




MapReduce工作流与JobControl实践
 已收录资源合集
已收录资源合集
需积分: 0 86 浏览量
更新于2024-08-03
收藏 154KB PDF 举报
"MapReduce工作流介绍"
MapReduce是Hadoop框架中的核心组件,用于处理和存储大规模数据的分布式计算。MapReduce的工作流程是通过一系列相互依赖的作业(Job)来完成复杂的计算任务。这些作业按照特定的依赖关系顺序执行,形成一个有向无环图(DAG)。在大数据处理中,MapReduce扮演着至关重要的角色,它能够处理PB级别的数据,确保数据的高效处理和分析。
MapReduce的工作流程主要分为以下几个阶段:
1. **Map阶段**:这是数据处理的初始阶段,输入数据被分割成多个小块(Split),然后分配给多个Map任务进行处理。每个Map任务负责处理一部分数据,对输入数据进行映射操作,生成键值对的形式作为中间结果。
2. **Shuffle阶段**:Map任务产生的中间结果会被分区并排序,这个阶段通常包含分区(Partitioning)、排序(Sorting)和归并(Combining)三个步骤。分区是根据键的哈希值将数据分配到不同的Reducer,排序保证了同一键的所有值在一起,而归并则是为了减少网络传输的数据量。
3. **Reduce阶段**:Reducer任务接收来自多个Map任务的中间结果,对相同键的值进行聚合操作,生成最终的结果。Reducer数量可以自定义,以平衡计算负载和内存使用。
4. **Output阶段**:Reducer生成的最终结果会被写入到文件系统中,通常是HDFS,供后续使用或进一步处理。
在实际应用中,经常需要将多个MapReduce作业串联起来,形成一个工作流。Hadoop提供了一个名为`JobControl`的类,用于管理和控制这种作业流。`ControlledJob`类可以将普通的Job包装成受控作业,并设置作业之间的依赖关系。当所有依赖的作业完成时,`JobControl`才会启动下一个作业。这样,整个工作流就能按照预设的顺序执行,保证了作业的正确性。
例如,在MapReduce的Join操作中,可能会有连续的两个作业,第一个作业可能是一个未排序的数据处理,其输出是第二个作业的输入。第二个作业则需要对前一个作业的输出进行排序,以便进行Reduce-side join。在这种情况下,`ControlledJob`和`JobControl`就可以帮助我们构建并执行这样的工作流。
MapReduce工作流允许开发者将复杂的大数据处理任务分解为一系列相互关联的小任务,通过Hadoop的调度机制,保证了任务的有序执行和数据处理的正确性。这种设计使得MapReduce非常适合处理大规模、分布式的数据集,尤其在大数据分析和挖掘领域有着广泛的应用。
@TOC
本文介绍MapReduce 工作流。
本文前提:hadoop环境可用。
吧
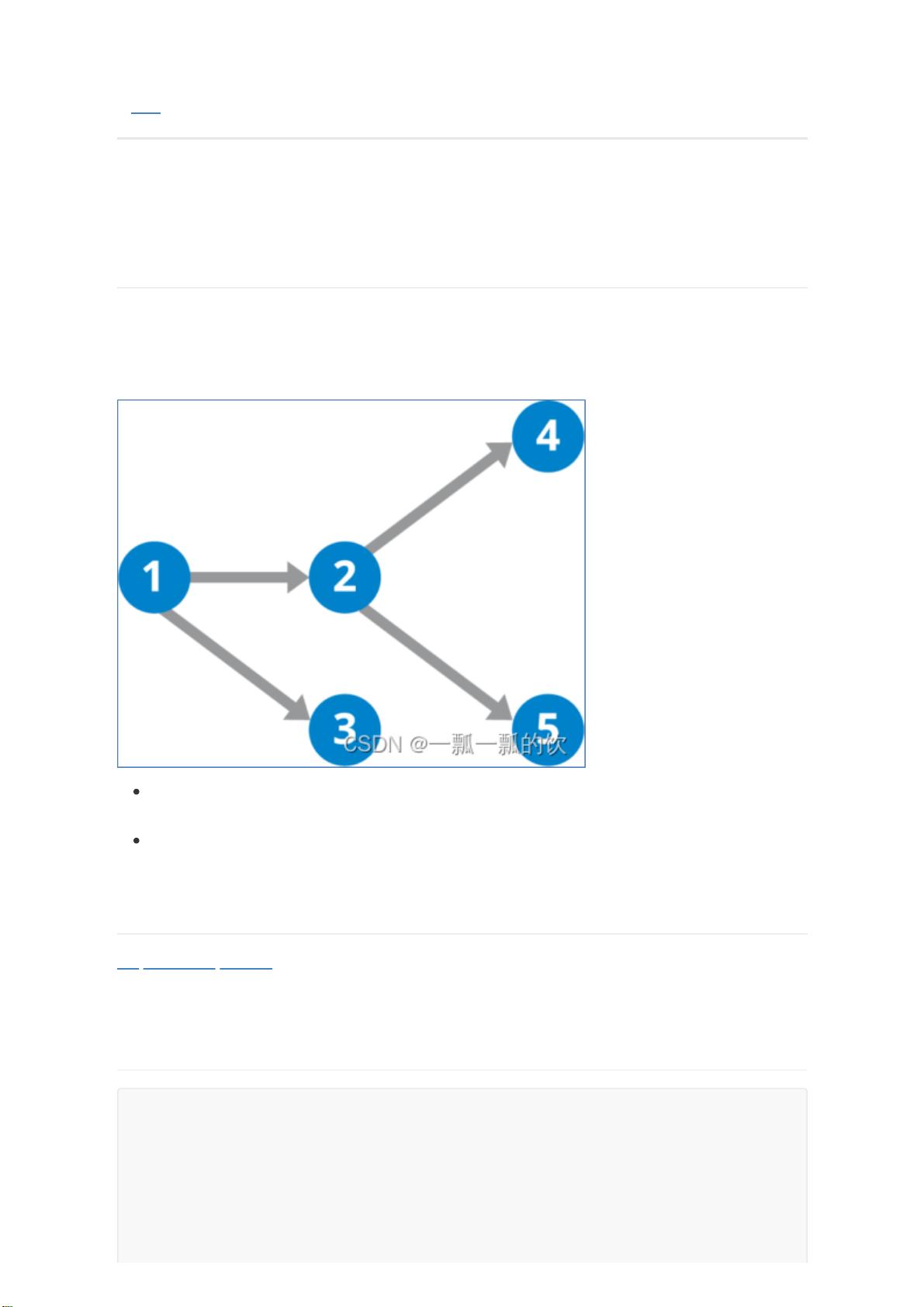
一、MapReduce 工作流介绍
多个MR作业,先后依次执行来计算得出最终结果。这类作业类似于DAG的任务,各个作业之间有依赖关
系,比如说,这一个作业的输入,依赖上一个作业的输出等等。
一般实际的业务场景中,可能使用定时调度工具进行调度,但本示例仅仅说明mapreduce自身也可以做
到。
JobControl类:工作流job控制器,一次可以提交、管理多个job。JobControl类实现了线程
Runnable接口。需要实例化一个线程来让它启动。
ControlledJob类:可以将普通作业包装成受控作业。并且支持设置依赖关系。Hadoop会根据依赖
的关系,先后执行job任务,每个任务的运行都是独立的。
二、使用示例
MapReduce的join操作
将上述的Reduce side join 的例子连续起来运行,即第一步未排序输出,第二步针对上一步的输出进行
排序。
1、实现
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
下载后可阅读完整内容,剩余3页未读,立即下载
2021-08-25 上传
384 浏览量
171 浏览量
183 浏览量
2025-01-07 上传
2024-11-01 上传
2024-12-29 上传
2024-12-20 上传
2025-02-19 上传

一瓢一瓢的饮alanchanchn
- 粉丝: 9300
 我的内容管理
展开
我的内容管理
展开







最新资源
- SpringMVC与jQuery实现图片异步上传技巧
- 自定义属性的IconTextView组件实现与应用
- Minix3操作系统源代码分析与探索
- Cocos2d-x游戏源码分享:入门级'愤怒的小鸟'与'一个都不能死'
- FasTrix开源工具:Shadowrun角色扮演游戏支持
- Linux内核组件深度解析全集
- 逆向工程工具:将jar反编译为Java源码
- 易语言开发的仿360桌面源码包
- LCPkg:Windows C/C++项目依赖管理的高效CLI工具
- 从相机和本地获取Bitmap图片资源及权限处理
- C#数据库学生信息管理系统源代码解析
- 掌握WinCE6.0下SQLCE数据库的增删改查操作
- 微信小程序组件化方案:合并子组件实践指南
- 开源机器人:Tibia游戏的自动化伴侣
- NTLEA软件:轻松解决游戏及软件乱码问题
- C#超市管理系统完整源码解析与设计






















