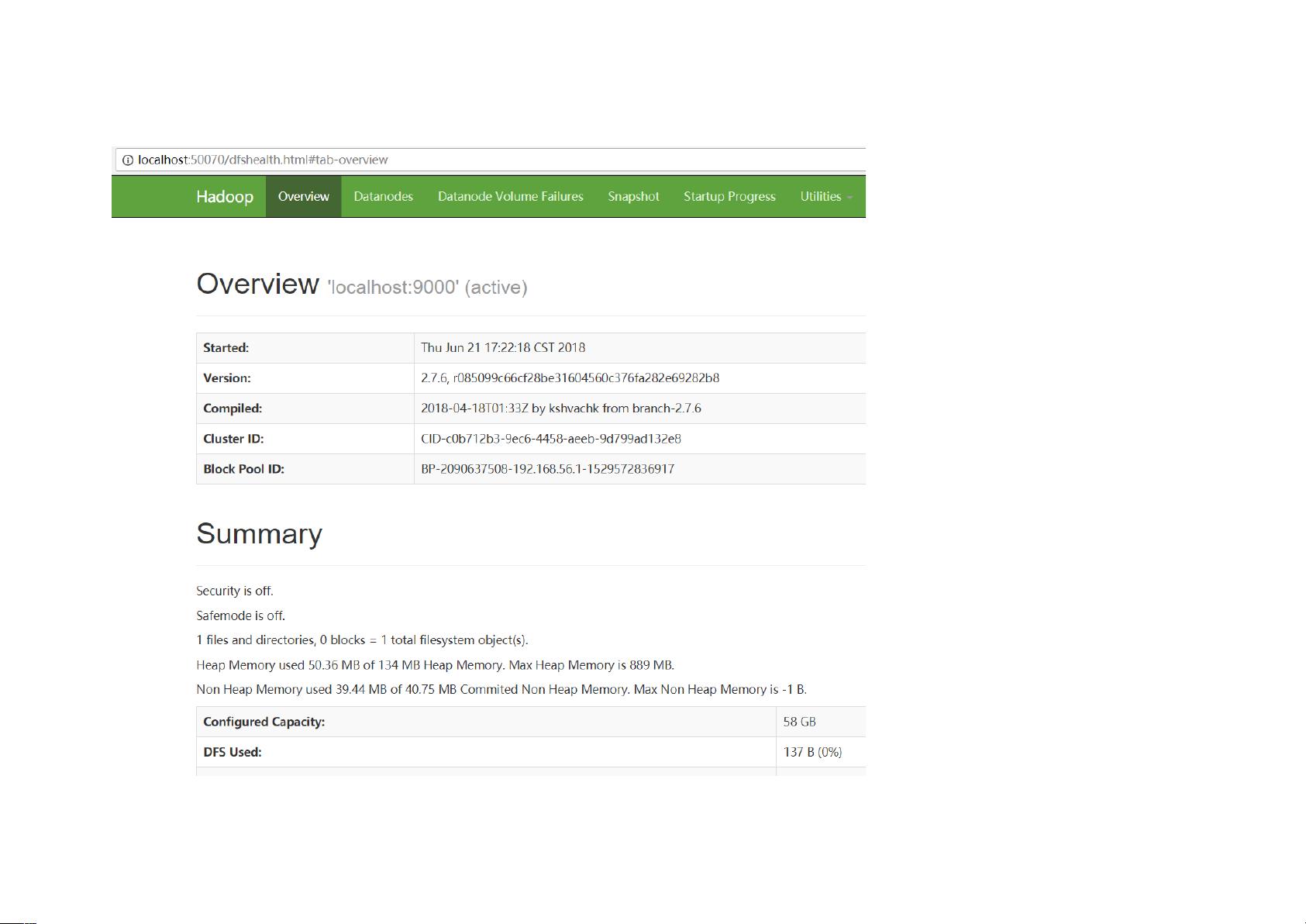
3. **Hadoop安装**:
- 从Apache官网下载Hadoop 2.7.6,解压到D:\setupedsoft\hadoop-2.7.6。
- 设置HADOOP_HOME环境变量指向Hadoop安装目录。
- 在Path环境变量中添加%HADOOP_HOME%\bin,确保Hadoop命令行工具可用。
- 使用特定工具(密码:dc63)来优化Hadoop在Windows上的运行,替换原有bin和etc目录。
4. **数据存储目录**:
- 创建Hadoop数据存储目录,如D:/datafile/hadoop-2.7.6/workplace,其中包含temp、data和name子文件夹。
5. **配置Hadoop**:
- 打开D:\setupedsoft\hadoop-2.7.6\etc\hadoop\core配置文件进行必要的修改,以适应本地环境。
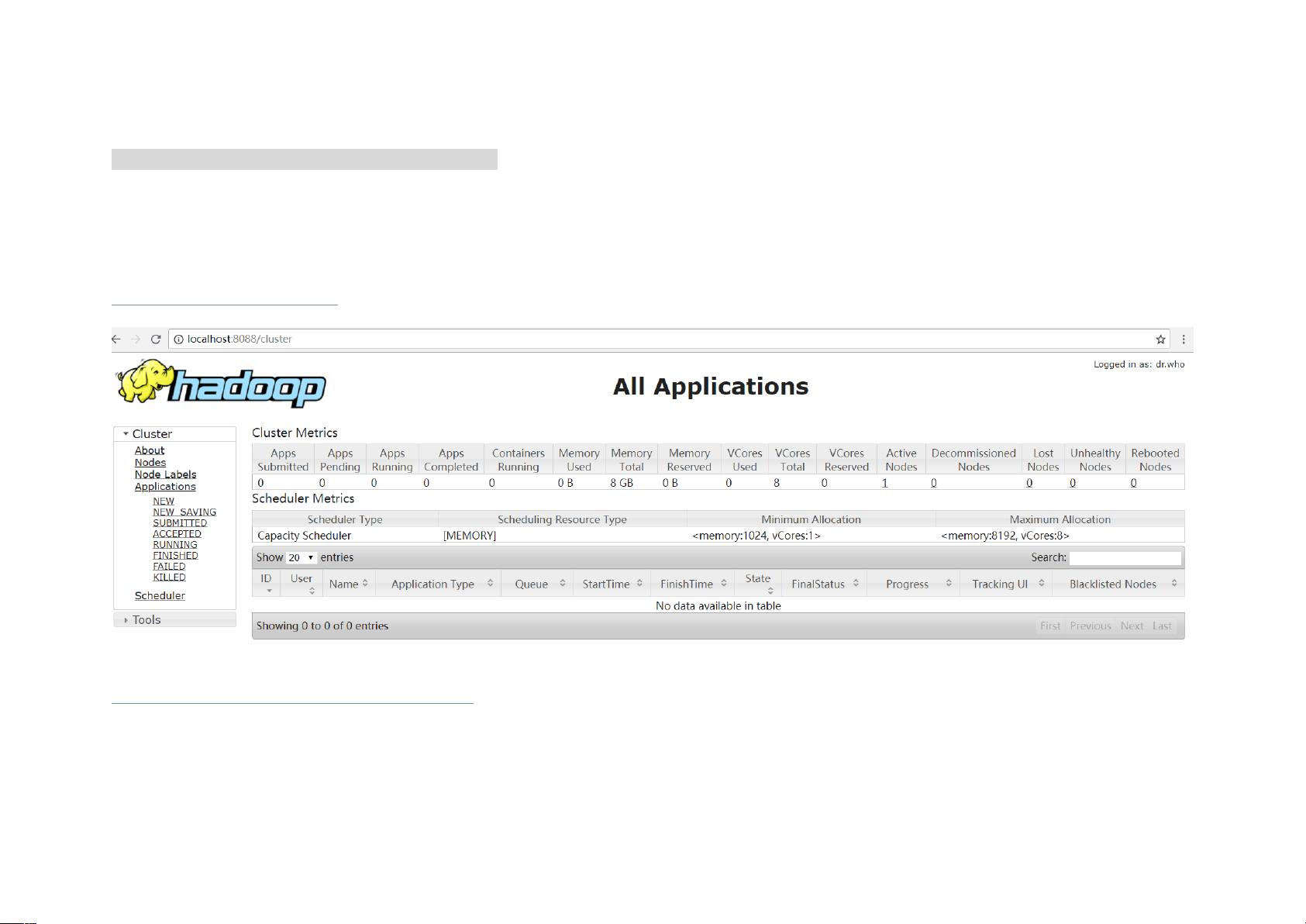
6. **IDE集成**:
- 推荐使用IntelliJ IDEA 2018.1.4作为开发IDE,安装完成后可以在项目中集成Spark框架,并可能需要手动添加依赖的JAR包,因为Spark框架可能需要额外的库支持。
在进行这些步骤时,请确保每一步都按照文档指示操作,特别是在环境变量的设置和配置文件的修改上,以保证Spark能够正确地与Hadoop协同工作。遇到问题时,可以根据文档中的提示或者进一步查阅相关技术文档进行解决。此外,由于Spark版本和Hadoop版本之间的兼容性很重要,务必确认两者版本的一致性。

2018-06-22 上传
2016-08-18 上传
2021-01-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-12 上传

lookup123
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- java毕业设计——java聊天室系统的设计与实现(论文+答辩PPT+源代码+数据库).zip
- versioning-benchmark
- Max-Movies
- 易语言-易语言分割文本源码(无分隔符)
- 电子商务React本地的
- geckodriver-v0.27.0-macos.tar.gz
- ParticleSwarmOptimization:PSO的实现,尝试找到函数f(x,y)= e ^(-x ^ 2--y ^ 2)* sin(x)的最小值,其中x和y在[-2,2]范围内
- portfolio-templete-using-bootstrap
- MSN首页的精美图片切换完整打包
- Discord-Levels-Bot:现代而干净的Discord Level机器人。 包括排行榜,统计菜单,可自定义的配置等!
- ApacheIgniteWithSpringData:Apache Ignite是一个专注于内存的分布式数据库和缓存平台。 该存储库旨在查看和观察Spring Data与Apache Ignite集成的用法
- 汇编语言+8259中断实验+proteus仿真
- deno-study:面额研究
- item-list
- DailyAlgorithm:每日一道算法练练手(此项目暂停更新)
- E5 2651 MACOS10.15 EFI.zip
