广州大学数据结构历年题型解析与非代码技巧
需积分: 50 43 浏览量
更新于2024-07-09
4
收藏 5.5MB DOCX 举报
广州大学914数据结构考试中常见的非代码题型主要涵盖了数据结构中的几个核心概念和算法。以下是针对这些题目进行的详细解析:
1. **最小生成树算法**:
- **Prim算法**:这是一种贪心算法,从一个顶点开始,每次选择与当前生成树相连的未加入边中权重最小的边,直到所有顶点都加入。另一种算法是**Kruskal算法**,它通过从小到大比较边的权重,依次加入边,形成无环子集,直到所有顶点连通。
2. **堆排序**:
- 堆排序利用完全二叉树特性,无需预先排序,而是直接构造一个最大堆或最小堆,然后将堆顶元素与末尾元素交换,调整堆后再重复此过程。
3. **排序二叉树**:
- 建立排序二叉树时,遵循左小根、右大根的原则,即每个节点的左孩子小于该节点,右孩子大于该节点。构建过程不需要预先排序,而是根据元素值直接插入。
4. **查找算法的性能评估**:
- 平均查找长度(ASL)计算方法:对于链式查找,ASL等于每一层的元素个数与层数的乘积之和除以元素总数。例如,对于序列10、20、40...,ASL = (1+2*2+3*3...)/n。
5. **哈夫曼编码**:
- 最短路径长度(WPL)计算的是每个结点的分支数乘以其对应的元素个数,用于构建最优的哈夫曼树。
6. **堆的判断与调整**:
- 提供的三个序列分别经过调整,判断是否为堆并构造完全二叉树,体现了堆的性质和操作。
7. **二叉排序树与平均查找长度**:
- 二叉排序树的构建和查找效率分析,以及计算ASL的实例。对于给定元素(46, 25, ...,70),构建二叉排序树并计算其ASL。
8. **图的表示和遍历**:
- 邻接矩阵、邻接表的表示,以及求解顶点度数。同时,展示了从特定顶点(A)出发的深度优先遍历和广度优先遍历序列。
9. **散列表**:
- 散列函数H(k)的应用,分析等概率下不同散列冲突处理策略(线性探查)对查找长度的影响。给出了两次不同的散列表分布和相应的平均查找长度。
以上知识点展示了数据结构课程中关于最小生成树、堆排序、排序二叉树、查找算法、图论、哈夫曼编码、二叉排序树以及散列表的典型问题和解决方案,有助于考生复习和准备相关的考试题目。
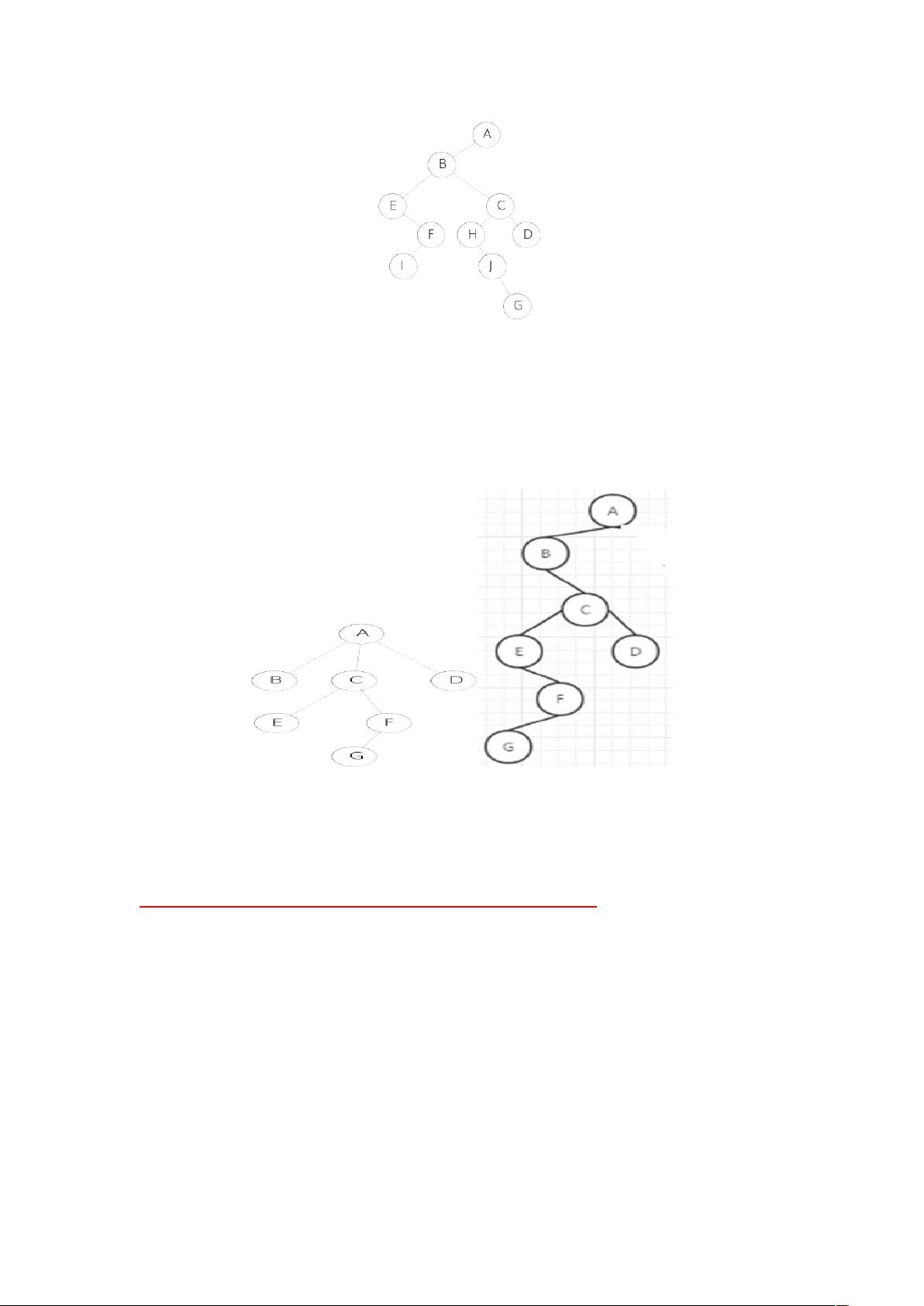
前序:ABEFI CHJGD
中序:EIF BHJGCD A
后序:IFE GJH DCBA
层序:ABECFHDIJG
图 2 对应的树为:
树只有先序后序列
先根序列:ABCEFGD
后根序列: BEG FCD A
也是二叉树的中序遍历 熟记 BEG FCD A
只有二叉树的中序等于树的后序 其他不等
层序序列:ABCDEFG
10. 有如下图所示的带权有向图 G,试回答以下问题。
(1) 给出 G 的一个拓扑序列
(2) 给出从顶点 1 到顶点 8 的最短路径
14 12 125 1257 12578 最后是 12578 思路是找该点出发 沿途的最短边 每一次都
对比
剩余33页未读,继续阅读
2023-08-08 上传
2023-08-12 上传
2023-10-15 上传
2023-08-12 上传
2023-06-08 上传
2024-12-11 上传
2023-06-01 上传


码农研究僧
- 粉丝: 27w+
- 资源: 47
 我的内容管理
展开
我的内容管理
展开







最新资源
- motif-mark:盒式外显子基序可视化
- android-group,java小项目源码,自动售货机软件源码java
- 5de970ee89108da0b7e19eafd4beaaad:应用程序 ID 11155
- dumi
- Machine-Learning-NCF-class:应用机器学习班
- Merge Balls-crx插件
- DOM-Document-Object-Model,java项目源码下载,java免签
- YOLO_V1
- empresa-presentacion-sencilla-1:监控摄像机系统公司,警报器等
- UP
- 利用紫金桥软件完成现场工艺流程图的绘制.zip
- 实现文字的整体变色效果
- test-sample-for-tutorial
- UofI_eyelink_file_analizers
- learning:只是用于学习新事物的小型一次性项目的存储库
- tarena,java获取网页源码,网上教学系统源码java
