HBase架构解析:RegionServers、Master与Zookeeper的角色
76 浏览量
更新于2024-08-28
收藏 1.38MB PDF 举报
"深入理解HBase架构"
HBase是一款基于Google Bigtable理念设计的高扩展、高性能、分布式的NoSQL数据库,其设计目标是支持大规模数据的实时读写操作。HBase架构的核心特点是主从式架构,由三种类型的服务器组成:RegionServers、HBase Master和Zookeeper。
RegionServers是HBase数据服务的主体,它们负责实际的数据存储和检索。客户端在访问数据时,直接与RegionServers进行通信,执行读写操作。RegionServers根据RowKey(行键)范围将数据分布在整个集群中,确保数据的快速访问。每个RegionServer可以管理多个Region,Region的数量通常不超过1000个,以保持高效的服务能力。
Region的分配、表的创建(DDL)和其他管理操作由HBase Master处理。Master服务器是HBase的控制中心,它负责Region的生命周期管理,包括初始分配、迁移和负载均衡。当RegionServer出现故障或需要调整负载时,Master会监控Zookeeper中的信息,并进行必要的Region重新分配。
Hadoop DataNodes是HDFS(Hadoop Distributed File System)的组成部分,它们存储RegionServer管理的数据。所有HBase的数据都保存在HDFS的文件中。为了提高性能,RegionServer通常部署在同一台运行DataNode的机器上,实现数据局部性,减少网络延迟,提高数据读写速度。然而,当Region在RegionServer之间迁移时,数据可能暂时失去局部性,直到进行数据压实操作。
NameNode是HDFS的元数据管理器,它维护了构成文件的所有数据块的元数据信息,包括文件与数据块的映射关系,但不直接参与HBase的操作。
Zookeeper作为HBase的分布式协调者,它在整个集群中维护服务器状态的同步。Zookeeper集群通常由3至5台机器组成,保证高可用性和一致性。RegionServer和active HMaster通过心跳机制与Zookeeper保持连接,一旦某个组件发生故障,Zookeeper能够迅速检测并通知其他组件。
这些组件协同工作,确保HBase能够在大规模分布式环境中稳定运行,提供高效、可靠的数据存储和访问服务。HBase的这种架构设计使其特别适合处理PB级别的大规模数据,并能应对大数据实时查询的需求。
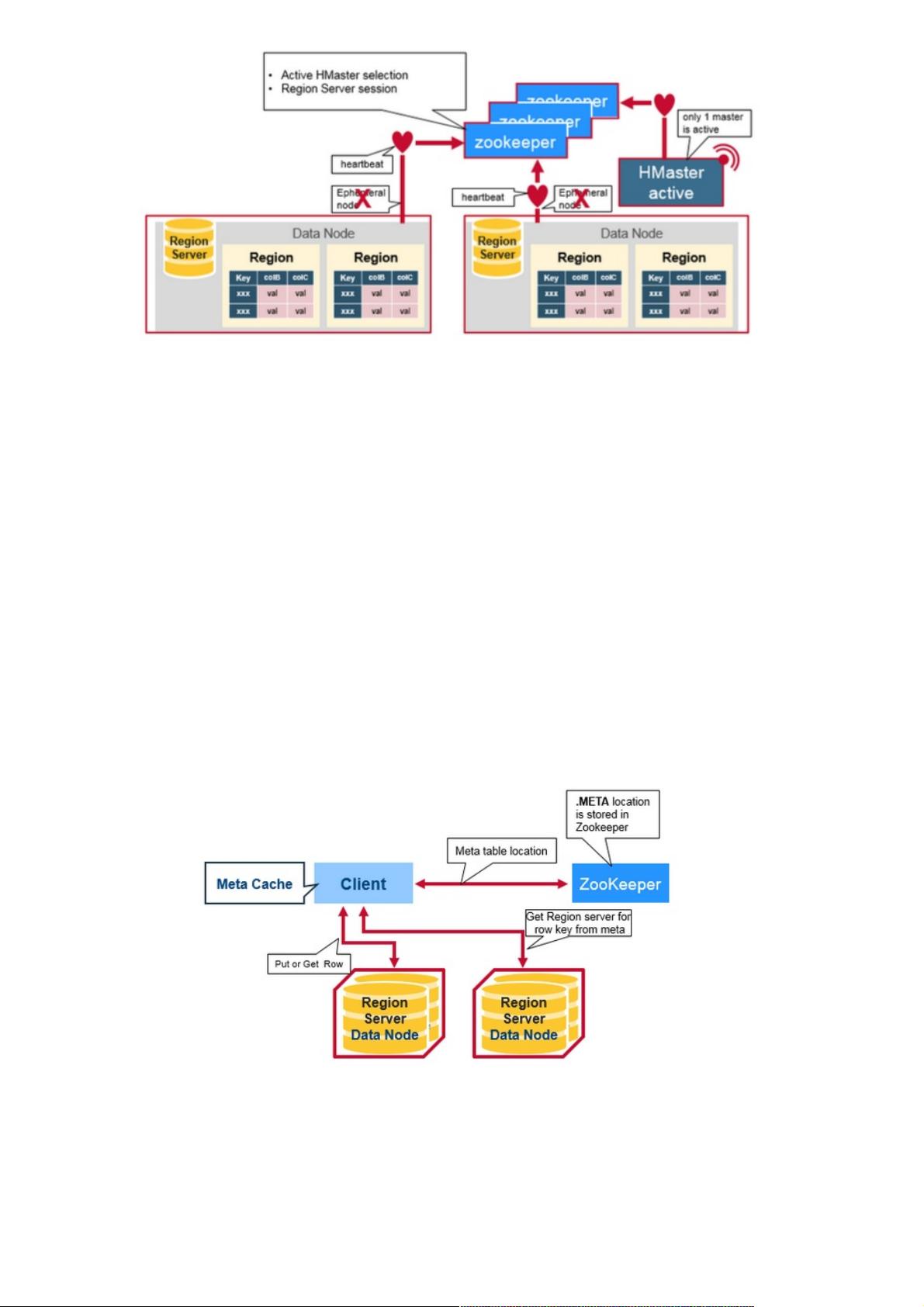
每个Region Server创建一个临时节点。HMaster监控这些节点以发现可用的region servers,并监控这些节点的服务器故障。
HMaster监控这些节点以发现可用的区域服务器,并监控这些节点的服务器故障。HMasters争夺创造一个短暂的节点。
Zookeeper确定第一个并使用它来确保只有一个主站处于活动状态。 活动HMaster将心跳发送到Zookeeper,非活动HMaster
将监听活动HMaster故障的通知。如果region server或者actice HMaster未能发送心跳信号,则会话过期并删除相应的临时节
点。Listeners的更新在收到节点删除的通知后。Active HMaster监听region servers,并在region servers出现故障时进行恢
复。Inactive HMaster监听active HMaster故障,并且如果active HMaster故障时,inactive HMaster编程active状态。
Base First Read or Write
HBase有一个叫做META的特殊的目录表,用于保存集群中regions的位置信息。Zookeeper存储着META表的位置。
以下是客户端第一次读取和写入HBase时发生的情况:
1.客户端从zookeeper中META Table的位置.
2.客户端查询.META。服务器获取客户端想要访问的并且是rowkey所相对应Region Server的信息。客户端会将META缓存带
本地。
3.从相应的Region Server获取行
在未来的读取操作过程中,客户端使用Meta Cache来检索META Table的位置和之前读取的Row Keys。随着时间的推移,不
再需要查询META table了,除非应为一个region转移而错过,那么它将重新查询并更新Meta Cache。
HBase Meta Table
1.META表是一个保存的了系统中所有region列表的HBase表。
2.META表就像一颗B—tree
3.METa的结构如下:
Key: region start key,region id
剩余11页未读,继续阅读
2018-11-11 上传
2019-04-18 上传
点击了解资源详情
2021-01-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38708461
- 粉丝: 5
- 资源: 993
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入了解Django框架:Python中的网站开发利器
- Spring Boot集成框架示例:深入理解与实践
- 52pojie.cn捷速OCR文字识别工具实用评测
- Unity实现动态水体涟漪效果教程
- Vue.js项目实践:饭否每日精选日历Web版开发记
- Bootbox:用Bootstrap实现JavaScript对话框新体验
- AlarStudios:Swift开发教程及资源分享
- 《火影忍者》主题新标签页壁纸:每日更新与自定义天气
- 海康视频H5player简易演示教程
- -roll20脚本开发指南:探索roll20-master包-
- Xfce ClassicLooks复古主题更新,统一Linux/FreeBSD外观
- 自建物理引擎学习刚体动力学模拟
- Python小波变换工具包pywt的使用与实例
- 批发网导航程序:自定义模板与分类标签
- 创建交互式钢琴键效果的JavaScript库
- AndroidSunat应用开发技术栈及推介会议
