Hadoop集群安装配置指南
需积分: 9 41 浏览量
更新于2024-08-05
收藏 658KB PDF 举报
"该资源是关于在Ubuntu 16.04服务器上安装配置Hadoop集群的详细步骤,适用于Linux环境,涉及大数据处理和集群搭建。"
在这篇文档中,作者详细介绍了如何在Linux系统(具体是Ubuntu 16.04)上安装配置Hadoop 3.0.3版本,这是一个广泛用于大数据处理的开源框架。以下是安装过程的关键步骤:
1. **下载软件**:首先,你需要下载Java Development Kit (JDK) 和 Hadoop的二进制包。在这个例子中,使用的JDK版本是`jdk-8u91-linux-x64.tar.gz`,而Hadoop的版本是`hadoop-3.0.3.tar.gz`。
2. **解压软件**:将下载的JDK和Hadoop压缩文件解压到`/opt`目录下。使用`tar`命令进行解压,并通过`-C`选项指定目标路径。
3. **创建符号链接**:为了方便使用,创建软链接到解压后的目录,例如`ln -s hadoop-3.0.3 hadoop`和`ln -s jdk1.8.0_91 jdk`。
4. **配置环境变量**:编辑用户环境变量文件,如`.bashrc`和`.profile`,设置`JAVA_HOME`, `CLASSPATH`, `HADOOP_HOME`, `HADOOP_USER_NAME`以及`PATH`。这使得系统可以识别和使用安装的JDK和Hadoop。
5. **复制配置模板**:对于Hadoop配置,需要复制`core-site.xml.template`到`core-site.xml`,并编辑它以定义文件系统的默认访问点,例如`<name>fs.defaultFS</name>`的值设为`hdfs://172.16.0.4:9000`。
6. **配置MapReduce**:同样地,复制`mapred-site.xml.template`到`mapred-site.xml`,并设置`mapreduce.framework.name`为`yarn`,以便使用YARN作为作业调度器。
7. **其他配置**:可能还需要配置`yarn-site.xml`和`hdfs-site.xml`来定义YARN的行为和HDFS的参数,但文档中并未详细给出这部分内容。
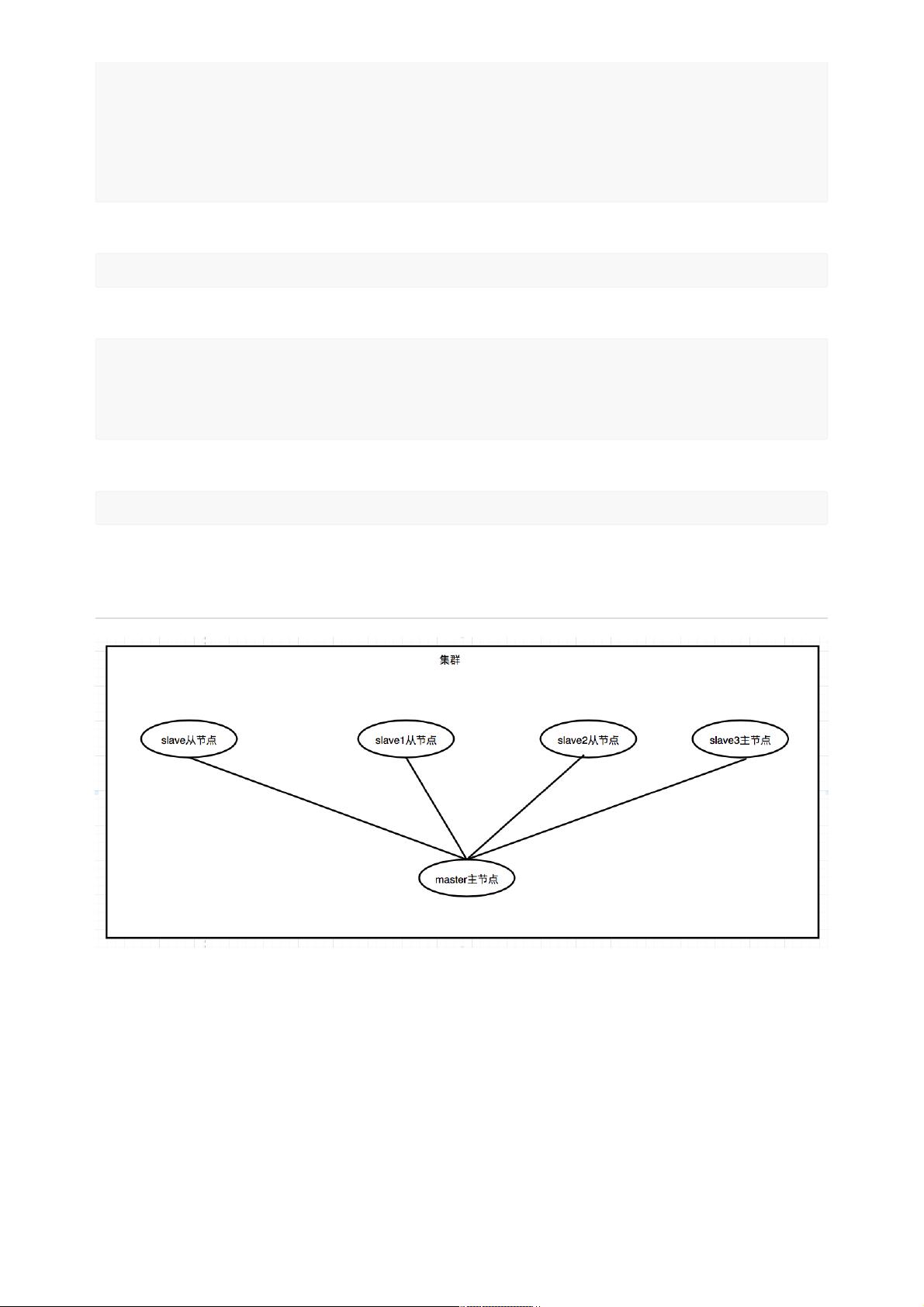
这个过程是Hadoop集群部署的基础,确保所有节点都经过相同的配置步骤,然后可以通过启动Hadoop守护进程(如NameNode、DataNode、ResourceManager和NodeManager)来启动集群。在多节点环境中,还需要配置Hadoop的分布式文件系统(HDFS)和资源管理(YARN),以及可能的网络设置,以实现节点间的通信。
在实际操作中,还需要考虑安全性(如设置权限和加密)、高可用性(如NameNode HA)、性能优化(如调整内存和CPU分配),以及监控和日志记录等细节。在生产环境中,通常会使用Ambari或类似的工具自动化这些过程,以简化管理和维护。
8. ץදhadoopᯈᗝկyarn-site.xml
ٖইӥғ
9. ࣁᵞᗭӾڠୌಁᒒᒒଫጱᵞᗭፓ୯
2.2 hadoopᵞᗭ
قړୗཛྷୗ҅Ԇᜓᅩᜓᅩ᮷ฎᜋړᐶ҅ࣁقړୗ᯾ᶎ҅տᦡᗝӻአಁᓕቘӧݶጱଘݣ
ຝ҅ᵞᗭᦡᗝ3ӻአಁhdfs 20001(UID) ᓕቘhdfsᵞᗭyarn 20002አಁᓕቘ yarnᵞᗭҁMapreduceᵞ
ᗭ҂mapred 20003 ᦕ୯ᑕଧᬩᤈጱᵞᗭ෭ப҅Ӥᶎ3ӻአಁق᮱୭ԅhadoopᕟ҅כᦤᵞᗭӾጱղ᮷
ฎӞᛘጱ҅ᵱᥝአಁጱUIDכ೮Ӟᛘ҅ᕟIDכ೮Ӟᛘ҅hadoop ᕟݩҁ20000҂.
զӥٖಅํᜓᅩ֢ӞᛘҔ
1. ٵᛗӷݣubuntuᦇᓒҁݢզฎᡦ҂
2. Ꮯכԏᳵᗑᕶฎ᭗ጱ҅ଚӬכᦤྯݣ᮷ᤰํssh๐
ᤰssh๐ۓե:
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
sudo vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>172.16.0.4</value>
</property>
hdfs dfs -mkdir /user/hdfs
剩余11页未读,继续阅读
231 浏览量
197 浏览量
720 浏览量
2021-11-23 上传
2023-12-20 上传
2021-11-23 上传
2020-02-08 上传
129 浏览量









