环形缓冲区原理与实现:通信编程中的关键数据结构
需积分: 45 116 浏览量
更新于2024-09-13
收藏 121KB PDF 举报
环形缓冲区是一种在通信程序中广泛应用的数据结构,它实现了先进先出(First In First Out, FIFO)的存储方式,并且支持循环访问,常用于在多个进程或线程间共享数据。其核心原理是通过两个指针——读指针(read pointer)和写指针(write pointer)来管理缓冲区中的数据。
1. 实现原理
- 环形缓冲区的基本构造包含固定大小的存储单元,通常是数组形式。读指针始终指向下一个待读取的位置,而写指针则表示下一次写入的位置。当写指针追上读指针时,即表示缓冲区满,此时需要进行溢出处理,即将数据移到缓冲区的起始位置,形成循环。
- 单一读写用户情况下,可以通过简单的指针更新操作来完成数据的进出,无需额外的互斥控制。然而,在多线程或多进程环境下,由于并发访问,必须确保对缓冲区的访问是原子性的,以防止数据混乱。这就需要引入锁或其他同步机制来保证操作的顺序执行。
2. 示例与实现
- 在代码实现中,如`ringbuf.c`所示,定义了三个变量:`input`用于跟踪当前放入的位置,`get`表示当前取出的位置,`n`记录缓冲区中的元素数量。`addring`函数用于计算有效地址,当到达缓冲区尾部时,返回头位置以实现循环。
- `get`函数负责从缓冲区中取出元素,首先检查是否有数据可用,若有则更新`get`指针并减少元素数量,最后返回对应位置的数据;若无数据,则输出错误消息并返回0.0。
- `put`函数用于向缓冲区添加元素,首先检查缓冲区是否已满,如果未满,则将新元素存入指定位置,同时更新`input`指针。若缓冲区已满,需要先移动读指针,腾出空间再插入新元素。
环形缓冲区的优势在于它简化了并发环境下的数据同步问题,减少了锁的使用,提高了程序的并发性能。然而,它的缺点是大小固定,一旦预设过大可能导致浪费,过小又可能导致频繁的溢出。因此,在实际应用中,需要根据具体需求来调整环形缓冲区的大小。
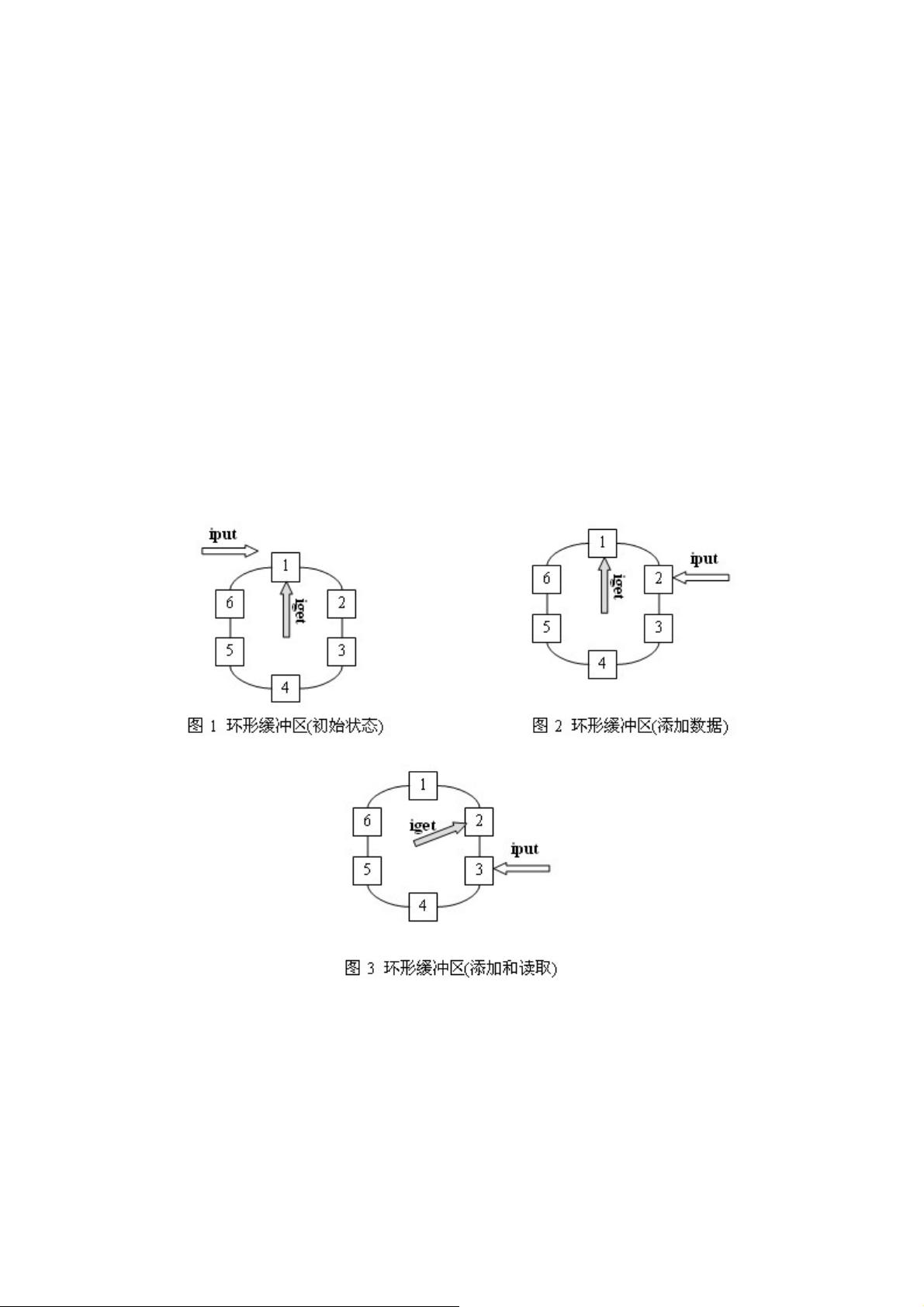
在通信程序中,经常使用环形缓冲区作为数据结构来存放通信中发送和接收的数据。环形缓冲区是一个先
进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
1、环形缓冲区的实现原理
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲
区中可写的缓冲区。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。在通常情况下,环形
缓冲区的读用户仅仅会影响读指针,而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,
那么不需要添加互斥保护机制就可以保证数据的正确性。如果有多个读写用户访问环形缓冲区,那么必须
添加互斥保护机制来确保多个用户互斥访问环形缓冲区。
图 1、图 2 和图 3 是一个环形缓冲区的运行示意图。图 1 是环形缓冲区的初始状态,可以看到读指针和写
指针都指向第一个缓冲区处;图 2 是向环形缓冲区中添加了一个数据后的情况,可以看到写指针已经移动
到数据块 2 的位置,而读指针没有移动;图 3 是环形缓冲区进行了读取和添加后的状态,可以看到环形缓
冲区中已经添加了两个数据,已经读取了一个数据。
个数据。
2、实例:环形缓冲区的实现
环形缓冲区是数据通信程序中使用最为广泛的数据结构之一,下面的代码,实现了一个环形缓冲区:
/*ringbuf .c*/
#include<stdio. h>
下载后可阅读完整内容,剩余7页未读,立即下载
1871 浏览量
330 浏览量
456 浏览量
点击了解资源详情
2831 浏览量
215 浏览量
5727 浏览量

oypl
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Gooper1 Data Pack:新的 G1DP 存储库。 去贡献!-开源
- iOS Apprentice v7.0 (iOS12 & Swift4.2 & Xc.zip
- PersonalPage:我的NextJS个人开发人员页面
- CS300P07
- AppAuth-JS:JavaScript客户端SDK,用于与OAuth 2.0和OpenID Connect提供程序进行通信
- js和CSS3炫酷圆形导航菜单插件
- 裂纹检测:使用计算机视觉工具箱进行裂纹检测-matlab开发
- 开源软路由OPENWRT2020.9.8原版VMWARE固件
- Onboard-SDK:DJI Onboard SDK官方资料库
- projetoFinal-ips-2-ano
- chips_thermal_face_dataset:芯片热敏面数据集是一个大规模的热敏面数据集(来自3个不同大洲的1200幅男性和女性图像,年龄在18-23岁之间)。 该数据集将可供全世界的研究人员使用最新的深度学习方法创建准确的热面部分类和热面部识别系统
- pamansayurdev.github.io:网站paman sayur
- MO_Ring_PSO_SCD:它是用于多模态多目标优化的多目标 PSO-matlab开发
- resynthesizer:用于纹理合成的gimp插件套件
- NavigationDrawer:这是一个示例项目,用于演示如何制作导航抽屉。此外,在这个项目中,我添加了材料设计,因此对于想要实现材料设计、工具栏等的人也有帮助
- hacker-news-clone
