Kafka与RabbitMQ对比:分布式消息系统解析
43 浏览量
更新于2024-08-28
收藏 613KB PDF 举报
"Kafka的初步认识"
Kafka是一种分布式、基于分区和多副本的消息系统,最初由LinkedIn开发,现在是Apache软件基金会的项目。它利用ZooKeeper进行协调,确保了高可用性和容错性。Kafka的核心概念是生产者、消费者和主题。生产者负责发布消息到主题,而消费者则从主题中消费这些消息。Kafka的设计目标是处理大规模的实时数据流,因此它的吞吐量非常高。
消息系统,如Kafka,解决了传统应用程序之间直接通信导致的高耦合问题。通过将消息发送到消息系统,即使接收方暂时不可用,业务流程也能正常运行。JMS(Java消息服务)是Java平台上的一种标准,用于与消息中间件交互,实现应用程序之间的异步通信。JMS提供了两种消息模型:点对点(Queue)和发布/订阅(Topic)。
点对点消息系统采用队列作为中介,每个消息只能被一个消费者消费,适合一对一的处理场景,例如订单处理系统。而在发布/订阅模式中,消息发布到主题,多个订阅者可以同时接收和处理同一主题的消息,适用于一对多的广播场景,比如新闻频道订阅。
相比其他消息队列系统,如RabbitMQ,Kafka在设计时更注重高性能和大数据处理。RabbitMQ遵循AMQP协议,强调消息的可靠性传递,支持事务,但吞吐量相对较低,适合需要高可靠性的应用。而Kafka的高吞吐量和本地磁盘批量操作使其在处理大量实时数据流时表现出色,尤其适合大数据分析和流处理场景。
Kafka的另一个特点是其可扩展性,可以通过增加更多节点轻松扩展集群,以处理更大的负载。此外,Kafka还支持消息保留策略,允许用户设置消息的生命周期,从而平衡存储和历史数据检索的需求。
总结来说,Kafka是一款强大的分布式消息系统,专为大规模实时数据处理而设计,适合需要高吞吐量和低延迟的场景。通过与ZooKeeper集成,它提供了高可用性和容错能力,而其与JMS等消息模型的兼容性则增强了其在各种应用场景下的灵活性。
Kafka的初步认识的初步认识
一、 前言
什么是消息系统?
早期两个应用程序间进行消息传递需要保证两个应用程序同时在线,并且耦合度很高。为了解决应用程序不在线的情况下业务
正常运转,就产生了消息系统,消费发送者(生产者)将消息发送至消息系统,消息接受者(消费者)从消息系统中获取消
息。
提到消息系统,不得不说一下JMS即Java消息服务(Java Message Service)应用程序接口。是一个Java平台中关于面向消
息中间件的API。用于在两个应用程序之间或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的
API。
通常消息传递有两种类型的消息模式可用一种是点对点queue队列模式(p2p),另一种是topic发布-订阅模式(public-
subscribe)。
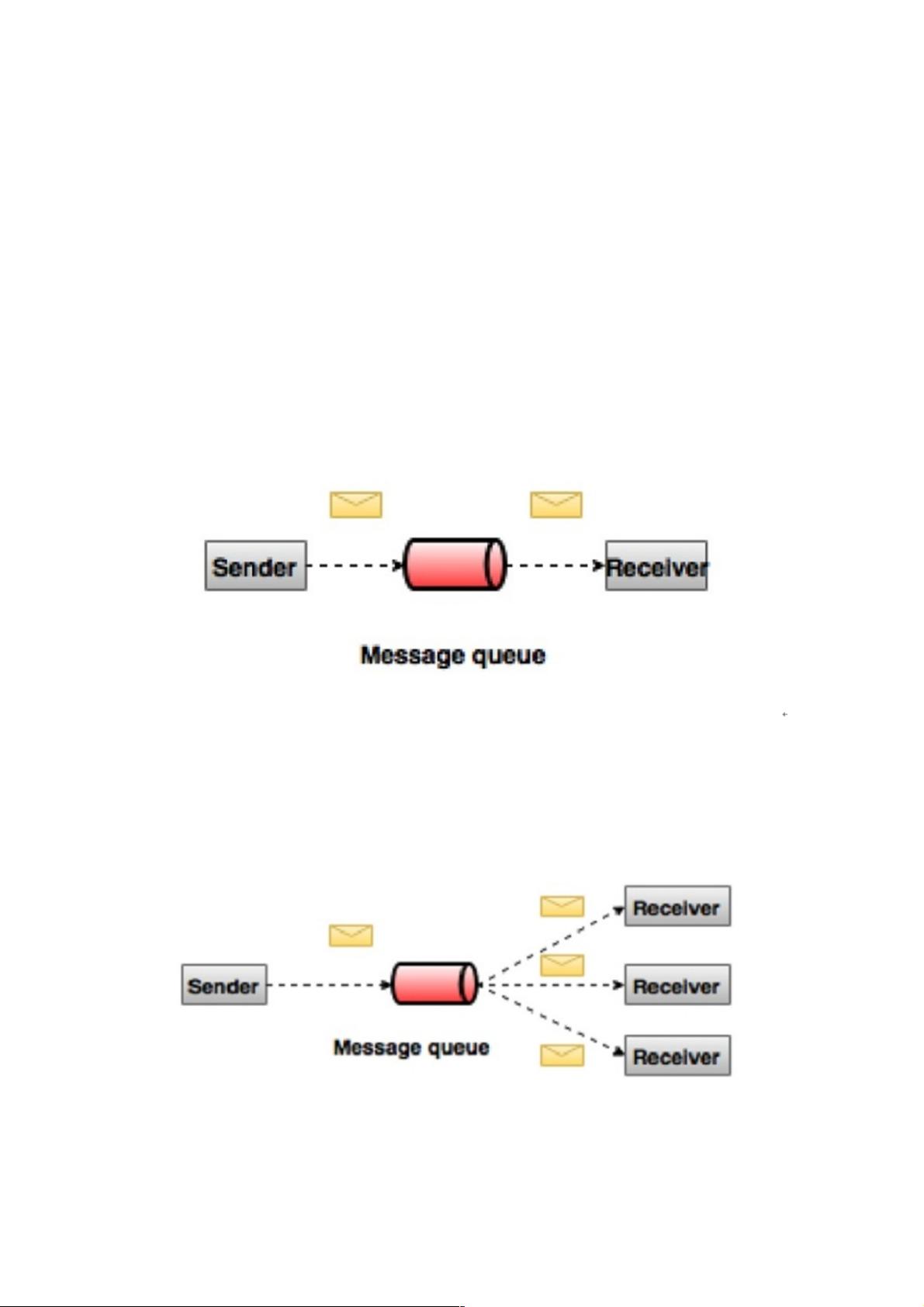
点对点消息系统
在点对点系统中,消息被保留在队列中。 一个或多个消费者可以消耗队列中的消息,但是特定消息只能由最多一个消费者消
费。一旦消费者读取队列中的消息,它就从该队列中消失。该系统的典型示例是订单处理系统,其中每个订单将由一个订单处
理器处理,但多个订单处理器也可以同时工作。下图描述了结构。
发布 - 订阅消息系统
在发布-订阅系统中,消息被保留在主题中。与点对点系统不同,消费者可以订阅一个或多个主题并使用该主题中的所有消
息。 在发布 - 订阅系统中,消息生产者称为发布者,消息使用者称为订阅者。一个现实生活的例子是Dish电视,它发布不同
的渠道,如运动,电影,音乐等,任何人都可以订阅自己的频道集,并获得他们订阅的频道时可用。
MQ消息队列对比
下面针对RabbitMQ与kafka进行对比
应用场景上
RabbitMQ:遵循AMQP(Advanced Message Queuing Protocol)协议,由内在高并发的erlanng语言开发,用在实时的对可靠
下载后可阅读完整内容,剩余6页未读,立即下载
5017 浏览量
2214 浏览量
633 浏览量
106 浏览量
289 浏览量
382 浏览量
点击了解资源详情
117 浏览量
1235 浏览量

weixin_38750644
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 传智播客教学:苏坤主讲骑士飞行棋C#开发教程
- Andy Harris著作:HTML5傻瓜书快速参考指南
- document-change-sketchplugin:处理文档变更的SketchJS示例插件
- 数字信号处理(DSP)原理与应用全面教学
- 户外线路跟踪利器:基于Google Map的Android线路记录器
- Swift通过CocoaPods动态生成直方图图表教程
- 软件学院实验:复数计算器的设计与实现
- STM32控制ENC28j60网络模块完整项目资料及程序
- Linux环境编译Java项目含第三方库包教程
- Leaflet.PolylineMeasure: 实现地理路径长度测量的JavaScript插件
- 使用Sketch-Predefined-Pages插件优化设计工作流程
- 淘淘商城前端开发资源包:JS、CSS代码解压即用
- iPhoneAxure组件资源库:免费下载iPhone主题设计
- 2440开发板硬件原理图详细解读
- 探索Swift动画开发:SHSnowflakes雪花飘落效果
- 施耐德编程软件:特维德PLC编辑器
