Apache Flink的挑战与机遇:构建实时数据基础设施
需积分: 5 160 浏览量
更新于2024-07-17
收藏 33.67MB PDF 举报
"FlinkForwardChina2018ChallengesandOpportunitiesofApacheFlinkEcosystem.pdf"
本文档主要探讨了Apache Flink生态系统在2018年面临的挑战和机遇,以及它在云计算领域的应用。Apache Flink作为一个高度先进的开源流处理引擎,已经在实时数据基础设施、商业智能、人工智能和大数据基础设施等多个领域展现出其潜力。
首先,Flink的核心优势在于其强大的流处理能力,能够实现实时数据处理,提供高吞吐量和低延迟。它支持事件时间处理,确保数据处理的精确性和一致性,这对于实时分析和决策至关重要。此外,Flink还提供了Table API和Flink ML库,使得用户可以方便地进行批处理和机器学习任务。
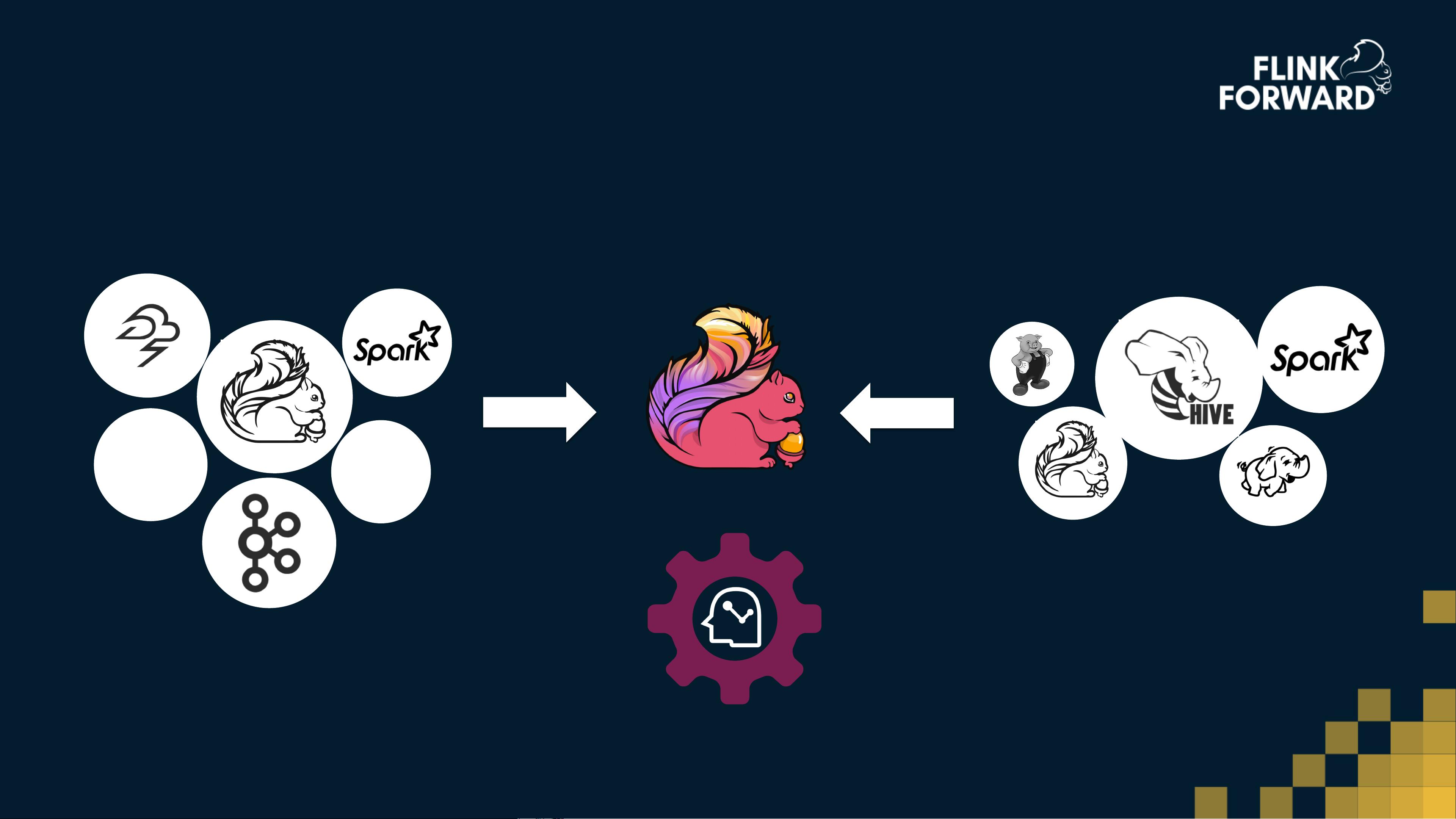
然而,随着大数据技术的发展,Flink也面临着一些挑战。例如,如何与现有的大数据生态系统如Hadoop YARN更好地集成,以实现资源管理和调度的优化。同时,Flink需要与其他消息队列系统(如Apache Kafka)协同工作,以确保数据的高效传输和可靠存储。此外,如何在容器化管理环境中,如Kubernetes,实现Flink作业的部署和扩展也是一个重要的议题。
文档中提到了Facebook如何利用Flink构建高性能平台,处理社交图数据存储。这表明Flink在处理大规模复杂数据结构方面的能力得到了实际应用。同时,Flink在人工智能领域的应用,如AI处理和增强用户体验,也显示出其在智能计算中的潜力。
Apache SAMOA是一个多框架的分布式机器学习库,它可以与Flink等流处理系统结合,为实时机器学习提供了可能。而Samza、Apex等其他流处理框架的存在,意味着Flink需要不断优化和创新,以保持在市场上的竞争优势。
Apache Flink在2018年的挑战主要集中在生态系统整合、性能优化和适应新的计算模式上。尽管存在这些挑战,但Flink的广泛应用和持续发展表明,它有可能成为统一的大数据智能计算引擎。随着云计算和大数据技术的持续进步,Flink的未来充满了机遇,同时也需要面对并解决更多的技术和市场挑战。
ၞᦇᓒක
samza
Apex
ಢᦇᓒක
Apache Flink
ᕹӞጱහഝ
ฬᚆᦇᓒක
$,ᦇᓒක
%XLOG,QWHOOLJHQW%LJ'DWD3ODWIRUPZLWK$SDFKH)OLQN
剩余24页未读,继续阅读
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2019-08-29 上传
2021-10-05 上传
2019-08-29 上传
2019-08-29 上传

weixin_38743481
- 粉丝: 696
- 资源: 4万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
